
為業務計劃和企業家精神制定AI驅動的智能指南

- 王林原創
- 2025-02-25 18:36:11152瀏覽
如果您不是中等成員,則可以在此鏈接上閱讀完整的故事。
>有趣的是,Facebook AI Research(現為Meta AI)的研究人員於2020年發表了第一篇關於RAG的論文,但直到Chatgpt的出現,其潛力才完全實現。從那以後,一直沒有停止。引入了更高級和復雜的抹布框架,不僅提高了該技術的準確性,而且還使其能夠處理多模式數據,從而擴大了其廣泛應用程序的潛力。我在以下文章中詳細介紹了該主題,特別討論了上下文多模式抹布,多模式AI搜索業務應用程序以及信息提取和對接平台。
>將多模式數據集成到大語言模型實時Web搜索以訪問最新信息多模式AI搜索業務應用程序
AI驅動的信息提取和對接>
隨著抹布技術的不斷擴展和新興數據訪問要求的不斷擴展,可以通過整合其他多樣化的知識來源和工具來擴展靜態知識基礎問題的純抹布的功能,從而回答了靜態知識基礎的問題。例如:>多個數據庫(例如,包含向量數據庫和知識圖的知識庫)
>外部API收集特定數據,例如股票市場趨勢或公司特定工具(例如Slack Channels或Email帳戶)的數據
- >諸如數據分析,報告寫作,文獻評論和人員搜索等任務的工具等
- 比較和合併來自多個來源的信息。 >
- 為了實現這一目標,抹布應該能夠根據查詢選擇最佳的知識源和/或工具。 AI代理的出現介紹了“
- 商業和企業家指南作為知識庫,其中包含有關業務計劃,企業家精神,公司註冊,稅收,商業思想,規則和法規,商機,許可證,許可證,商業準則等的信息。 > Web搜索以獲取最新信息。
- 知識提取工具可從受信任來源獲取信息。該信息包括相關當局的聯繫,最近的稅收規則,最新的業務註冊規則以及最近的許可法規。
- **> **以及>專有模型s _( gpt -4O,GPT-4O-MIN_I)在整個代理工作流程中。開源型號不在本地運行,因此不需要強大,昂貴的計算機。取而代之的是,它們在groq cloud的platform上運行,並帶有a> free ap i。是的,這使得它是
cost-fre ** e Admitic rag。 GPT型號也可以使用OpenAI的API鍵選擇。 > >實施知識基礎搜索,Web搜索和混合搜索的選項。 >檢索文檔的評分以提高響應質量,並根據分級智能調用Web搜索。 選擇響應類型的選項:concise , - 中等, 或
- >解釋性 。
-
具體來說,是圍繞以下主題構成的:
> 解析數據以使用Llamaparse 構建知識庫
- >該應用程序的整個代碼可以在github上找到。
- 應用程序代碼在兩個。
- route_after_grading _:基於分級,確定是使用已檢索的文檔構成響應還是繼續進行Web搜索。
- websearch :使用塔維利搜索引擎的API從Web來源獲取信息。
- >生成 :使用提供的上下文對用戶查詢生成響應(從向量存儲和/或Web搜索檢索的信息)。
- _ get_contact_tool _:從與芬蘭移民服務相關的預定義的可信URL中獲取聯繫信息。
- _ get_registration_info_:從芬蘭的公司註冊過程中獲取芬蘭的詳細信息 _
