



小語言模型(SLM)對AI產生了重大影響。它們提供出色的性能,同時有效且具有成本效益。一個傑出的例子是Llama 3.2 3b。它在檢索型生成(RAG)任務中表現出色,降低計算成本和內存使用情況,同時保持高精度。本文探討瞭如何微調Llama 3.2 3B模型。了解較小的模型如何在抹布任務中表現出色,並突破緊湊的AI解決方案可以實現的邊界。
目錄
- 什麼是Llama 3.2 3b?
- Finetuning Llama 3.2 3b
- 洛拉
- 需要庫
- 導入庫
- 初始化模型和標記器
- 初始化PEFT的模型
- 數據處理
- 設置教練參數
- 微調模型
- 測試並保存模型
- 結論
- 常見問題
什麼是Llama 3.2 3b?
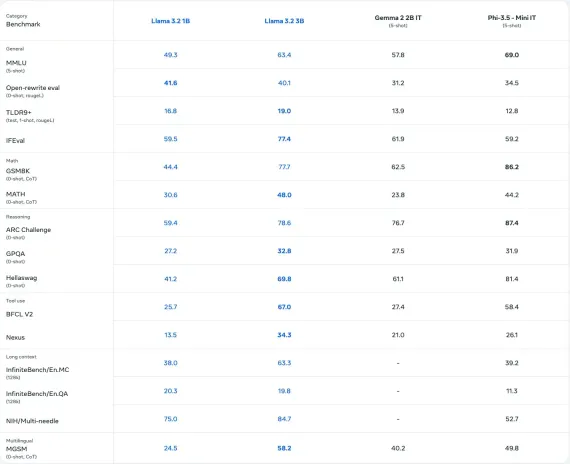
由Meta開發的Llama 3.2 3B模型是一個多語言SLM,具有30億個參數,專為問題回答,摘要和對話系統等任務而設計。它的表現優於行業基準的許多開源模型,並支持各種語言。 Llama 3.2有各種尺寸可用,提供有效的計算性能,並包括在移動和邊緣環境中更快,存儲效率部署的量化版本。
另請閱讀:前13個小語言模型(SLM)
Finetuning Llama 3.2 3b
微調對於將SLM或LLMS調整為特定領域或任務(例如醫療,法律或抹布應用程序)至關重要。雖然預培訓使語言模型能夠生成跨不同主題的文本,但通過微調對特定於域或特定任務的數據進行微調重新培訓,以提高相關性和性能。為了解決微調所有參數的高計算成本,諸如參數有效微調(PEFT)之類的技術專注於訓練模型參數的一個子集,在維持性能的同時優化資源使用情況。
洛拉
一種這樣的PEFT方法是低級適應(LORA)。
在洛拉(Lora),將SLM或LLM中的重量基質分解為兩個低級矩陣的產物。
W = WA * WB
如果W具有M行和n列,則可以將其分解為M行和R列中的WA,以及帶有R行和N列的WB。這裡的r遠小於m或n。因此,我們只能訓練r*(mn)值,而不是訓練m*n值。 r稱為等級,這是我們可以選擇的超參數。
def lora_linear(x):<br> h = x @ w#常規線性<br> h =比例 *(x @ w_a @ w_b)#低率更新<br> 返回h
結帳:大型語言模型與洛拉和Qlora的高效微調
讓我們在Llama 3.2 3B型號上實現Lora。
需要庫
- 不塞 - 2024.12.9
- 數據集 - 3.1.0
安裝上述懶惰版本還將安裝兼容的Pytorch,變形金剛和NVIDIA GPU庫。我們可以使用Google Colab訪問GPU。
讓我們現在看一下實施!
