
引入自然語言工具包(NLTK)

- William Shakespeare原創
- 2025-03-01 10:05:09195瀏覽
>自然語言處理(NLP)是人類語言的自動或半自動處理。 NLP與語言學密切相關,並與認知科學,心理學,生理學和數學的研究有聯繫。特別是在計算機科學領域中,NLP與編譯器技術,形式語言理論,人類計算機互動,機器學習和定理證明有關。這個Quora問題顯示了NLP。
的不同優點,在本教程中,我將帶您瀏覽一個有趣的NLP平台,稱為自然語言工具包(NLTK)。在我們查看如何使用此平台之前,讓我首先告訴您NLTK是什麼。
現在安裝NLTK
"Python is a very high-level programming language. Python is interpreted."<br>
word_tokenize()
from nltk.tokenize import word_tokenize
text = "Python is a very high-level programming language. Python is interpreted."<br>print(word_tokenize(text))
['Python', 'is', 'a', 'very', 'high-level', 'programming', 'language', '.', 'Python', 'is', 'interpreted', '.']<br>
方法中。
from nltk.corpus import stopwords<br>print(set(stopwords.words('English')))<br>>請考慮以下文本。
 >讓我們使用word_tokenize()
>讓我們使用word_tokenize()from nltk.corpus import stopwords<br>print(set(stopwords.words('german')))<br>方法來tokenize。輸出:
from nltk.corpus import stopwords<br>from nltk.tokenize import word_tokenize<br><br>text = 'In this tutorial, I\'m learning NLTK. It is an interesting platform.'<br>stop_words = set(stopwords.words('english'))<br>words = word_tokenize(text)<br><br>new_sentence = []<br><br>for word in words:<br> if word not in stop_words:<br> new_sentence.append(word)<br><br>print(new_sentence)<br>您可以從輸出中看到,標點符號也被認為是單詞。它們。以下內容:
 >如何從我們自己的文本中刪除停止單詞?下面的示例顯示了我們如何執行此任務:
>如何從我們自己的文本中刪除停止單詞?下面的示例顯示了我們如何執行此任務:word_tokenize()
word_tokenize()函數是:<code> word_tokenize()<blockquote>將字符串引用以拆分標點符號,而不是</blockquote>
<h3>>搜索</h3> <p>假設我們有以下文本文件(從dropbox下載文本文件)。我們想查找(搜索)單詞<code>language。我們可以簡單地使用NLTK平台進行以下操作:
"Python is a very high-level programming language. Python is interpreted."<br>
在這種情況下,您將獲得以下輸出:
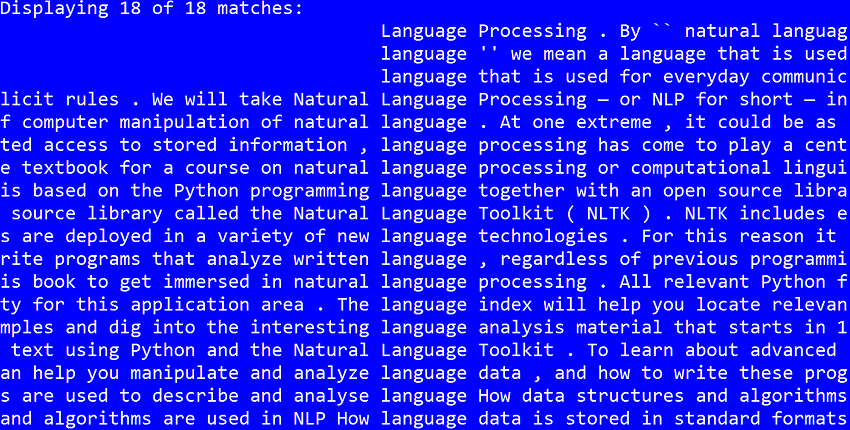
請注意,除了某些上下文中,concordance() language還返回單詞nltk.Text的每一次出現。在此之前,如上面的腳本所示,我們將讀取文件歸為
from nltk.tokenize import word_tokenize>
text = "Python is a very high-level programming language. Python is interpreted."<br>print(word_tokenize(text))
chcp 65001
:
['Python', 'is', 'a', 'very', 'high-level', 'programming', 'language', '.', 'Python', 'is', 'interpreted', '.']<br>
Project Gutenberg(PG)是一項志願者,是為了數字化和歸檔文化作品而努力,以“鼓勵電子書的創建和分佈”。它是由邁克爾·哈特(Michael S. Hart)於1971年成立的,是最古老的數字圖書館。其集合中的大多數項目都是公共領域書籍的全文。該項目試圖以持久的開放格式使它們盡可能免費,幾乎可以在任何計算機上使用。截至2015年10月3日,Gutenberg項目在其收藏中達到了50,000件物品。

>上面腳本的輸出將如下:bryant-stories.txt
from nltk.corpus import stopwords<br>print(set(stopwords.words('English')))<br>如果我們想找到文本文件的單詞數正如我們在本教程中所看到的那樣,55563。我只在本教程中劃過表面。如果您想更深入地將NLTK用於不同的NLP任務,則可以參考NLTK的隨附書:使用Python的自然語言處理。
> >該帖子已通過Esther Vaati的貢獻進行了更新。 Esther是Envato Tuts的軟件開發人員和作者。
以上是引入自然語言工具包(NLTK)的詳細內容。更多資訊請關注PHP中文網其他相關文章!