- get_licensing_info _:獲取有關在芬蘭創業所需的許可和許可的信息。 > _
- hybrid_search _:結合文檔檢索和互聯網搜索結果,提供了更廣泛的背景來回答查詢。 >
- >不相關 :處理與工作流的焦點無關的問題
-
這是工作流程中的邊緣。
- _ 檢索→grade_documents _:已將檢索的文檔發送用於分級。
- _ 等級_documents→WebSearch _:如果發現已檢索的文檔無關緊要。 _
- grade_documents→生成_:如果檢索到的文檔相關,則進行響應生成。 >
- > websearch→生成:傳遞Web搜索響應生成的結果。
- _get_contact_tool,get_taxinfo ,_get_registration info,_get_licensinginfo→info→generate生成節點傳遞從特定受信任來源的響應生成的特定信息。
- 生成 :通過響應生成的組合結果(vectorstore websearch)。 > >無關 →
- 生成 :為無關問題提供後備回答。 >圖狀態結構充當維護工作流程狀態的容器,並包括以下元素:
問題
- :用戶的查詢或輸入驅動工作流程。
-
generation
:對用戶查詢的最終生成響應,該響應是在處理後填充的。 _ - web_search_needed _:一個標誌,指示是否基於檢索的文檔的相關性需要Web搜索。
> >文檔 - :與查詢相關的已檢索或處理過的文檔列表。 > _ 答案_Style
- _:指定答案的所需樣式,例如“簡潔”,“中等”或“解釋性”。 圖形結構定義如下: 路由器函數之後的 >分析查詢並將其路由到相關的節點進行處理。創建一個鏈條,包括一個提示,從工具選擇字典和查詢中選擇工具/節點。鏈條調用路由器llm選擇相關工具。
- 與工作流無關的問題路由到_handle不相關的 node,該節點通過
- >啟用語音的搜索和提問,以多種語言(例如俄語,愛沙尼亞語,阿拉伯語等) 選擇響應的不同部分並要求提供更多信息或說明。
- 添加最後一個 n
- 消息數的內存。 > 包括其他方式(例如圖像)在有關的答案中。 >
- 添加更多用於集思廣益,寫作和創意的代理。 >
- >
> node提供了後備響應。
在下圖中描繪了整個工作流程。
>檢索和分級
節點調用了回獵人的問題,該問題是從矢量存儲中獲取相關信息塊的問題。這些塊(“文檔”)發送到_gradedocuments node的節點以對其相關性進行評分。基於分級塊(“ _filtered doc”),_ROUTE_AFTER分級node node決定是否使用檢索到的信息或調用Web搜索來生成。助手函數_initialize_grader鏈用及時引導Grader llm初始化級別鏈,以評估每個塊的相關性。 _grade文檔節點分析每個塊,以確定它是否與問題相關。對於每個塊,它都會輸出“是”或“no”,具體取決於塊是否與問題相關。 Web和Hybrid Search You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
> _web搜索