導入庫
來自Unsploth Import fastlanguageModel,is_bfloat16_supported,train_on_responses_only 從數據集import load_dataset,數據集 來自TRL導入SFTTrainer,apply_chat_template 從變形金剛導入培訓量,datacollatorforseq2seq,textstreamer 導入火炬
初始化模型和標記器
max_seq_length = 2048 dtype =無#無用於自動檢測。 load_in_4bit = true#使用4bit量化來減少內存使用量。可以是錯誤的。 型號,tokenizer = fastlanguagemodel.from_pretaining( model_name =“ unsploth/llama-3.2-3b-instruct”, max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, #token =“ hf _...”,#如果使用諸如meta-llama/llama-3.2-11b之類的封閉模型 )
對於由Unsploth支持的其他模型,我們可以參考此文檔。
初始化PEFT的模型
model = fastlanguagemodel.get_peft_model(
模型,
r = 16,
target_modules = [“ q_proj”,“ k_proj”,“ v_proj”,“ o_proj”,
“ gate_proj”,“ up_proj”,“ down_proj”,],
lora_alpha = 16,
lora_dropout = 0,
bias =“無”,
use_gradient_checkpointing =“ unsploth”,
Random_State = 42,
use_rslora = false,
loftq_config = none,
)
每個參數的描述
- R :洛拉等級;更高的值提高了精度,但使用更多的內存(建議:8-128)。
- target_modules :微調模塊;包括全部以獲得更好的結果
- lora_alpha :縮放係數;通常等於或兩倍的等級r。
- lora_dropout :輟學率;設置為0進行優化和更快的培訓。
- 偏見:偏見類型; “無”用於速度和最小擬合的優化。
- USE_GRADIENT_CHECKPOINT :減少內存的內存培訓;強烈建議“不塞”。
- Random_State :確定性運行的種子,確保可重複的結果(例如,42)。
- use_rslora :自動選擇alpha選擇;對穩定的洛拉有用。
- LoftQ_Config :用頂部R單數向量初始化Lora,以提高準確性,儘管記憶力很強。
數據處理
我們將使用抹布數據來列出。從HuggingFace下載數據。
dataset = load_dataset(“ neural-bridge/rag-dataset-1200”,split =“ train”)
該數據集的三個鍵如下:
數據集({功能:['context','問題','答案'],num_rows:960})
數據需要根據語言模型為特定格式。在此處閱讀更多詳細信息。
因此,讓我們將數據轉換為所需的格式:
def convert_dataset_to_dict(數據集):
dataset_dict = {
“迅速的”: [],
“完成”:[]
}
對於數據集中的行:
user_content = f“ context:{row ['context']} \ n question:{row ['Question']}”
Assistion_Content =行['答案']
dataset_dict [“提示”]。附錄([[
{“角色”:“用戶”,“ content”:user_content}
)))
dataset_dict [“完成”]。附錄([[
{“角色”:“助手”,“ content”:Assistion_Content}
)))
返回dataset_dict
converted_data = convert_dataset_to_dict(數據集)
dataset = dataset.from_dict(converted_data)
dataset = dataset.map(apply_chat_template,fn_kwargs = {“ tokenizer”:tokenizer})
數據集消息將如下:

設置教練參數
我們可以初始化培訓師以填充SLM:
培訓師= sfttrainer(
模型=模型,
tokenizer = tokenizer,
train_dataset =數據集,
max_seq_length = max_seq_length,
data_collator = datacollatorforseq2seq(tokenizer = tokenizer),
dataset_num_proc = 2,
包裝= false,#可以使短序列更快地訓練5倍。
args = trainingarguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
