
LLM抹布:創建一個AI驅動的文件閱讀器助手

- Linda Hamilton原創
- 2025-03-04 10:40:11513瀏覽
簡介
>很難與大型語言模型(LLM)至少每天一次相互作用。聊天機器人在這裡留下來。他們在您的應用程序中,可以幫助您更好地寫作,撰寫電子郵件,閱讀電子郵件……好吧,他們做了很多。
>
>我認為那不是不好的。實際上,我的看法是另一種方式 - 至少到目前為止。我為在我們的日常生活中使用AI的辯護並倡導,因為,讓我們同意,這使一切變得更加容易。>我不必花時間仔細閱讀文檔來查找標點符號問題或類型。 AI為我做到了。我不會在每個星期一浪費時間寫這篇後續電子郵件。 AI為我做到了。當我有AI時,我不需要閱讀一份巨大而無聊的合同來總結我的主要收穫和行動點!
>這些只是AI的一些偉大用途。如果您想了解更多LLM的用例以使我們的生活更輕鬆,那麼我寫了一本關於它們的書。
現在,作為數據科學家並看著技術方面的思考,並不是一切都那麼明亮而有光澤。LLM非常適合適用於任何人或任何公司的幾種普通用例。例如,編碼,匯總或回答有關創建的一般內容的問題,直到培訓截止日期為止。但是,當涉及到特定的業務應用程序,出於單一目的或沒有截止日期的新事物時,那就是如果使用
>“”
> - 意思是,他們將不知道答案。因此,它將需要調整。 培訓LLM型號可能需要數月和數百萬美元。更糟糕的是,如果我們不調整併將模型調整為我們的目的,那麼結果或幻覺就會不令人滿意(當模型的響應鑑於我們的查詢沒有意義時)。
>那麼,解決方案是什麼?花大量的錢再訓練模型包含我們的數據?
不是真的。那時,檢索演示的一代(抹布)變得有用。
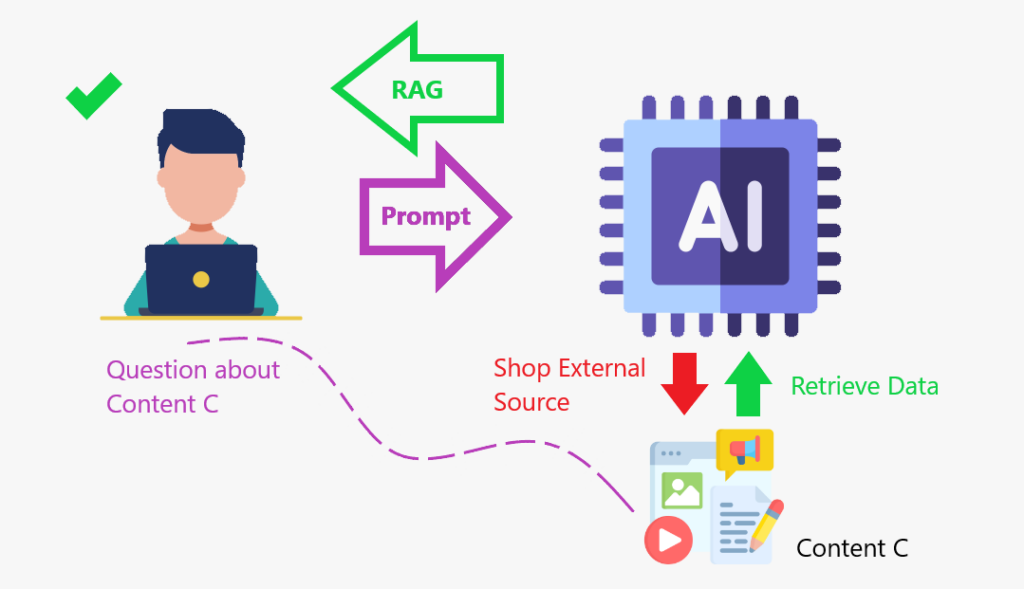
抹布是一個框架,它結合了從外部知識庫中獲取信息與大語言模型(LLMS)的框架。它可以幫助AI模型產生更準確和相關的響應。
讓我們進一步了解接下來的抹布。什麼是抹布?
