


一直以來都對編譯器和解析器有著很大的興趣,也很清楚一個編譯器的概念和整體的框架,但是對於細節部分卻不是很了解。我們寫的程式原始碼其實就是一串字元序列,編譯器或解釋器可以直接理解並執行這個字元序列,這看起來實在是太奇妙了。本文會用Python實作一個簡單的解析器,用來解釋一種小的列表操作語言(類似python的list)。其實編譯器、解釋器並不神秘,只要對基本的理論理解之後,實作起來也比較簡單(當然,一個產品級的編譯器或解釋器還是很複雜的)。
這種列表語言支援的操作:
veca = [1, 2, 3] # 列表声明 vecb = [4, 5, 6] print 'veca:', veca # 打印字符串、列表,print expr+ print 'veca * 2:', veca * 2 # 列表与整数乘法 print 'veca + 2:', veca + 2 # 列表与整数加法 print 'veca + vecb:', veca + vecb # 列表加法 print 'veca + [11, 12]:', veca + [11, 12] print 'veca * vecb:', veca * vecb # 列表乘法 print 'veca:', veca print 'vecb:', vecb
對應輸出:
veca: [1, 2, 3] veca * 2: [2, 4, 6] veca + 2: [1, 2, 3, 2] veca + vecb: [1, 2, 3, 2, 4, 5, 6] veca + [11, 12]: [1, 2, 3, 2, 11, 12] veca * vecb: [4, 5, 6, 8, 10, 12, 12, 15, 18, 8, 10, 12] veca: [1, 2, 3, 2] vecb: [4, 5, 6]
編譯器和解釋器在處理輸入字元流時,基本上和人理解句子的方式是一致的。如:
I love you.
如果初學英語,首先需要知道各個單字的意思,然後分析各個單字的詞性,符合主-謂-賓的結構,這樣才能理解這句話的意思。這句話就是一個字元序列,依照詞法分割就得到了一個詞法單元流,其實這就是詞法分析,完成從字元流到詞法單元流的轉換。分析詞性,決定主謂賓結構,是依照英文的語法辨識出這個結構,這就是語法分析,根據輸入的詞法單元流辨識出語法解析樹。最後,再結合單字的意思和語法結構最後得出這句話的意思,這就是語意分析。編譯器和解釋器處理過程類似,但是要略微複雜一些,這裡只專注於解釋器:
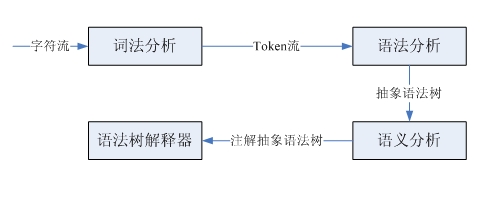
我們只是實作一個很簡單的小語言,所以不涉及到語法樹的生成,以及後續複雜的語意分析。下面我就來看看詞法分析和文法分析。
詞法分析和語法分析分別由詞法解析器和語法解析器完成。這兩種解析器具有類似的結構和功能,它們都是以一個輸入序列為輸入,然後識別出特定的結構。詞法解析器從原始碼字元流中解析出一個一個的token(詞法單元),而語法解析器辨識出子結構和詞法單元,然後再進行一些處理。可以透過LL(1)遞歸下降解析器實現這兩種解析器,這類解析器完成的步驟是:預測子句的類型,呼叫解析函數匹配該子結構、匹配詞法單元,然後按照需要插入程式碼,執行自訂操作。
這裡對LL(1)做簡單介紹,語句的結構通常用樹型結構表示,稱為解析樹,LL(1)做語法解析就依賴解析樹。如:x = x +2;
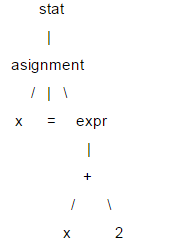
在這棵樹中,像x、=和2這樣的葉節點,稱為終結節點,其他的叫做非終結節點。 LL(1)解析時,不需要建立特定的樹型資料結構,可以為每個非終結節點編寫解析函數,在遇到相應節點時進行調用,這樣就可以透過解析函數的調用序列中(相當於樹的遍歷)獲得解析樹的資訊。在LL(1)解析時,是按照從根節點到葉節點的順序執行的,所以這是一個「下降」的過程,而解析函數又可以呼叫自身,所以是「遞歸」的,因此LL(1 )又叫做遞歸下降解析器。
LL(1)中兩個L都是left-to-right的意思,第一個L表示解析器按從左到右的順序解析輸入內容,第二個L表示在下降過程中,也是按照從左到右的順序遍歷子節點,而1表示根據1個向前看單元做預測。
下面來看看列表小語言的實現,首先是語言的文法,文法用來描述一個語言,算是解析器的設計說明書。
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。
首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3] print 'veca:', veca print 'veca * 2:', veca * 2 print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。

