



Yarn上运行spark-1.6.0
 Yarn上运行spark-1.6.0.pdf
Yarn上运行spark-1.6.0.pdf目录
目录1
1.约定1
2.安装Scala 1
2.1.下载2
2.2.安装2
2.3.设置环境变量2
3.安装Spark 2
3.1.下载2
3.2.安装2
3.3.配置3
3.3.1.修改conf/spark-env.sh 3
4.启动Spark 3
4.1.运行自带示例3
4.2.SparkSQLCli4
5.和Hive集成 4
6.常见错误5
6.1.错误1:unknownqueue:thequeue 5
6.2.SPARK_CLASSPATHwasdetected6
7.相关文档6
1.约定
本文约定Hadoop2.7.1安装在/data/hadoop/current,而Spark1.6.0被安装在/data/hadoop/spark,其中/data/hadoop/spark为指向/data/hadoop/spark。
Spark官网为:http://spark.apache.org/(Shark官网为:http://shark.cs.berkeley.edu/,Shark已成为Spark的一个模块,不再需要单独安装)。
以cluster模式运行Spark,不介绍client模式。
2.安装Scala
联邦理工学院洛桑(EPFL)的MartinOdersky于2001年基于Funnel的工作开始设计Scala。
Scala是一种多范式的编程语言,设计初衷是要集成纯面向对象编程和函数式编程的各种特性。运行在Java虚拟机JVM之上,兼容现有的Java程序,并可调用Java类库。Scala包含编译器和类库,以BSD许可证发布。
2.1.下载
Spark使用Scala开发的,在安装Spark之前,先在各个节上将Scala安装好。Scala的官网为:http://www.scala-lang.org/,下载网址为:http://www.scala-lang.org/download/,本文下载的是二进制安装包scala-2.11.7.tgz。
2.2.安装
本文以root用户(实则也可以非root用户,建议事先规划好)将Scala安装在/data/scala,其中/data/scala是指向/data/scala-2.11.7的软链接。
安装方法非常简单,将scala-2.11.7.tgz上传到/data目录,然后在/data/目录下对scala-2.11.7.tgz进行解压。
接着,建立软链接:ln-s/data/scala-2.11.7/data/scala。
2.3.设置环境变量
Scala被安装完成后,需要将它添加到PATH环境变量中,可以直接修改/etc/profile文件,加入以下内容即可:
|
exportSCALA_HOME=/data/scala exportPATH=$SCALA_HOME/bin:$PATH |
3.安装Spark
Spark的安装以非root用户进行,本文以hadoop用户安装它。
3.1.下载
本文下载的二进制安装包,推荐这种方式,否则编译还得折腾。下载网址为:http://spark.apache.org/downloads.html,本文下载的是spark-1.6.0-bin-hadoop2.6.tgz,这个可以直接跑在YARN上。
3.2.安装
1)将spark-1.6.0-bin-hadoop2.6.tgz上传到目录/data/hadoop下
2)解压:tarxzfspark-1.6.0-bin-hadoop2.6.tgz
3)建立软链接:ln-sspark-1.6.0-bin-hadoop2.6spark
在yarn上运行spark,不需要每台机器都安装spark,可以只安装在一台机器上。但是只能在被安装的机器上运行spark,原因很简单:需要调用spark的文件。
3.3.配置
3.3.1.修改conf/spark-env.sh
可以spark-env.sh.template复制一份,然后增加以下内容:
|
HADOOP_CONF_DIR=/data/hadoop/current/etc/hadoop YARN_CONF_DIR=/data/hadoop/current/etc/hadoop |
4.启动Spark
由于运行在Yarn上,所以没有启动Spark这一过程。而是在执行命令spark-submit时,由Yarn调度运行Spark。
4.1.运行自带示例
|
./bin/spark-submit--classorg.apache.spark.examples.SparkPi\ --masteryarn--deploy-modecluster\ --driver-memory4g\ --executor-memory2g\ --executor-cores1\ --queuedefault\ lib/spark-examples*.jar10 |
运行输出:
|
16/02/0316:08:33INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:34INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:35INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:36INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:37INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:38INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:39INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:RUNNING) 16/02/0316:08:40INFOyarn.Client:Applicationreportforapplication_1454466109748_0007(state:FINISHED) 16/02/0316:08:40INFOyarn.Client: clienttoken:N/A diagnostics:N/A ApplicationMasterhost:10.225.168.251 ApplicationMasterRPCport:0 queue:default starttime:1454486904755 finalstatus:SUCCEEDED trackingURL:http://hadoop-168-254:8088/proxy/application_1454466109748_0007/ user:hadoop 16/02/0316:08:40INFOutil.ShutdownHookManager:Shutdownhookcalled 16/02/0316:08:40INFOutil.ShutdownHookManager:Deletingdirectory/tmp/spark-7fc8538c-8f4c-4d8d-8731-64f5c54c5eac |