節點是由_ROUTE_AFTER在檢索信息中找不到相關塊的情況,或者直接通過_route
。_internet_search啟用狀態標誌是“true ”(由無線電選擇用戶界面中的按鈕)或路由器函數決定將查詢路由到_websearch以獲取最新和更多相關的信息。 > 可以通過在他們的網站上創建帳戶來獲得 >文檔”,然後將其傳遞給使用狀態變量的生成node”問題 >混合搜索結合了retriever和tavily搜索的結果,並填充了“> document”的狀態變量,該變量將傳遞給使用“Question ”狀態變量。 調用工具
此代理工作流中使用的工具是從預定義的受信任URL獲取信息的報廢函數。塔維爾(Tavily)和這些工具之間的區別在於,塔維利(Tavily)進行了更廣泛的互聯網搜索,以帶來不同來源的結果。鑑於,這些工具使用Python美麗的湯網報廢庫來從受信任的來源(預定義的URL)中提取信息。這樣,我們確保從已知的,可信賴的來源中提取有關某些查詢的信息。此外,此信息檢索是完全免費的。 > 這是_get_taxinfo
node如何與某些輔助功能一起使用。這種類型的其他工具(節點)也以相同的方式起作用。 >You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
生成響應
節點,生成,通過使用下面描述的預定義提示(langchain's提示> class)調用鏈條來創建最終響應。 _rag提示接收狀態變量_ “響應生成的行為,包括有關響應風格,對話語調,格式指南,引用規則,混合上下文處理和僅上下文重點的說明。 生成節點首先檢索狀態變量“
問題import os from llama_parse import LlamaParse from llama_index.core import SimpleDirectoryReader # Define parsing instructions parsing_instructions = """ Extract the text from the document using proper structure. """ def save_to_markdown(output_path, content): """ Save extracted content to a markdown file. Parameters: output_path (str): The path where the markdown file will be saved. content (list): The extracted content to be saved. """ with open(output_path, "w", encoding="utf-8") as md_file: for document in content: # Extract the text content from the Document object md_file.write(document.text + "nn") # Access the 'text' attribute def extract_document(input_path): # Initialize