
小語言模型的績效評估

- Christopher Nolan原創
- 2025-03-17 09:16:151003瀏覽
本文探討了小語言模型(SLM)的優勢,而不是其較大的對應物,重點是它們對資源約束環境的適用性。 SLM少於100億個參數,為邊緣計算和實時應用程序提供速度和資源效率至關重要。本文使用Ollama在Google Colab上詳細介紹了他們的創建,應用程序和實施。
本指南涵蓋:
- 了解SLM:了解SLM的定義特徵及其與LLM的關鍵差異。
- SLM創建技術:探索用於從LLM創建有效SLM的知識蒸餾,修剪和量化方法。
- 績效評估:通過對其輸出的比較分析,比較各種SLM(Llama 2,Microsoft Phi,Qwen 2,Gemma 2,Mistral 7b)的性能。
- 實際實施:使用Ollama在Google Colab上運行SLMS的分步指南。
- SLMS的應用:發現SLMS Excel(包括聊天機器人,虛擬助手和邊緣計算方案)的不同應用程序。
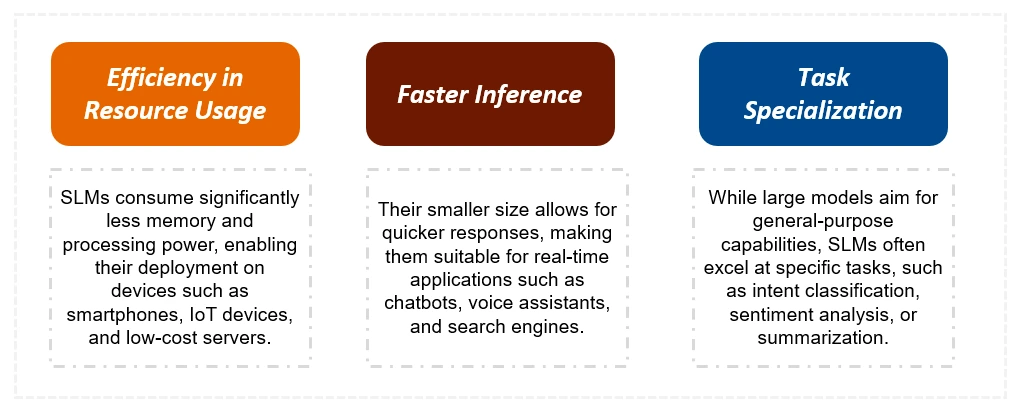
關鍵差異:SLM與LLMS
SLM明顯小於LLM,需要更少的培訓數據和計算資源。這導致推理時間更快,成本較低。雖然LLM在復雜的任務中表現出色,但SLM是針對特定任務進行了優化的,並且更適合於資源有限的設備。下表總結了關鍵區別:
| 特徵 | 小語言模型(SLM) | 大語言模型(LLM) |
|---|---|---|
| 尺寸 | 明顯較小(100億以下參數) | 大得多(數百萬或萬億個參數) |
| 培訓數據 | 較小,集中的數據集 | 大量,多樣化的數據集 |
| 訓練時間 | 較短(週) | 更長(月) |
| 資源 | 低計算要求 | 高計算要求 |
| 任務能力 | 專業任務 | 通用任務 |
| 推理 | 可以在邊緣設備上運行 | 通常需要強大的GPU |
| 響應時間 | 快點 | 慢點 |
| 成本 | 降低 | 更高 |
建築SLM:技術和示例
本節詳細介紹了從LLMS創建SLM的方法:
- 知識蒸餾:較小的“學生”模型從較大的“老師”模型的輸出中學習。
- 修剪:在較大模型中刪除不太重要的連接或神經元。
- 量化:降低模型參數的精度,降低內存要求。
然後,文章對幾個最先進的SLM進行了詳細比較,包括Llama 2,Microsoft Phi,Qwen 2,Gemma 2和Mismtral 7b,突出了它們的獨特功能和性能基準。

在Google Colab上與Ollama一起運行SLM
一份實用指南演示瞭如何使用Ollama在Google Colab上運行SLM,並提供用於安裝,模型選擇和及時執行的代碼段。本文展示了來自不同模型的輸出,從而可以直接比較其在示例任務上的性能。
結論和常見問題解答
本文總結了SLM的優勢及其對各種應用的適用性。一個常見的問題部分介紹了有關SLM,知識蒸餾以及修剪和量化之間的差異的常見疑問。關鍵要點強調了SLM在效率和績效之間實現的平衡,使其成為開發人員和企業的寶貴工具。
以上是小語言模型的績效評估的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn