


similar_text算相似性时归一化时的疑问
我在算两个字符串的长度时,发现归一化时好像此函数采取的方式不一样。
第一次,我试了两个不一样长的字符串,算其编辑距离:
echo "levenshtein计算:\n";echo levenshtein("seller_id","selr_id");echo "\n";
得到的结果是:2
再用同样的两个字符串,用PHP的similar_text函数来求其相似性
echo "similar_text计算:\n";similar_text("seller_id","selr_id",$percent);
echo $percent;
出现在相似性是:87.5
把2这个距离归一化时,正好符合公式:1-(编辑距离/(两个字符串的长度之和))
第二次,我试了两个一样长度的字符串,分别算其编辑距离和相似性
similar_text("abcd","1234",$percent);echo $percent;echo "\n";
echo levenshtein("abcd","1234");
得到的值分别为:4和0
正好符合公式:1-(编辑距离/(任一个字符串的长度))
我的问题是:为什么对两个不一样长的字符串求相似性时,分母是两个字符串的长度之和呢?
我在网上找了些pdf文档看,对编辑距离归一化时,其分母是最长的那个字符串的长度呢。
------解决方案--------------------
应该说 similar_text 函数的设计者,考虑的还是蛮周到的
当传入的两个串长度相同时,计算的相似度与理论上并无差异
当传入的两个串长度不同时,得到的相似度不像理论上的那么陡峭。也就是说被匹配的概率变大
当然如果你不希望这样的话可以自行计算,串都是你的,他也返回了已匹配的数量。计算一下并不困难

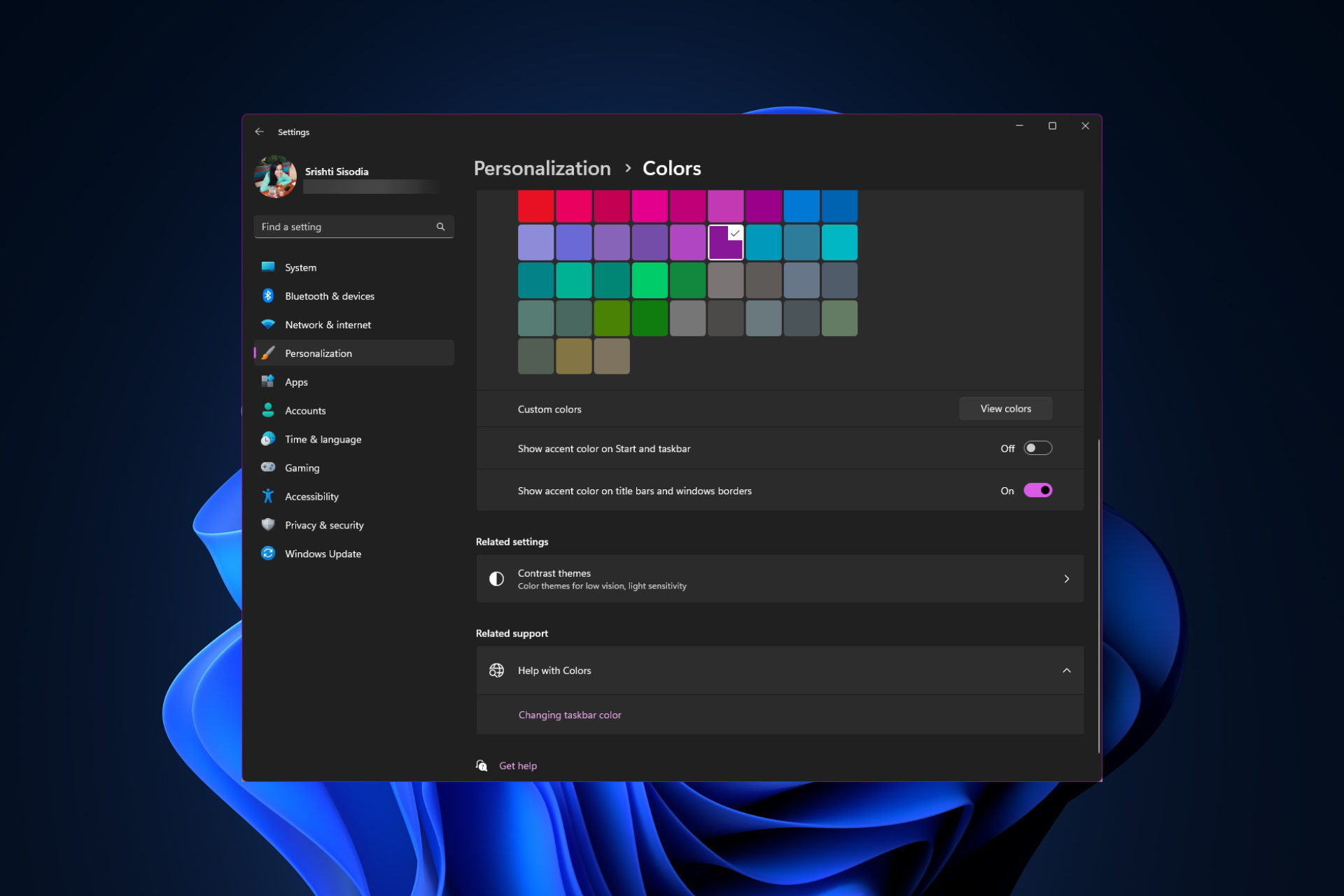 如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?Sep 14, 2023 pm 03:33 PM默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题Jul 16, 2023 pm 03:29 PM您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
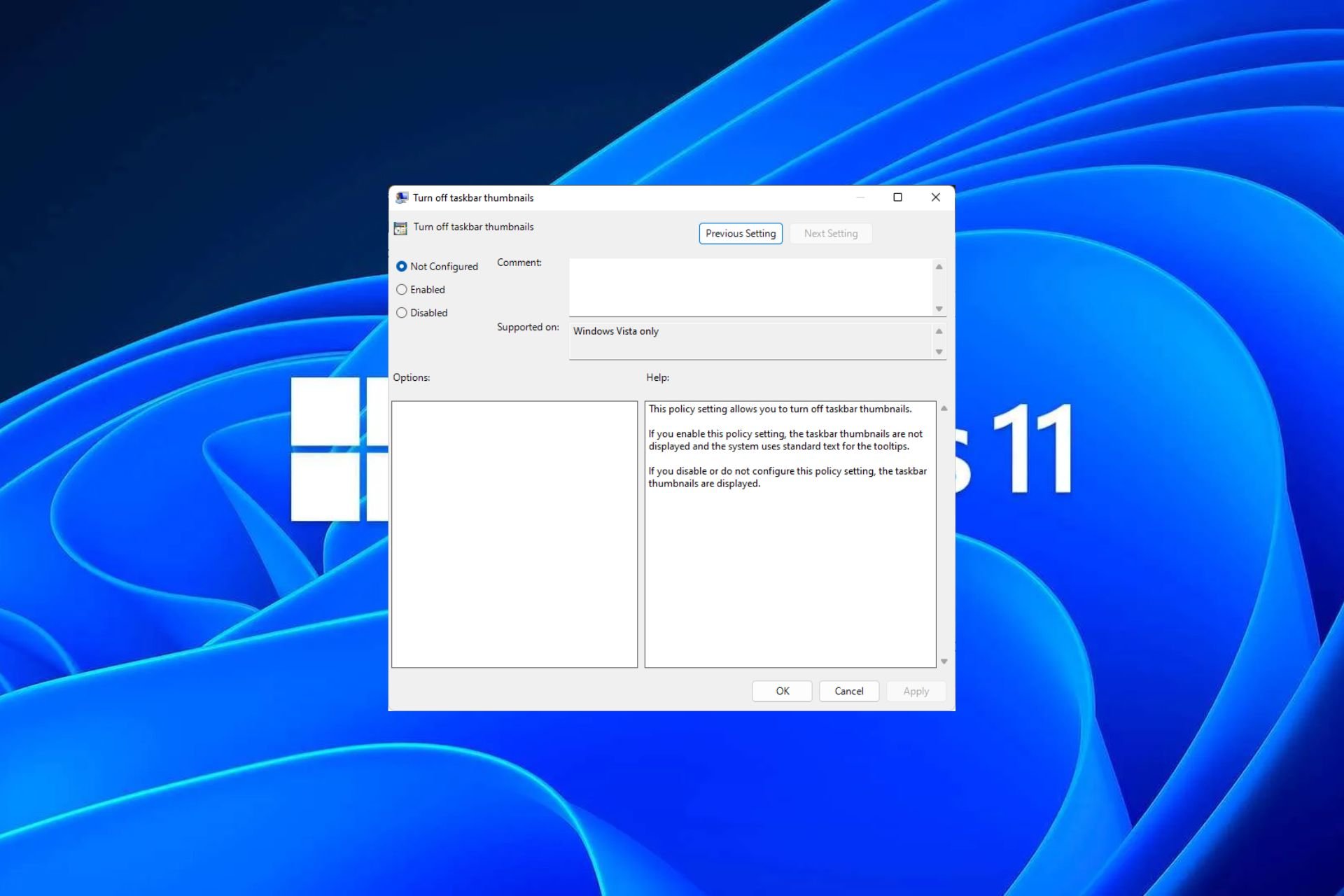 Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法Sep 15, 2023 pm 03:57 PM任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
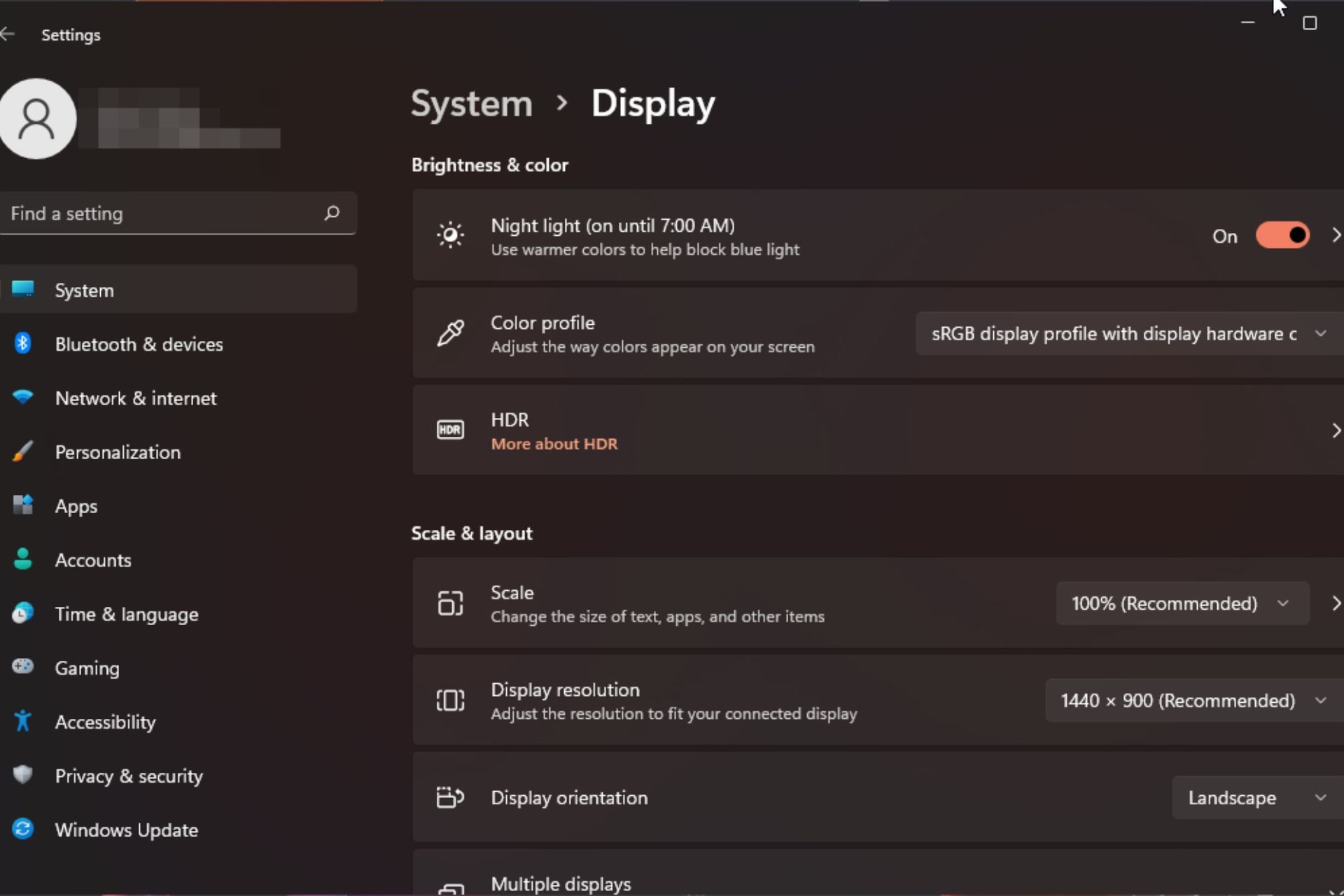 Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南Sep 19, 2023 pm 06:45 PM在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 如何修复Windows服务器中的激活错误代码0xc004f069Jul 22, 2023 am 09:49 AM