>讓我告訴你一個故事來說明這個概念。我喜歡電影。過去一段時間以來,我知道哪些電影正在爭奪奧斯卡獎或最好的演員的最佳電影類別。我當然知道那年有哪個雕像。但是現在我對那個主題生鏽了。如果您問我參加比賽的人,我將不知道。即使我試圖回答您,我也會給您一個弱的回應。
>
因此,為了為您提供質量的響應,我將做其他所有人的工作:在線搜索信息,獲取信息,然後將其交給您。我剛剛做的是與抹布相同的想法:我從外部數據庫中獲取了數據以給您一個答案。
我們使用> content Store 增強LLM時,>>檢索數據到
增強>增強(增加)其知識庫,這是行動中的抹布框架。 抹布就像創建一個內容存儲,模型可以增強其知識並更準確地做出響應。
 總結:
總結:
- >使用搜索算法查詢外部數據源,例如數據庫,知識庫和網頁。
- 預處理信息。 >
- 將預處理的信息合併到LLM中。 >
- 為什麼使用抹布?
現在我們知道了抹布框架是什麼
以下是一些好處:>
通過引用真實數據來提高事實準確性。
- rag可以幫助LLMS處理並鞏固知識以創建更多相關的答案
- > rag可以幫助LLM訪問其他知識庫,例如內部組織數據
> rag可以幫助LLM創建更準確的域特異性內容 - 抹布可以幫助減少知識差距和AI幻覺
- 如前所述,我想說的是,使用RAG框架,我們為希望將其添加到知識庫中的內容提供了內部搜索引擎。
- 好。所有這些都非常有趣。但是,讓我們看看抹布的應用。我們將學習如何創建AI驅動的PDF閱讀器助手。
- >項目
該應用程序使用簡化作為前端。
> langchain,OpenAI的GPT-4型號和Faiss(Facebook AI相似性搜索),以進行文檔檢索和問題答案。
>
>讓我們分解步驟以更好地理解:
- >加載PDF文件並將其分成幾塊文本。
- 這使得針對檢索優化了數據
將塊呈現給嵌入工具。
-
- 嵌入是用於以機器可以理解的方式捕獲關係,相似性和含義的數據的數值向量表示。它們被廣泛用於自然語言處理(NLP),推薦系統和搜索引擎。
- >最後,我們將其提供給LLM。
- 數據準備
內容存儲
將採取一些步驟。因此,讓我們從創建一個可以加載文件並將其將其拆分為文本塊以進行有效檢索的函數首先。。 接下來,我們將開始構建我們的簡化應用程序,我們將在下一個腳本中使用該函數。
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks> Web應用程序我們將開始在Python中導入必要的模塊。其中大多數將來自Langchain套餐。
faiss用於文檔檢索; Openaiembeddings將文本塊轉換為數值得分,以通過LLM更好地相似性計算。 Chatopenai是使我們能夠與Openai API互動的原因; create_retrieval_chain實際上是抹布所做的,可以使用該數據檢索和增強LLM; create_stuff_documents_chain膠結模型和chatprompttemplate。
注意:您將需要
生成一個OpenAI鍵才能運行此腳本。如果這是您第一次創建帳戶,那麼您將獲得一些免費的積分。但是,如果您有一段時間,則可能必須添加5美元的學分才能訪問OpenAI的API。一種選擇是使用擁抱的臉部嵌入。 > 這個第一個代碼段將創建應用程序標題,創建一個用於文件上傳的框,然後準備要添加到load_document()function的文件。
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st機器比文本更好地理解數字,因此,最終,我們必須為模型提供一個數字數據庫,在執行查詢時可以比較和檢查是否相似。在下一個代碼中,嵌入對於創建vector_db的地方將很有用。
>