the LlamaParse parser parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page. """ parser = LlamaParse( result_type="markdown", parsing_instructions=parsing_instructions, premium_mode=True, api_key=LLAMA_CLOUD_API_KEY, verbose=True ) file_extractor = {".pdf": parser} documents = SimpleDirectoryReader( input_path, file_extractor=file_extractor ).load_data() return documents input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name # Extract the document extracted_content = extract_document(input_path) save_to_markdown(output_file, extracted_content)”,“”> documents> ”和“ _answerstyle ”和格式單個字符串作為上下文。隨後,它使用_rag提示調用生成鏈,並且響應生成llm _ 生成“ generatio_n”狀態變量的最終答案。 _app.p_y使用此狀態變量,以在> spartlit 用戶界面中顯示生成的響應。 >使用GROQ的免費API,有可能達到模型的速率或上下文窗口限制。在那種情況下,我將生成的節點擴展到以圓形方式從模型名稱列表中動態切換模型,然後在生成響應後將模型恢復到當前模型。 助手功能
apprag.py 中還有其他幫助功能,用於初始化應用程序,llms,嵌入模型和會話變量。函數_initialize [Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
在應用程序初始化期間從> app.py
調用,並且每當每次通過spreatlitapp更改模型或狀態變量時,都會觸發__。它重新定位組件並保存更新的狀態。此功能還可以跟踪各種會話變量並防止冗餘初始化。 以下助手功能初始化了答案的LLM,嵌入模型,路由器LLM和分級LLM。模型名稱的列表_model列表,用於跟踪模型在模型的動態切換過程中的跟踪>生成> node。
建立工作流def staticChunker(folder_path): docs = [] print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}") # Loop through all .md files in the folder for file_name in os.listdir(folder_path): if file_name.endswith(".md"): file_path = os.path.join(folder_path, file_name) print(f"Processing