如何修复Windows服务器中的激活错误代码0xc004f069Jul 22, 2023 am 09:49 AMWindows上的激活过程有时会突然转向显示包含此错误代码0xc004f069的错误消息。虽然激活过程已经联机,但一些运行WindowsServer的旧系统可能会遇到此问题。通过这些初步检查,如果这些检查不能帮助您激活系统,请跳转到主要解决方案以解决问题。解决方法–关闭错误消息和激活窗口。然后,重新启动计算机。再次从头开始重试Windows激活过程。修复1–从终端激活从cmd终端激活WindowsServerEdition系统。阶段–1检查Windows服务器版本您必须检查您使用的是哪种类型的W
 如何在Safari中禁用隐私浏览身份验证:iOS 17的操作指南Sep 11, 2023 pm 06:37 PM
如何在Safari中禁用隐私浏览身份验证:iOS 17的操作指南Sep 11, 2023 pm 06:37 PM在iOS17中,Apple在其移动操作系统中引入了几项新的隐私和安全功能,其中之一是能够要求对Safari中的隐私浏览选项卡进行二次身份验证。以下是它的工作原理以及如何将其关闭。在运行iOS17或iPadOS17的iPhone或iPad上,如果您在Safari中打开了任何“隐私浏览”选项卡,然后退出会话或应用程序,Apple的浏览器现在需要面容ID/TouchID身份验证或密码才能再次访问它们。换句话说,如果有人在解锁您的iPhone或iPad时拿到了它,他们仍然无法在不知道您的密码的情况下查看
 如何在iPhone上提取RAR文件Jul 12, 2023 pm 07:53 PM