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")接下來,我們創建一個在vector_db中導航的檢索器對象。 然後,我們將創建System_prompt,這是向LLM的一組指令,以了解如何回答,我們將創建一個提示模板,一旦我們從用戶獲得輸入後,就可以將其添加到模型中。
# Generate embeddings # Embeddings are numerical vector representations of data, typically used to capture relationships, similarities, # and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), # recommender systems, and search engines. embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002") # Can also use HuggingFaceEmbeddings # from langchain_huggingface.embeddings import HuggingFaceEmbeddings # embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create vector database containing chunks and embeddings vector_db = FAISS.from_documents(chunks, embeddings)>
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
繼續前進,我們創建了抹布框架的核心,粘貼了獵犬對象和提示。該對象添加了來自數據源(例如,矢量數據庫)的相關文檔,並準備好使用LLM處理以生成響應。
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
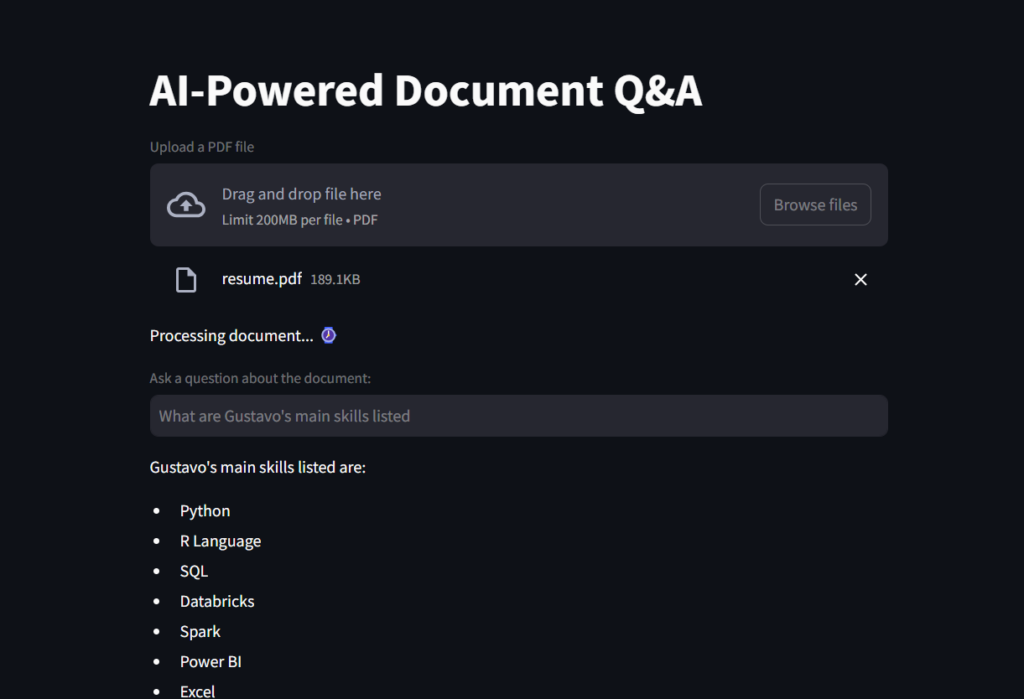
這是結果的屏幕截圖。
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
>這是您可以看到文件讀取器AI助手的GIF!
>
在您去之前 在這個項目中,我們了解了抹布框架是什麼,以及它如何幫助LLM表現更好,並且在特定的知識方面表現良好。
> AI可以從指令手冊,公司的數據庫,某些財務文件或合同的知識中提供動力,然後進行微調以準確地響應特定領域的內容查詢。知識庫是用內容存儲的增強 的。
的。 >
回顧一下,這就是框架的工作方式:>
>1️⃣用戶查詢→輸入文本。
2️⃣檢索相關文檔
→搜索知識庫(例如,數據庫,矢量存儲)。3️⃣增強上下文→檢索的文檔被添加到輸入中。
4️⃣生成響應→a llm處理組合輸入並產生答案。
github存儲庫https://github.com/gurezende/basic-rag 關於我的
如果您喜歡此內容並想了解有關我的工作的更多信息,這是我的網站,您也可以在其中找到我所有的聯繫人。 >
https://gustavorsantos.me參考
> https://cloud.google.com/use-cases/retrieval-aigmented-generation
https://www.ibm.com/think/topics/retrieval-augmented-generate
https://youtu.be/t-d1ofcdw1m?si=g0uwfh5-wznmu0nw
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-get-your-own-own-openai-api-key
以上是LLM抹布:創建一個AI驅動的文件閱讀器助手的詳細內容。更多資訊請關注PHP中文網其他相關文章!