file: {file_path}") # Load documents from the Markdown file loader = UnstructuredMarkdownLoader(file_path) documents = loader.load() # Add file-specific metadata (optional) for doc in documents: doc.metadata["source_file"] = file_name # Split loaded documents into chunks text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) chunked_docs = text_splitter.split_documents(documents) docs.extend(chunked_docs) return docs現在,使用_route問題的圖形狀態,節點,條件輸入點,並且邊緣被定義為建立節點之間的流程。最後,將工作流彙編為可執行的app,以供在
> spartlitdef load_or_create_vs(persist_directory): # Check if the vector store directory exists if os.path.exists(persist_directory): print("Loading existing vector store...") # Load the existing vector store vectorstore = Chroma( persist_directory=persist_directory, embedding_function=st.session_state.embed_model, collection_name=collection_name ) else: print("Vector store not found. Creating a new one...n") docs = staticChunker(DATA_FOLDER) print("Computing embeddings...") # Create and persist a new Chroma vector store vectorstore = Chroma.from_documents( documents=docs, embedding=st.session_state.embed_model, persist_directory=persist_directory, collection_name=collection_name ) print('Vector store created and persisted successfully!') return vectorstore接口中使用。工作流程中的條件入口點使用_route問題
函數來根據查詢選擇工作流中的第一個節點。條件邊緣(_workflow.add_conditionaledges)描述是否要過渡到