如何在iPhone上提取RAR文件Jul 12, 2023 pm 07:53 PM很多时候,非常大的文件很难在设备之间共享,尤其是智能手机等。因此,这些文件首先被存档/压缩成RAR文件,然后发送到另一个设备进行共享。但问题是RAR文件不容易在iPhone上提取。要提取zip文件,只需轻点一下即可。没有多少人知道在iPhone上提取RAR文件的过程,对于初学者来说,这些步骤可能会令人困惑。可以使用iPhone上称为快捷方式的默认应用程序来完成此操作。我们在这里逐步解释了如何使用快捷方式应用程序在iPhone上提取任何RAR文件。如何在iPhone上提取RAR文件步骤1:首先,您
 在 Windows 3 上禁用透明效果的 11 种快速方法Sep 06, 2023 pm 04:13 PM
在 Windows 3 上禁用透明效果的 11 种快速方法Sep 06, 2023 pm 04:13 PM透明效果增强了Windows11的视觉吸引力,尤其是任务栏、“开始”菜单和登录屏幕。但我们都有不同的偏好。对于那些不喜欢它的人来说,在Windows11中禁用透明度效果不会花费太多时间。禁用后,背景颜色不会影响操作系统组件的配色方案,并且会采用相当不透明的形式。此外,以下是在Windows11中禁用透明度效果的主要好处:Windows11中的透明度效果可能会影响性能并降低旧电脑的速度。功耗增加,电池寿命缩短,但在大多数情况下并不明显。动画感觉更流畅、更无缝。如何在Windows11上关闭透明效果


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

禪工作室 13.0.1
強大的PHP整合開發環境