4.2.SparkSQLCli
通过运行即可进入SparkSQLCli交互界面,但要在Yarn上以cluster运行,则需要指定参数--master值为yarn(注意不支持参数--deploy-mode的值为cluster,也就是只能以client模式运行在Yarn上):
./bin/spark-sql--masteryarn |
为什么SparkSQLCli只能以client模式运行?其实很好理解,既然是交互,需要看到输出,这个时候cluster模式就没法做到了。因为cluster模式,ApplicationMaster在哪机器上运行,是由Yarn动态确定的。
5.和Hive集成
Spark集成Hive非常简单,只需以下几步:
1)在spark-env.sh中加入HIVE_HOME,如:exportHIVE_HOME=/data/hadoop/hive
2)将Hive的hive-site.xml和hive-log4j.properties两个文件复制到Spark的conf目录下。
完成后,再次执行spark-sql进入Spark的SQLCli,运行命令showtables即可看到在Hive中创建的表。
示例:
./spark-sql--masteryarn--driver-class-path/data/hadoop/hive/lib/mysql-connector-java-5.1.38-bin.jar
6.常见错误
6.1.错误1:unknownqueue:thequeue
运行:
./bin/spark-submit--classorg.apache.spark.examples.SparkPi--masteryarn--deploy-modecluster--driver-memory4g--executor-memory2g--executor-cores1--queuethequeuelib/spark-examples*.jar10
时报如下错误,只需要将“--queuethequeue”改成“--queuedefault”即可。
|
16/02/0315:57:36INFOyarn.Client:Applicationreportforapplication_1454466109748_0004(state:FAILED) 16/02/0315:57:36INFOyarn.Client: clienttoken:N/A diagnostics:Applicationapplication_1454466109748_0004submittedbyuserhadooptounknownqueue:thequeue ApplicationMasterhost:N/A ApplicationMasterRPCport:-1 queue:thequeue starttime:1454486255907 finalstatus:FAILED trackingURL:http://hadoop-168-254:8088/proxy/application_1454466109748_0004/ user:hadoop 16/02/0315:57:36INFOyarn.Client:Deletingstagingdirectory.sparkStaging/application_1454466109748_0004 Exceptioninthread"main"org.apache.spark.SparkException:Applicationapplication_1454466109748_0004finishedwithfailedstatus atorg.apache.spark.deploy.yarn.Client.run(Client.scala:1029) atorg.apache.spark.deploy.yarn.Client$.main(Client.scala:1076) atorg.apache.spark.deploy.yarn.Client.main(Client.scala) atsun.reflect.NativeMethodAccessorImpl.invoke0(NativeMethod) atsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) atsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) atjava.lang.reflect.Method.invoke(Method.java:606) atorg.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731) atorg.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181) atorg.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206) atorg.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121) atorg.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) 16/02/0315:57:36INFOutil.ShutdownHookManager:Shutdownhookcalled 16/02/0315:57:36INFOutil.ShutdownHookManager:Deletingdirectory/tmp/spark-54531ae3-4d02-41be-8b9e-92f4b0f05807 |
6.2.SPARK_CLASSPATHwasdetected
SPARK_CLASSPATHwasdetected(setto'/data/hadoop/hive/lib/mysql-connector-java-5.1.38-bin.jar:').