熱身_Steps = 5,
#num_train_epochs = 1,#設置此設置為1個完整的訓練運行。
max_steps = 6,#使用少量進行測試
Learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim =“ adamw_8bit”,
weight_decay = 0.01,
lr_scheduler_type =“線性”,
種子= 3407,
output_dir =“輸出”,
report_to =“無”,#將其用於wandb等
),
)
某些參數的描述:
- per_device_train_batch_size:每個設備的批量尺寸;增加以利用更多的GPU內存,但請注意填充效率低下(建議:2)。
- gradient_accumulation_steps:模擬較大的批量大小而無需額外的內存使用;增加更順暢的損耗曲線(建議:4)。
- MAX_STEPS:總培訓步驟;設置為更快的運行速度(例如60),或使用`num_train_epochs`用於完整數據集通過(例如,1-3)。
- Learning_rate:控制訓練速度和融合;較低的速率(例如2E-4)提高了準確性,但訓練緩慢。
僅通過指定響應模板才能對響應進行模型訓練:
培訓師= train_on_responses_only( 教練, consition_part =“ user \ n \ n”, response_part =“ 助手 \ n \ n”, )
微調模型
Trainer_stats = Trainer.Train()
這是培訓統計數據:

測試並保存模型
讓我們使用模型進行推理:
fastlanguagemodel.for_inference(模型)
消息= [
{“角色”:“用戶”,“ content”:“上下文:白天通常清晰的天空。問題:水是什麼顏色?”},
這是給出的
inputs = tokenizer.apply_chat_template(
消息,
tokenize = true,
add_generation_prompt = true,
return_tensors =“ pt”,
).to(“ cuda”)
text_streamer = textstreamer(tokenizer,skip_prompt = true)
_ = model.generate(input_ids = inputs,artermer = text_streamer,max_new_tokens = 128,
use_cache = true,溫度= 1.5,min_p = 0.1)
為了節省訓練的訓練,包括洛拉重量,請使用以下代碼
model.save_pretratained_merged(“模型”,Tokenizer,save_method =“ merged_16bit”)
結帳:微調大語言模型指南
結論
用於抹布任務的微調駱駝3.2 3b展示了較小模型在降低計算成本下提供高性能的效率。諸如Lora之類的技術在保持準確性的同時優化了資源使用。這種方法賦予了特定於領域的應用程序,使高級AI更容易訪問,可擴展性和具有成本效益,並在檢索效果的一代中推動了創新,並使AI民主化了現實世界中的挑戰。
另請閱讀:開始使用Meta Llama 3.2
常見問題
Q1。什麼是抹布?A. RAG將檢索系統與生成模型相結合,以通過將其紮根於外部知識來增強回答,從而使其非常適合諸如問答答案和摘要之類的任務。
Q2。為什麼選擇Llama 3.2 3B進行微調?A. Llama 3.2 3b提供了性能,效率和可擴展性的平衡,使其適合於抹布任務,同時減少計算和內存需求。
Q3。洛拉是什麼,如何改善微調?答:低秩適應(LORA)通過僅訓練低級矩陣而不是所有模型參數來最大程度地減少資源使用情況,從而在約束硬件上有效地進行微調。
Q4。在本文中,哪些數據集用於微調?答:擁抱面提供包含上下文,問題和答案的抹布數據集,以微調Llama 3.2 3B模型,以提供更好的任務性能。
Q5。可以將微調模型部署在邊緣設備上嗎?答:是的,Llama 3.2 3b,尤其是以其量化形式的形式,已針對邊緣和移動環境的內存有效部署進行了優化。
以上是微調美洲駝3.2 3b用於抹布 - 分析vidhya的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 易於理解的解釋如何使用ChatGpt提高庫存管理效率!May 14, 2025 am 03:44 AM
易於理解的解釋如何使用ChatGpt提高庫存管理效率!May 14, 2025 am 03:44 AM即使對於中小型企業,易於實施!與Chatgpt和Excel的明智庫存管理 庫存管理是您業務的命脈。儲存過多和庫存的物品對現金流和客戶滿意度有嚴重影響。但是,目前的情況是,在成本方面引入全尺度庫存管理系統很高。 您想關注的是Chatgpt和Excel的組合。在本文中,我們將逐步解釋如何使用此簡單方法簡化庫存管理。 自動化數據分析,需求預測和報告以顯著提高運營效率等任務。而且,
 易於理解的解釋如何檢查和切換chatgpt的版本!May 14, 2025 am 03:43 AM
