


效果图如下: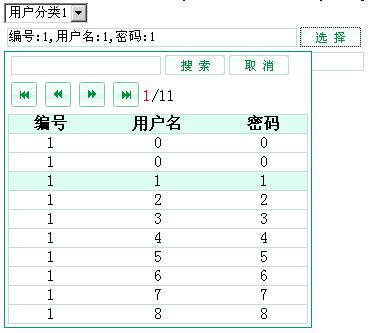
解决思路:
1.单击[选择]时,根据当前选择(下拉框)的分类ID,使用ajax请求,取得数据源(服务端使用dataSet.getXml()输出,因为数据量不是很大,所以就偷懒了)
2.客户端使用xml数据岛分页显示(使用数据岛分页比较简单,不用写太多的代码)
3.搜索时,根据当前选择(下拉框)的分类ID,和搜索关键字,重新使用ajax请求(好像也可以使用xml的结果过滤,但为了方便,重新请求算了),跳到第2步显示
4.取数据时,单击某行时,使用onclick事件,把当前行的tr做为参数,使用dom操作就可以得到tr里的td的值
附:由于没考虑到其它细节的问题,所以代码有点乱,希望各位能多多指导,各位的批评就是我进步的最好的捷径.谢谢
贴出全部代码,希望能和大家相互交流一下
index.html 显示页面:
 |
data.js 所有操作js代码
var xmlHttp;
var xmlContent; //ajax请求后返回保存的数据
var key = "";
var id = "";
//---------------------样式设置------------------//
var divid = "selectData" //说明第4步
var txtValueID = "selectValue"; //说时第2步
var fieldNames = new Array(3); //单击某行取值是,每列值前添加一个该值列名
var isShowFieldNames = true; //取值时,是否要显示列名 true为显示,false不显示
fieldNames[0]="编号:";
fieldNames[1]="用户名:";
fieldNames[2]="密码:";
var pageSize = 10; //每页显示行数
var onmouseoverBG = "#DDFFEC"; //鼠标移上去该行的背景颜色
var onmouseoutBG = "#ffffff"; //鼠标离开后该行的背景颜色
//表头列名根据需要修改
var tableHead = "";
tableHead += "
tableHead += "
tableHead += "
tableHead += "";
//数据绑定字段名,修改DATAFLD里的的字段名
var dataFiled = "
dataFiled += "
dataFiled += "
var RequestFile = "getXml1.aspx"; //请求页面
//-------------------外部调用--------------------------//
//显示选择
//productID是下拉框ID,请根据需要修改
function show()
{
$(divid).style.display = ''
$(divid).style.position="absolute"
$(divid).style.backgroundColor="#FFFFFF"
key = "";
id = productID.options[productID.selectedIndex].value;
RequestXML();
}
//分类改变时隐藏
function changeID()
{
hide();
}
//---------------------内部方法,一般不用修改---------------------------//
//选择某行的值,显示到文本框
function getCurrentRowData(tr)
{
var tds = tr.getElementsByTagName("td") //得到所有列
var result="";
for(var i = 0; i {
if(isShowFieldNames){result += fieldNames[i]};
if(i != tds.length -1 )//是否是最后一列
{
result += tr.getElementsByTagName("div")[i].firstChild.nodeValue + ","; //得到第i列的值 + ","
}
else
{
result += tr.getElementsByTagName("div")[i].firstChild.nodeValue; //得到第i列的值
}
}
$(txtValueID).value = result;
hide();
}
//显示内容
function ShowData()
{
var data = $(divid);
var content = "
content += "
content += "
 |
 |
content += "
content += "
content += "
//----------------翻页操作-----------------------//
content += "
| " content += "  "; "; content += "  "; "; content += "  "; "; content += "  "; "; content += " | "
1" content += " |
//----------------数据源-----------------------//
content += "
content += "
content += "
data.innerHTML = content;
GetPages();
}
//得到总页
function GetPages()
{
var rowCount = $("data_souce").getElementsByTagName("Table"); //得到所有table节点,得到总记录数
$("pages").innerHTML = Math.ceil(rowCount.length / pageSize);
$("compart").innerHTML = "/";
if(rowCount.length == 0)
{
$("resultxml").innerHTML = "找不到相关数据";
}
}
//首页时得到当前页
function firstPage()
{
$("page").innerHTML = 1;
}
//上页时得到当前页
function previousPage()
{
if($("page").innerHTML != "1")
{
$("page").innerHTML = parseInt($("page").innerHTML) - 1;
}
}
//下页时得到当前页
function nextPage()
{
if($("page").innerHTML != $("pages").innerHTML)
{
$("page").innerHTML = parseInt($("page").innerHTML) + 1;
}
}
//尾页时得到当前页
function lastPage()
{
$("page").innerHTML = $("pages").innerHTML;
}
//翻页操作
function GotoPage(page)
{
switch(page)
{
case "first":
{
datas.firstPage();
firstPage();
break;
}
case "previous":
{
datas.previousPage();
previousPage();
break;
}
case "next":
{
datas.nextPage();
nextPage();
break;
}
case "last":
{
datas.lastPage();
lastPage();
break;
}
}
}
//搜索
function Search()
{
key = $("key").value;
if(key == "")
{
alert("请输入搜索关键字");
return;
}
RequestXML();
}
//根据ID得到对象
function $(id)
{
return document.getElementById(id);
}
//隐藏选择
function hide()
{
$(divid).style.display ="none";
}
//创建XMLHttpRequest
function CreateXMLHttpRequest()
{
if(window.ActiveXObject)
{
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
else if(window.XMLHttpRequest)
{
xmlHttp = new XMLHttpRequest();
}
}
//请求
function RequestXML()
{
var url = RequestFile + "?id=" + id + "&key=" + key;
CreateXMLHttpRequest();
xmlHttp.open("get",url);
xmlHttp.onreadystatechange = GetXMLResult;
xmlHttp.send(null);
}
//接收
function GetXMLResult()
{
if(xmlHttp.readyState == 4)
{
if(xmlHttp.status == 200)
{
xmlContent = xmlHttp.responseText;
ShowData();
}
}
else
{
$(divid).innerHTML = "正在读取数据中";
}
}
getXml.aspx 服务端数据源
private void Page_Load(object sender, System.EventArgs e)
{
Response.Write(GetData());
Response.End();
}
private string GetData()
{
string id = Request.QueryString["id"];
string key = Request.QueryString["key"];
string sql = "select * from T_user where F_id = " + id;
if (key.Length > 0){sql += " and F_id like '%" + key + "%'or F_passWord like '%" + key + "%' or F_userName like '%" + key + "%'";}
StringBuilder sb = new StringBuilder();
sb.Append("");
SqlConnection conn = new SqlConnection("server=.;uid=sa;pwd=sa;database=WebTest");
conn.Open();
SqlDataAdapter da = new SqlDataAdapter(sql,conn);
DataSet ds = new DataSet();
da.Fill(ds);
conn.Close();
sb.Append(ds.GetXml());
return sb.ToString();
}

 Python vs. JavaScript:開發人員的比較分析May 09, 2025 am 12:22 AM
Python vs. JavaScript:開發人員的比較分析May 09, 2025 am 12:22 AMPython和JavaScript的主要區別在於類型系統和應用場景。 1.Python使用動態類型,適合科學計算和數據分析。 2.JavaScript採用弱類型,廣泛用於前端和全棧開發。兩者在異步編程和性能優化上各有優勢,選擇時應根據項目需求決定。
 Python vs. JavaScript:選擇合適的工具May 08, 2025 am 12:10 AM
Python vs. JavaScript:選擇合適的工具May 08, 2025 am 12:10 AM選擇Python還是JavaScript取決於項目類型:1)數據科學和自動化任務選擇Python;2)前端和全棧開發選擇JavaScript。 Python因其在數據處理和自動化方面的強大庫而備受青睞,而JavaScript則因其在網頁交互和全棧開發中的優勢而不可或缺。
 Python和JavaScript:了解每個的優勢May 06, 2025 am 12:15 AM
Python和JavaScript:了解每個的優勢May 06, 2025 am 12:15 AMPython和JavaScript各有優勢,選擇取決於項目需求和個人偏好。 1.Python易學,語法簡潔,適用於數據科學和後端開發,但執行速度較慢。 2.JavaScript在前端開發中無處不在,異步編程能力強,Node.js使其適用於全棧開發,但語法可能複雜且易出錯。
 JavaScript的核心:它是在C還是C上構建的?May 05, 2025 am 12:07 AM
JavaScript的核心:它是在C還是C上構建的?May 05, 2025 am 12:07 AMjavascriptisnotbuiltoncorc; sanInterpretedlanguagethatrunsonenginesoftenwritteninc.1)JavascriptwasdesignedAsignedAsalightWeight,drackendedlanguageforwebbrowsers.2)Enginesevolvedfromsimpleterterpretpretpretpretpreterterpretpretpretpretpretpretpretpretpretcompilerers,典型地,替代品。
 JavaScript應用程序:從前端到後端May 04, 2025 am 12:12 AM
JavaScript應用程序:從前端到後端May 04, 2025 am 12:12 AMJavaScript可用於前端和後端開發。前端通過DOM操作增強用戶體驗,後端通過Node.js處理服務器任務。 1.前端示例:改變網頁文本內容。 2.後端示例:創建Node.js服務器。
 Python vs. JavaScript:您應該學到哪種語言?May 03, 2025 am 12:10 AM
Python vs. JavaScript:您應該學到哪種語言?May 03, 2025 am 12:10 AM選擇Python還是JavaScript應基於職業發展、學習曲線和生態系統:1)職業發展:Python適合數據科學和後端開發,JavaScript適合前端和全棧開發。 2)學習曲線:Python語法簡潔,適合初學者;JavaScript語法靈活。 3)生態系統:Python有豐富的科學計算庫,JavaScript有強大的前端框架。
 JavaScript框架:為現代網絡開發提供動力May 02, 2025 am 12:04 AM
JavaScript框架:為現代網絡開發提供動力May 02, 2025 am 12:04 AMJavaScript框架的強大之處在於簡化開發、提升用戶體驗和應用性能。選擇框架時應考慮:1.項目規模和復雜度,2.團隊經驗,3.生態系統和社區支持。
 JavaScript,C和瀏覽器之間的關係May 01, 2025 am 12:06 AM
JavaScript,C和瀏覽器之間的關係May 01, 2025 am 12:06 AM引言我知道你可能會覺得奇怪,JavaScript、C 和瀏覽器之間到底有什麼關係?它們之間看似毫無關聯,但實際上,它們在現代網絡開發中扮演著非常重要的角色。今天我們就來深入探討一下這三者之間的緊密聯繫。通過這篇文章,你將了解到JavaScript如何在瀏覽器中運行,C 在瀏覽器引擎中的作用,以及它們如何共同推動網頁的渲染和交互。 JavaScript與瀏覽器的關係我們都知道,JavaScript是前端開發的核心語言,它直接在瀏覽器中運行,讓網頁變得生動有趣。你是否曾經想過,為什麼JavaScr


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SublimeText3漢化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript開發工具

Dreamweaver Mac版
視覺化網頁開發工具

