



XML和RSS的解析、驗證和安全性可以通過以下步驟實現:解析XML/RSS:使用Python的xml.etree.ElementTree模塊解析RSS feed,提取關鍵信息。驗證XML:使用lxml庫和XSD模式驗證XML文檔的有效性。確保安全性:使用defusedxml庫防止XXE攻擊,保護XML數據的安全。這些步驟幫助開發者高效處理和保護XML/RSS數據,提升工作效率和數據安全性。
引言
在當今的數據驅動世界中,XML和RSS作為數據交換和內容分發的標準格式,扮演著至關重要的角色。無論你是開發者、數據分析師,還是內容創作者,掌握XML和RSS的解析、驗證和安全性,不僅能提升你的工作效率,還能確保數據的完整性和安全性。本文將帶你深入探索XML和RSS的奧秘,從基礎知識到高級應用,提供實用的代碼示例和經驗分享,幫助你成為XML/RSS領域的專家。
基礎知識回顧
XML(eXtensible Markup Language)是一種標記語言,用於存儲和傳輸數據。它的靈活性和可擴展性使其成為許多應用的首選數據格式。 RSS(Really Simple Syndication)則是一種基於XML的格式,用於發布頻繁更新的內容,如博客文章、新聞等。
在處理XML和RSS時,我們需要了解一些關鍵概念,如元素、屬性、命名空間等。這些概念是理解和操作XML/RSS數據的基礎。
核心概念或功能解析
XML/RSS解析
XML/RSS解析是將XML或RSS文檔轉換為可編程對象的過程。解析器可以是基於DOM(文檔對像模型)的,也可以是基於SAX(簡單API for XML)的。 DOM解析器將整個文檔加載到內存中,適合處理較小的文檔;而SAX解析器則以流的方式處理文檔,適用於大型文檔。
讓我們看一個簡單的Python代碼示例,使用xml.etree.ElementTree模塊解析一個RSS feed:
import xml.etree.ElementTree as ET
# 解析RSS feed
tree = ET.parse('example_rss.xml')
root = tree.getroot()
# 遍歷所有item元素for item in root.findall('.//item'):
title = item.find('title').text
link = item.find('link').text
print(f'Title: {title}, Link: {link}')這個示例展示瞭如何使用ElementTree解析RSS feed,並提取每個item的標題和鏈接。
XML驗證
XML驗證是確保XML文檔符合特定模式(如DTD或XSD)的過程。驗證可以幫助我們檢測文檔中的錯誤,確保數據的完整性和一致性。
使用Python的lxml庫,我們可以輕鬆地驗證XML文檔:
from lxml import etree
# 加載XML文檔和XSD模式xml_doc = etree.parse('example.xml')
xsd_doc = etree.parse('example.xsd')
# 創建XSD驗證器xsd_schema = etree.XMLSchema(xsd_doc)
# 驗證XML文檔if xsd_schema.validate(xml_doc):
print("XML文檔有效")
else:
print("XML文檔無效")
for error in xsd_schema.error_log:
print(error.message)這個示例展示瞭如何使用XSD模式驗證XML文檔,並處理驗證錯誤。
XML/RSS安全性
在處理XML和RSS時,安全性是一個不容忽視的問題。常見的安全威脅包括XML注入、XXE(XML外部實體)攻擊等。
為了防止XML注入,我們需要對用戶輸入進行嚴格的驗證和過濾。以下是一個簡單的示例,展示如何在Python中使用defusedxml庫防止XXE攻擊:
from defusedxml.ElementTree import parse
# 解析XML文檔,防止XXE攻擊tree = parse('example.xml')
root = tree.getroot()
# 處理XML數據for element in root.iter():
print(element.tag, element.text)這個示例展示瞭如何使用defusedxml庫解析XML文檔,防止XXE攻擊。
使用示例
基本用法
讓我們看一個更複雜的示例,展示如何解析和處理一個RSS feed,並提取其中的關鍵信息:
import xml.etree.ElementTree as ET
from datetime import datetime
# 解析RSS feed
tree = ET.parse('example_rss.xml')
root = tree.getroot()
# 提取頻道信息channel_title = root.find('channel/title').text
channel_link = root.find('channel/link').text
channel_description = root.find('channel/description').text
print(f'Channel: {channel_title}')
print(f'Link: {channel_link}')
print(f'Description: {channel_description}')
# 遍歷所有item元素for item in root.findall('.//item'):
title = item.find('title').text
link = item.find('link').text
pub_date = item.find('pubDate').text
# 解析發布日期pub_date = datetime.strptime(pub_date, '%a, %d %b %Y %H:%M:%S %Z')
print(f'Title: {title}')
print(f'Link: {link}')
print(f'Published: {pub_date}')
print('---')這個示例展示瞭如何解析RSS feed,提取頻道信息和每個item的標題、鏈接和發布日期。
高級用法
在處理大型XML文檔時,我們可能需要使用流式解析器來提高性能。以下是一個示例,展示如何使用xml.sax模塊解析大型XML文檔:
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def __init__(self):
self.current_data = ""
self.title = ""
self.link = ""
def startElement(self, tag, attributes):
self.current_data = tag
def endElement(self, tag):
if self.current_data == "title":
print(f"Title: {self.title}")
elif self.current_data == "link":
print(f"Link: {self.link}")
self.current_data = ""
def characters(self, content):
if self.current_data == "title":
self.title = content
elif self.current_data == "link":
self.link = content
# 創建一個SAX解析器parser = xml.sax.make_parser()
parser.setContentHandler(MyHandler())
# 解析XML文檔parser.parse('large_example.xml')這個示例展示瞭如何使用SAX解析器處理大型XML文檔,逐步處理每個元素,提高內存效率。
常見錯誤與調試技巧
在處理XML和RSS時,常見的錯誤包括格式錯誤、命名空間衝突、編碼問題等。以下是一些調試技巧:
- 使用XML驗證工具(如
xmllint)檢查文檔的有效性。 - 仔細檢查命名空間聲明,確保正確使用。
- 使用
chardet庫檢測和處理編碼問題。
例如,如果遇到XML格式錯誤,可以使用以下代碼進行調試:
import xml.etree.ElementTree as ET
try:
tree = ET.parse('example.xml')
except ET.ParseError as e:
print(f'解析錯誤: {e}')
print(f'錯誤位置: {e.position}')這個示例展示瞭如何捕獲和處理XML解析錯誤,提供詳細的錯誤信息和位置。
性能優化與最佳實踐
在處理XML和RSS時,性能優化和最佳實踐至關重要。以下是一些建議:
- 使用流式解析器處理大型文檔,減少內存佔用。
- 盡量避免使用DOM解析器處理大型文檔,改用SAX或其他流式解析器。
- 使用緩存機制,減少重複解析XML文檔的開銷。
- 編寫可讀性和可維護性高的代碼,使用有意義的變量名和註釋。
例如,我們可以使用lru_cache裝飾器緩存解析結果,提高性能:
from functools import lru_cache
import xml.etree.ElementTree as ET
@lru_cache(maxsize=None)
def parse_rss(feed_url):
tree = ET.parse(feed_url)
root = tree.getroot()
return root
# 使用緩存解析RSS feed
root = parse_rss('example_rss.xml')這個示例展示瞭如何使用緩存機制優化RSS feed的解析性能。
總之,掌握XML和RSS的解析、驗證和安全性,不僅能提升你的編程技能,還能在實際項目中發揮重要作用。希望本文的深入解析和實用示例能為你提供有價值的指導和啟發。
以上是XML/RSS深水潛水:掌握解析,驗證和安全性的詳細內容。更多資訊請關注PHP中文網其他相關文章!