websearch >或生成生成node> node> node> node node基於_grade 確定的塊的相關性Documentsnode You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
流lit接口
> app.py 中的簡化應用程序提供了一個交互式接口,可以使用動態設置來提出問題和顯示響應,以進行模型選擇,答案樣式和特定於查詢的工具。 _initializeapp 函數,從_agenticrag.py導入,初始化所有會話變量,包括所有LLMS,嵌入模型以及從左側欄中選擇的其他選項。 _agentic_rag.p_y中的打印語句通過將
sys.stdout重定向到io.stringiobuffer來捕獲。然後,使用_text區域組件在shatlit。 這是簡化接口的快照:
> import os from llama_parse import LlamaParse from llama_index.core import SimpleDirectoryReader # Define parsing instructions parsing_instructions = """ Extract the text from the document using proper structure. """ def save_to_markdown(output_path, content): """ Save extracted content to a markdown file. Parameters: output_path (str): The path where the markdown file will be saved. content (list): The extracted content to be saved. """ with open(output_path, "w", encoding="utf-8") as md_file: for document in content: # Extract the text content from the Document object md_file.write(document.text + "nn") # Access the 'text' attribute def extract_document(input_path): # Initialize the LlamaParse parser parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page. """ parser = LlamaParse( result_type="markdown", parsing_instructions=parsing_instructions, premium_mode=True, api_key=LLAMA_CLOUD_API_KEY, verbose=True ) file_extractor = {".pdf": parser} documents = SimpleDirectoryReader( input_path, file_extractor=file_extractor ).load_data() return documents input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name # Extract the document extracted_content = extract_document(input_path) save_to_markdown(output_file, extracted_content)以下圖像顯示了由'contise'> contise'
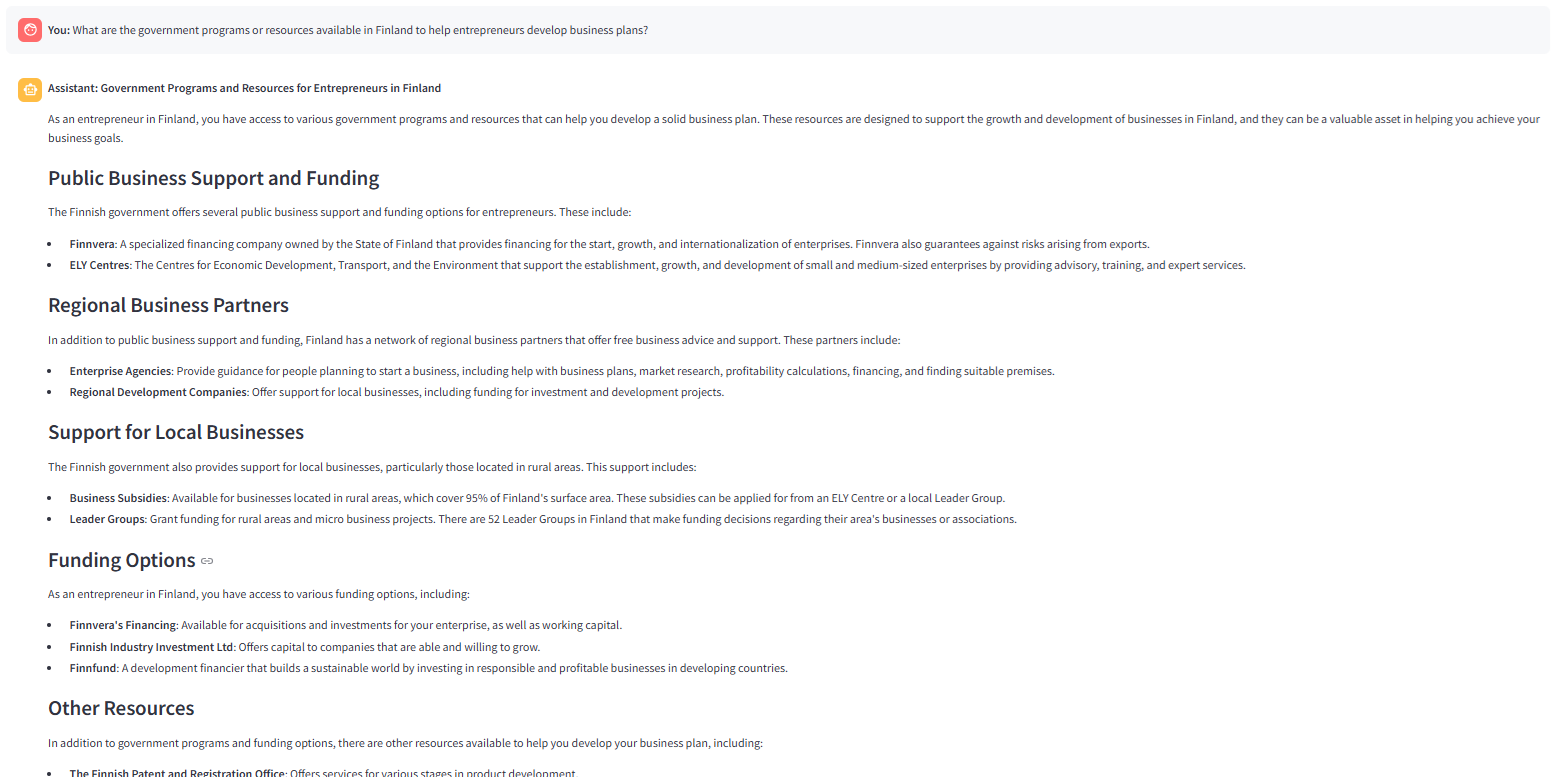
選擇的答案,以選擇答案樣式。查詢路由器(_ROUTE問題)調用referiever(向量搜索),而漸變功能函數可找到所有檢索到的塊相關。因此,一個決定通過生成節點生成答案的決定是由_route_after 分級node。 >下圖顯示了使用'解釋性'答案樣式的答案。按照_rag提示的指示,llm用更多的解釋詳細說明了答案。
下面的圖像顯示了路由器觸發_get_licenseinfo 工具響應問題。
以下圖像顯示了_route_after調用的Web搜索node時,當在矢量搜索中找不到相關塊時。 >以下圖像顯示了在
應用程序中選擇的混合搜索選項生成的響應。 _ROUTE qustionnode找到_internet_search啟用state flag'
truetrue ',然後將問題路由到_hybridsearchnode 。 > node。 >擴展的指示 可以在多個方向上增強此應用程序,例如
> 如果您喜歡這篇文章,請拍拍文章(多次?),寫評論,然後在媒介和LinkedIn上關注我。
>在本文中,我們將開發一個特定的代理RAG應用程序,稱為智能業務指南(SBG) -
>該工具的第一個版本是我們正在進行的項目的一部分樂觀,由中央波羅的海Interreg資助。該項目的重點是使用AI的企業家和業務計劃的芬蘭和愛沙尼亞的高技能移民。 SBG是旨在在該項目的UPSKILLSing過程中使用的工具之一。該工具著重於提供從真實來源到打算開展業務或已經從事業務的人提供精確和快速的信息。SBG的代理抹布包括:
>>這個代理抹布有什麼特殊之處? 選擇>不同的開源模型(
llama,mistral,gemma- )
>使用免費的開源模型開發高級代理抹布(以下稱為智能業務指南或SBG)
文件中結構:_agenticrag.py.py>實現了整個代理工作流程,並且
讓我們深入研究。
>用llamaparsing和langchain
構建知識基礎 SBG的知識基礎包括芬蘭機構發表的真實業務和企業家指南。由於這些指南是龐大的,並且從中找到所需的信息並不是微不足道的,因此目的是開發一個代理抹布,不僅可以從這些指南中提供精確的信息,而且還可以通過網絡搜索和其他可信賴的來源來增強它們。芬蘭以獲取最新信息。Llamaparse是一個由LLM和LLM用例構建的Genai-native文檔解析平台。我已經解釋了在上面引用的文章中使用Llamaparse的使用。這次,我直接在Llamacloud解析了文件。 Llamaparse每天提供1000個免費積分。這些學分的使用取決於解析模式。對於僅文本的PDF,‘