 Python vs.C:申請和用例Apr 12, 2025 am 12:01 AM
Python vs.C:申請和用例Apr 12, 2025 am 12:01 AMPython适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。Python以简洁和强大的生态系统著称,C 则以高性能和底层控制能力闻名。
 2小時的Python計劃:一種現實的方法Apr 11, 2025 am 12:04 AM
2小時的Python計劃:一種現實的方法Apr 11, 2025 am 12:04 AM2小時內可以學會Python的基本編程概念和技能。 1.學習變量和數據類型,2.掌握控制流(條件語句和循環),3.理解函數的定義和使用,4.通過簡單示例和代碼片段快速上手Python編程。
 Python:探索其主要應用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要應用程序Apr 10, 2025 am 09:41 AMPython在web開發、數據科學、機器學習、自動化和腳本編寫等領域有廣泛應用。 1)在web開發中,Django和Flask框架簡化了開發過程。 2)數據科學和機器學習領域,NumPy、Pandas、Scikit-learn和TensorFlow庫提供了強大支持。 3)自動化和腳本編寫方面,Python適用於自動化測試和系統管理等任務。
 您可以在2小時內學到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小時內學到多少python?Apr 09, 2025 pm 04:33 PM兩小時內可以學到Python的基礎知識。 1.學習變量和數據類型,2.掌握控制結構如if語句和循環,3.了解函數的定義和使用。這些將幫助你開始編寫簡單的Python程序。
 如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?Apr 02, 2025 am 07:18 AM
如何在10小時內通過項目和問題驅動的方式教計算機小白編程基礎?Apr 02, 2025 am 07:18 AM如何在10小時內教計算機小白編程基礎?如果你只有10個小時來教計算機小白一些編程知識,你會選擇教些什麼�...
 如何在使用 Fiddler Everywhere 進行中間人讀取時避免被瀏覽器檢測到?Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 進行中間人讀取時避免被瀏覽器檢測到?Apr 02, 2025 am 07:15 AM使用FiddlerEverywhere進行中間人讀取時如何避免被檢測到當你使用FiddlerEverywhere...
 Python 3.6加載Pickle文件報錯"__builtin__"模塊未找到怎麼辦?Apr 02, 2025 am 07:12 AM
Python 3.6加載Pickle文件報錯"__builtin__"模塊未找到怎麼辦?Apr 02, 2025 am 07:12 AMPython3.6環境下加載Pickle文件報錯:ModuleNotFoundError:Nomodulenamed...
 如何提高jieba分詞在景區評論分析中的準確性?Apr 02, 2025 am 07:09 AM
如何提高jieba分詞在景區評論分析中的準確性?Apr 02, 2025 am 07:09 AM如何解決jieba分詞在景區評論分析中的問題?當我們在進行景區評論分析時,往往會使用jieba分詞工具來處理文�...


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

記事本++7.3.1
好用且免費的程式碼編輯器

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

