


jina嵌入式V2:革命性的長期文本嵌入
當前的文本嵌入模型(例如BERT)受到512 token處理限制的限制,從而阻礙了他們的冗長文檔的性能。 這種限制通常會導致背景損失和不准確的理解。 Jina Embeddings V2通過支持8192代幣,保留關鍵環境並顯著提高所處理信息在廣泛文本中的準確性和相關性,從而超過了這一限制。這代表了處理複雜文本數據的重大進步。關鍵學習點
- 在處理長文檔時,了解傳統模型等傳統模型的局限性。
- >學習Jina嵌入式V2如何通過其8192 token的容量和高級體系結構來克服這些限制。
- 在法律研究,內容管理和生成AI中發現現實世界的應用 >在使用擁抱的面部圖書館將Jina Embeddings V2整合到項目中的實用經驗。
- >本文是數據科學博客馬拉鬆的一部分。
表
嵌入長文檔的挑戰建築創新和培訓方法
性能評估- 現實世界應用
- 模型比較
- 使用Jina Embeddings v2與擁抱的臉
- 結論
- 常見問題
- 嵌入長文檔的挑戰
- > 處理長文件在自然語言處理(NLP)中提出了重大挑戰。傳統方法在細分市場中處理文本,導致上下文截斷和碎片嵌入,這些嵌入方式歪曲了原始文檔。這將導致:
增加的計算需求
更高的內存消耗降低了需要全面了解文本的任務的性能
-
Jina Embeddings V2通過將令牌限制提高到
- ,無需過度細分並維護文檔的語義完整性。
- 建築創新和培訓方法
- Jina Embeddings V2通過最先進的創新增強了Bert的功能:
- >帶有線性偏見(alibi)的注意:
- 封閉式線性單元(GLU):
glu,以提高變壓器效率而聞名,用於進料層中。 Geglu和Reglu等變體用於根據模型大小來優化性能。 > 優化培訓: -
>預讀:
- >使用蒙版語言建模(MLM)在巨大的清潔爬行語料庫(C4)上進行訓練。
- > 與文本對進行微調:對語義上相似的文本對的嵌入。 硬性負面微調:
- 通過納入挑戰性的分心示例來改善排名和檢索。 >記憶效率訓練:
- 混合精度訓練和激活檢查點等技術可確保對較大批量尺寸的可伸縮性,對於對比度學習至關重要。
- 在軟瑪克斯操作之前,
m ,使其計算多樣化。 該模型使用編碼器變體,其中所有令牌彼此參與,與語言建模中使用的因果變體不同。
- >在諸如nordationqa之類的任務中擅長,其中完整的文檔上下文至關重要。 > 長文檔處理:
- 即使使用8192 token序列也保持MLM精度。
-
此圖表比較跨檢索和聚類任務的嵌入模型性能。
>現實世界應用程序
- >法律和學術研究:
是搜索和分析法律文件和學術論文的理想選擇。 內容管理系統: - 有效的標記,聚類和大型文檔存儲庫的檢索。 >生成ai:
- >增強了AI生成的摘要和及時的基於及時的模型。 >電子商務: >改進產品搜索和推薦系統。
- > 模型比較
Jina Embeddings V2不僅在處理長序列方面,而且在與OpenAI的Text-ex-embedding-dada-002等專有模型競爭中脫穎而出。 它的開源性質可確保可訪問性。
使用jina嵌入式v2與擁抱的臉步驟1:安裝
>步驟2:使用jina嵌入與變壓器
!pip install transformers !pip install -U sentence-transformers
輸出:
import torch from transformers import AutoModel from numpy.linalg import norm cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b)) model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True) embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?']) print(cos_sim(embeddings, embeddings))處理長序列:

>步驟3:使用jina嵌入與句子轉換器
embeddings = model.encode(['Very long ... document'], max_length=2048)
(提供了使用庫的類似代碼,以及設置的說明。)>
結論sentence_transformersmax_seq_length
Jina Embeddings V2是NLP的重大進步,有效地解決了處理長文件的局限性。 它的功能改善了現有的工作流,並解鎖了使用長形式文本的新可能性。
鍵外觀(原始結論中總結了關鍵點)>
>常見問題
(匯總了常見問題的答案)
注意:圖像以其原始格式和位置保留。 - >法律和學術研究:
績效評估
Jina Embeddings V2在各種基準測試中實現最新性能,包括大量的文本嵌入基準(MTEB)和新的長期數據集。 關鍵結果包括:
分類:
亞馬遜極性和有毒對話分類等任務中的最高準確性。
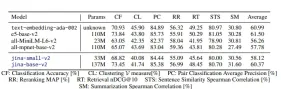
在分組相關文本(PatentClustering和WikicitiesClustering)中優於競爭者。
- 檢索:
 Jina Embeddings V2是NLP的重大進步,有效地解決了處理長文件的局限性。 它的功能改善了現有的工作流,並解鎖了使用長形式文本的新可能性。
Jina Embeddings V2是NLP的重大進步,有效地解決了處理長文件的局限性。 它的功能改善了現有的工作流,並解鎖了使用長形式文本的新可能性。
以上是Jina Embeddings V2:處理長文件很容易的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 嘗試Fellou AI並向Google和Chatgpt說再見May 12, 2025 am 10:26 AM
嘗試Fellou AI並向Google和Chatgpt說再見May 12, 2025 am 10:26 AM在過去的一年中,在線瀏覽的景觀經歷了重大轉變。 這種轉變始於增強,個性化的搜索結果,例如困惑和副駕駛等平台,並隨著Chatgpt的整合而加速了
 個人黑客將是一隻非常兇猛的熊May 11, 2025 am 11:09 AM
個人黑客將是一隻非常兇猛的熊May 11, 2025 am 11:09 AM網絡攻擊正在發展。 通用網絡釣魚電子郵件的日子已經一去不復返了。 網絡犯罪的未來是超個性化的,利用了容易獲得的在線數據和AI來製作高度針對性的攻擊。 想像一個知道您的工作的騙子
 教皇獅子座XIV揭示了AI如何影響他的名字選擇May 11, 2025 am 11:07 AM
教皇獅子座XIV揭示了AI如何影響他的名字選擇May 11, 2025 am 11:07 AM新當選的教皇獅子座(Leo Xiv)在對紅衣主教學院的就職演講中,討論了他的同名人物教皇里奧XIII的影響,他的教皇(1878-1903)與汽車和汽車和汽車公司的黎明相吻合
 Fastapi -MCP初學者和專家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM
Fastapi -MCP初學者和專家教程-Analytics VidhyaMay 11, 2025 am 10:56 AM本教程演示瞭如何使用模型上下文協議(MCP)和FastAPI將大型語言模型(LLM)與外部工具集成在一起。 我們將使用FastAPI構建一個簡單的Web應用程序,並將其轉換為MCP服務器,使您的L
 dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM
dia-1.6b tts:最佳文本到二元格生成模型 - 分析vidhyaMay 11, 2025 am 10:27 AM探索DIA-1.6B:由兩個本科生開發的開創性的文本對語音模型,零資金! 這個16億個參數模型產生了非常現實的語音,包括諸如笑聲和打噴嚏之類的非語言提示。本文指南
 AI可以使指導比以往任何時候都更有意義May 10, 2025 am 11:17 AM
AI可以使指導比以往任何時候都更有意義May 10, 2025 am 11:17 AM我完全同意。 我的成功與導師的指導密不可分。 他們的見解,尤其是關於業務管理,構成了我的信念和實踐的基石。 這種經驗強調了我對導師的承諾
 AI發掘了採礦業的新潛力May 10, 2025 am 11:16 AM
AI發掘了採礦業的新潛力May 10, 2025 am 11:16 AMAI 增强型矿业设备 矿业作业环境恶劣且危险重重。人工智能系统通过将人类从最危险的环境中移除并增强人类能力,帮助提高整体效率和安全性。人工智能越来越多地用于为矿业作业中使用的自动驾驶卡车、钻机和装载机提供动力。 这些 AI 驱动的车辆能够在危险环境中精确作业,从而提高安全性和生产力。一些公司已经开发出用于大型矿业作业的自动驾驶采矿车辆。 在挑战性环境中运行的设备需要持续维护。然而,维护会使关键设备离线并消耗资源。更精确的维护意味着昂贵且必要的设备的正常运行时间增加以及显著的成本节约。 AI 驱动
 為什麼AI代理會觸發25年來最大的工作場所革命May 10, 2025 am 11:15 AM
為什麼AI代理會觸發25年來最大的工作場所革命May 10, 2025 am 11:15 AMSalesforce首席執行官Marc Benioff預測了由AI代理商驅動的巨大的工作場所革命,這是Salesforce及其客戶群中已經進行的轉型。 他設想從傳統市場轉變為一個較大的市場,重點是


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

Dreamweaver Mac版
視覺化網頁開發工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

WebStorm Mac版
好用的JavaScript開發工具