fast'模式(1個學分 / 3頁)效果很好,可以跳過OCR,圖像提取和表格 /標識。還有其他更高級的模式可用,每個頁面的信用點數量更高。我選擇了執行OCR,圖像提取和表/標識的“premium”模式,非常適合具有圖像的複雜文檔。 我定義了以下解析指令。
解析的文件以llamacloud的速度格式下載。可以通過Llamacloud API進行相同的解析。
>You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
這是Pikkala,A。等,(2015)的《指南創造力和業務》中的示例頁面(“
>免費複製以供非商業私人或公共使用,attributionimport os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)>”)。 這是此頁面的解析輸出。 Llamaparse從頁面中的所有結構中有效提取信息。頁面中顯示的筆記本為圖像格式。
 然後使用langchain's
然後使用langchain'srecursivecharactertextsplitter
>[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]>然後將分解的降價文檔分為塊,chunk_size = 3000 = 3000和chunk_overlap = 200.
。 隨後,使用嵌入式模型(例如Open-Source
> ALL-MINILM-L6-V2def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docs模型)或OpenAI'stext-embedding-3-large
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstore>
在下一篇文章中,我解釋了使用langgraph創建代理工作流的過程。
,該節點代表做出決策的工作流程(例如,Web搜索或Vector數據庫搜索)。節點通過>如何使用自動Internet搜索開發免費的AI代理 我們需要創建圖形
nodes
> edges連接,該節點定義了決策和動作的流動(例如,檢索後的下一個狀態是什麼)。圖形state在通過圖移動時跟踪信息,以便代理使用每個步驟的正確數據。
工作流程中的輸入點是一個路由器函數,它通過分析用戶的查詢來確定在工作流中執行的初始節點。整個工作流都包含以下節點。
檢索
- :從矢量店中獲取語義上相似的信息的塊。
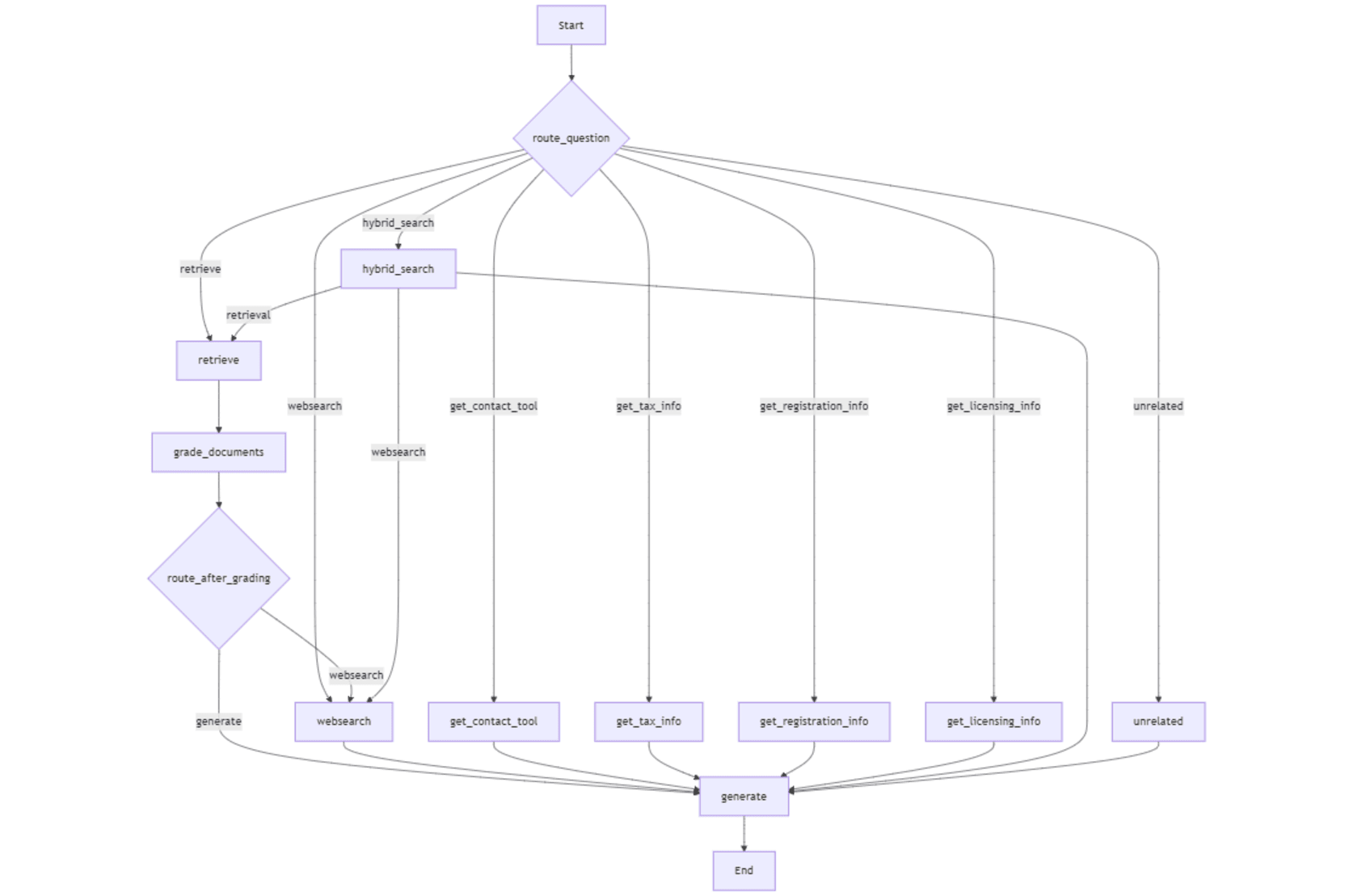
 問題
問題
 調用的Web搜索
調用的Web搜索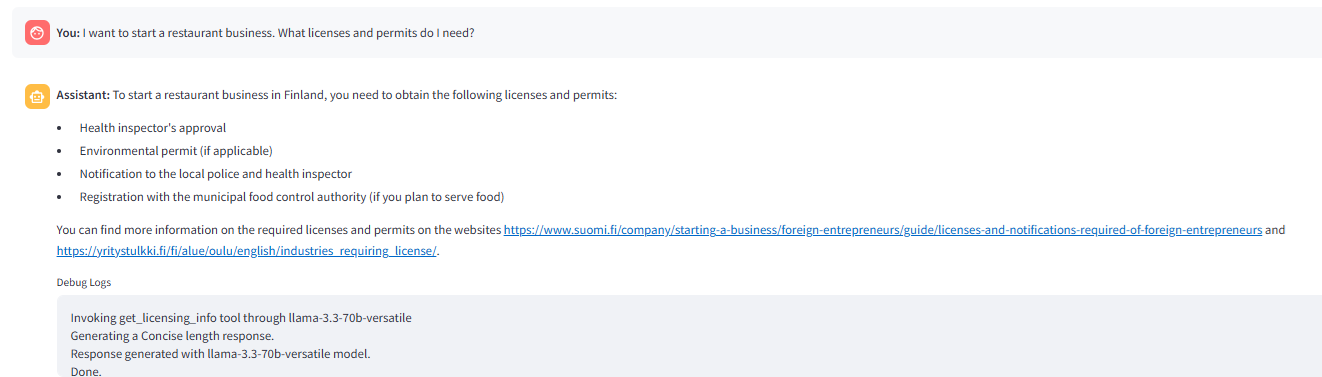 qustion
qustion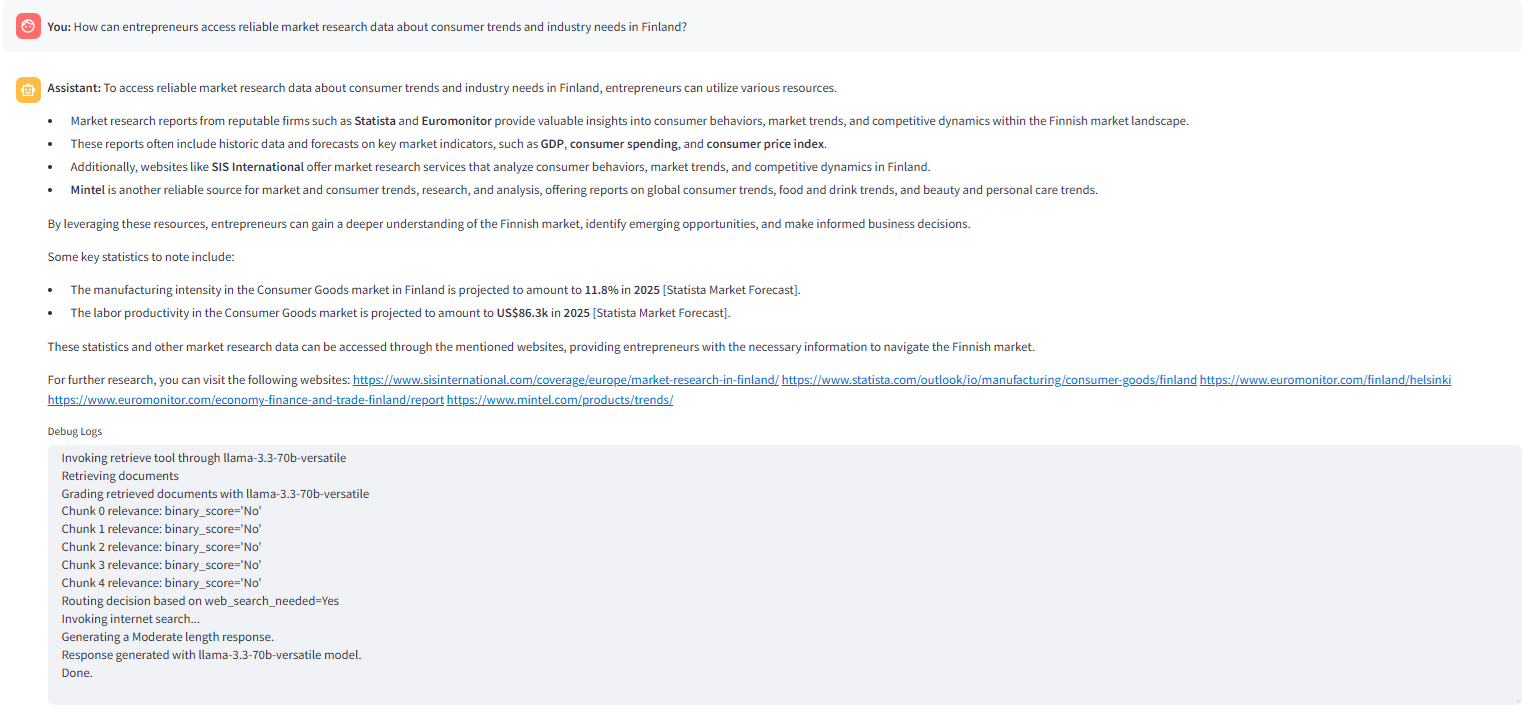 true
true 以上是為業務計劃和企業家精神制定AI驅動的智能指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!