ThisisdeprecatedinSpark1.0+.
Pleaseinsteaduse:
-./spark-submitwith--driver-class-pathtoaugmentthedriverclasspath
-spark.executor.extraClassPathtoaugmenttheexecutorclasspath
意思是不推荐在spark-env.sh中设置环境变量SPARK_CLASSPATH,可以改成如下推荐的方式:
./spark-sql--masteryarn--driver-class-path/data/hadoop/hive/lib/mysql-connector-java-5.1.38-bin.jar
7.相关文档
《HBase-0.98.0分布式安装指南》
《Hive0.12.0安装指南》
《ZooKeeper-3.4.6分布式安装指南》
《Hadoop2.3.0源码反向工程》
《在Linux上编译Hadoop-2.4.0》
《Accumulo-1.5.1安装指南》
《Drill1.0.0安装指南》
《Shark0.9.1安装指南》
更多,敬请关注技术博客:http://aquester.cublog.cn。

 如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM
如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM根据美国司法部的解释,蓝色警报旨在提供关于可能对执法人员构成直接和紧急威胁的个人的重要信息。这种警报的目的是及时通知公众,并让他们了解与这些罪犯相关的潜在危险。通过这种主动的方式,蓝色警报有助于增强社区的安全意识,促使人们采取必要的预防措施以保护自己和周围的人。这种警报系统的建立旨在提高对潜在威胁的警觉性,并加强执法机构与公众之间的沟通,以共尽管这些紧急通知对我们社会至关重要,但有时可能会对日常生活造成干扰,尤其是在午夜或重要活动时收到通知时。为了确保安全,我们建议您保持这些通知功能开启,但如果
 在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PM
在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PMAndroid中的轮询是一项关键技术,它允许应用程序定期从服务器或数据源检索和更新信息。通过实施轮询,开发人员可以确保实时数据同步并向用户提供最新的内容。它涉及定期向服务器或数据源发送请求并获取最新信息。Android提供了定时器、线程、后台服务等多种机制来高效地完成轮询。这使开发人员能够设计与远程数据源保持同步的响应式动态应用程序。本文探讨了如何在Android中实现轮询。它涵盖了实现此功能所涉及的关键注意事项和步骤。轮询定期检查更新并从服务器或源检索数据的过程在Android中称为轮询。通过
 如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM
如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM为了提升用户体验并防止数据或进度丢失,Android应用程序开发者必须避免意外退出。他们可以通过加入“再次按返回退出”功能来实现这一点,该功能要求用户在特定时间内连续按两次返回按钮才能退出应用程序。这种实现显著提升了用户参与度和满意度,确保他们不会意外丢失任何重要信息Thisguideexaminesthepracticalstepstoadd"PressBackAgaintoExit"capabilityinAndroid.Itpresentsasystematicguid
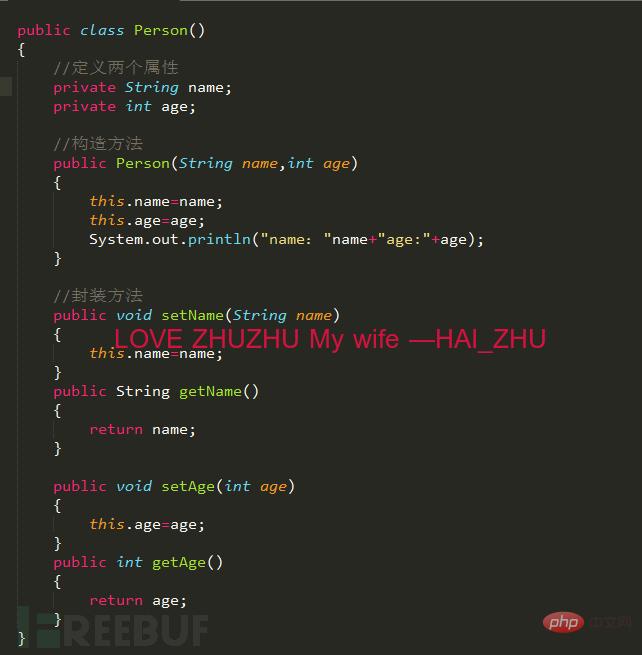 Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM
Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM1.java复杂类如果有什么地方不懂,请看:JAVA总纲或者构造方法这里贴代码,很简单没有难度。2.smali代码我们要把java代码转为smali代码,可以参考java转smali我们还是分模块来看。2.1第一个模块——信息模块这个模块就是基本信息,说明了类名等,知道就好对分析帮助不大。2.2第二个模块——构造方法我们来一句一句解析,如果有之前解析重复的地方就不再重复了。但是会提供链接。.methodpublicconstructor(Ljava/lang/String;I)V这一句话分为.m
 如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM
如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM如何将WhatsApp聊天从Android转移到iPhone?你已经拿到了新的iPhone15,并且你正在从Android跳跃?如果是这种情况,您可能还对将WhatsApp从Android转移到iPhone感到好奇。但是,老实说,这有点棘手,因为Android和iPhone的操作系统不兼容。但不要失去希望。这不是什么不可能完成的任务。让我们在本文中讨论几种将WhatsApp从Android转移到iPhone15的方法。因此,坚持到最后以彻底学习解决方案。如何在不删除数据的情况下将WhatsApp
 同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM
同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM原因:1、安卓系统上设置了一个JAVA虚拟机来支持Java应用程序的运行,而这种虚拟机对硬件的消耗是非常大的;2、手机生产厂商对安卓系统的定制与开发,增加了安卓系统的负担,拖慢其运行速度影响其流畅性;3、应用软件太臃肿,同质化严重,在一定程度上拖慢安卓手机的运行速度。
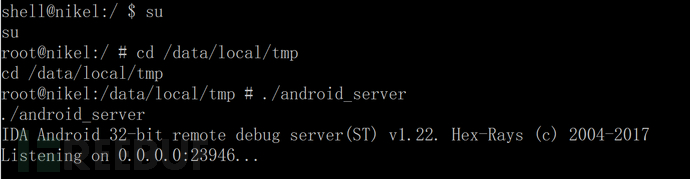 Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM
Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM1.启动ida端口监听1.1启动Android_server服务1.2端口转发1.3软件进入调试模式2.ida下断2.1attach附加进程2.2断三项2.3选择进程2.4打开Modules搜索artPS:小知识Android4.4版本之前系统函数在libdvm.soAndroid5.0之后系统函数在libart.so2.5打开Openmemory()函数在libart.so中搜索Openmemory函数并且跟进去。PS:小知识一般来说,系统dex都会在这个函数中进行加载,但是会出现一个问题,后
 Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM
Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM1.自动化测试自动化测试主要包括几个部分,UI功能的自动化测试、接口的自动化测试、其他专项的自动化测试。1.1UI功能自动化测试UI功能的自动化测试,也就是大家常说的自动化测试,主要是基于UI界面进行的自动化测试,通过脚本实现UI功能的点击,替代人工进行自动化测试。这个测试的优势在于对高度重复的界面特性功能测试的测试人力进行有效的释放,利用脚本的执行,实现功能的快速高效回归。但这种测试的不足之处也是显而易见的,主要包括维护成本高,易发生误判,兼容性不足等。因为是基于界面操作,界面的稳定程度便成了


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