易於理解的解釋如何檢查和切換chatgpt的版本!May 14, 2025 am 03:43 AM通過選擇chatgpt版本明智地使用AI!對最新信息以及如何檢查的詳盡說明 Chatgpt是一種不斷發展的AI工具,但其功能和性能因版本而異。在本文中,我們將以易於理解的方式解釋每個版本的Chatgpt的功能,如何檢查最新版本以及免費版本和付費版本之間的差異。選擇最佳版本,並充分利用您的AI潛力。 單擊此處以獲取有關Openai最新AI代理OpenAi Deep Research⬇️的更多信息 [chatgpt] openai d
 解釋為什麼您不能將信用卡與Chatgpt的付費計劃一起使用以及如何處理的原因May 14, 2025 am 03:32 AM
解釋為什麼您不能將信用卡與Chatgpt的付費計劃一起使用以及如何處理的原因May 14, 2025 am 03:32 AMChatGPT付費訂閱的信用卡支付故障排除指南 使用ChatGPT付費訂閱時,信用卡支付可能會遇到問題。本文將探討信用卡被拒的原因以及相應的解決方法,從用戶自行解決的問題到需要聯繫信用卡公司的情況,提供詳盡的指南,助您順利使用ChatGPT付費訂閱。 OpenAI發布的最新AI代理,“OpenAI Deep Research”詳情請點擊⬇️ 【ChatGPT】OpenAI Deep Research詳解:使用方法及收費標準 目錄 ChatGPT信用卡支付失敗的原因 原因一:信用卡信息輸入錯誤 原
 易於理解的解釋如何在Chatgpt中創建VBA宏!May 14, 2025 am 02:40 AM
易於理解的解釋如何在Chatgpt中創建VBA宏!May 14, 2025 am 02:40 AM對於初學者和對業務自動化感興趣的人,編寫VBA腳本(Microsoft Office的擴展程序)可能會覺得很困難。但是,ChatGpt使簡化和自動化業務流程變得容易。 本文以易於理解的方式解釋瞭如何使用ChatGpt開發VBA腳本。我們將詳細介紹特定的示例,包括從VBA的基礎到使用ChatGpt集成,測試和調試的所有內容,以及要注意的好處和點。為了提高編程技能並提高業務效率,
 我無法使用ChatGpt插件功能!解釋在錯誤時該怎麼做May 14, 2025 am 01:56 AM
我無法使用ChatGpt插件功能!解釋在錯誤時該怎麼做May 14, 2025 am 01:56 AMChatGPT插件無法使用?這篇指南將幫助您解決問題!您是否遇到過ChatGPT插件無法使用或突然失效的情況? ChatGPT插件是提升用戶體驗的強大工具,但有時也會出現故障。本文將詳細分析ChatGPT插件無法正常工作的原因,並提供相應的解決方法。從用戶設置檢查到服務器故障排查,我們涵蓋了各種故障排除方案,助您高效利用插件完成日常任務。 OpenAI發布的最新AI代理——OpenAI Deep Research,詳情請點擊⬇️ [ChatGPT] OpenAI Deep Research詳解:使
 chatgpt是否不遵循字符計數規範?關於如何處理這個問題的詳盡解釋!May 14, 2025 am 01:54 AM
chatgpt是否不遵循字符計數規範?關於如何處理這個問題的詳盡解釋!May 14, 2025 am 01:54 AM在使用chatgpt編寫句子時,有時您想指定字符數。但是,很難準確預測AI生成的句子的長度,並且匹配指定數量的字符並不容易。 在本文中,我們將解釋如何創建一個句子,其中chatgpt中的字符數量。我們將介紹有效的及時寫作,獲取適合您目的的答案的技術,並教您處理角色限制的技巧。此外,我們將解釋為什麼Chatgpt不擅長指定角色的數量及其工作方式,以及要謹慎和對策的要點。 本文
 關於Python切片操作的所有內容May 14, 2025 am 01:48 AM
關於Python切片操作的所有內容May 14, 2025 am 01:48 AM對於每個Python程序員,無論是在數據科學和機器學習的領域還是軟件開發領域,Python切片操作都是最有效,最多功能和強大的操作之一。 Python切片語法
 易於理解的解釋如何使用Chatgpt創建報價!May 14, 2025 am 01:44 AM
易於理解的解釋如何使用Chatgpt創建報價!May 14, 2025 am 01:44 AMAI技術的發展提高了業務效率。特別引起關注的是使用AI創建估計值。 Openai的AI助理Chatgpt有助於改善估計創建過程並提高準確性。 本文說明瞭如何使用chatgpt創建報價。我們將通過與Excel VBA的合作,系統開發項目的應用,AI實施的好處以及未來的前景來介紹效率提高。了解如何通過Chatgpt提高運營效率和生產力。 OP


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

SublimeText3漢化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript開發工具

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver Mac版
視覺化網頁開發工具