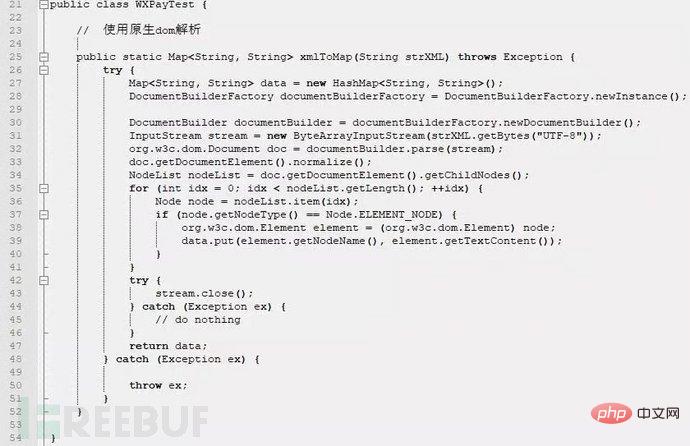 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
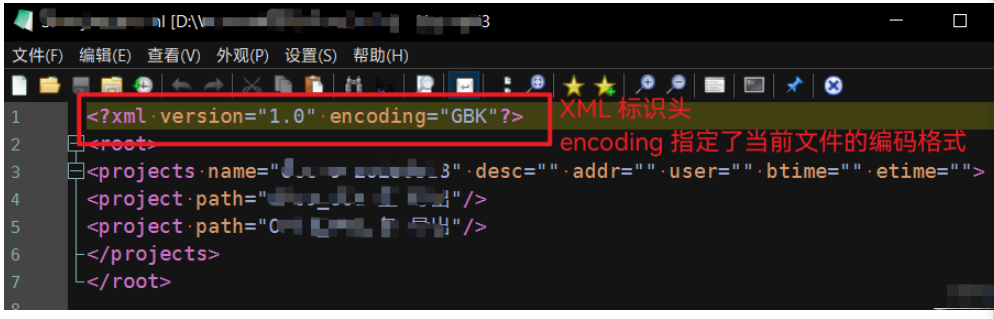 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys
 Python如何使用Beautiful Soup(BS4)库解析HTML和XMLMay 13, 2023 pm 09:55 PM
Python如何使用Beautiful Soup(BS4)库解析HTML和XMLMay 13, 2023 pm 09:55 PM一、BeautifulSoup概述:BeautifulSoup支持从HTML或XML文件中提取数据的Python库;它支持Python标准库中的HTML解析器,还支持一些第三方的解析器lxml。BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。安装:pipinstallbeautifulsoup4可选择安装解析器pipinstalllxmlpipinstallhtml5lib二、BeautifulSoup4简单使用假设有这样一个Html,具体内容如下


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Atom編輯器mac版下載
最受歡迎的的開源編輯器

