


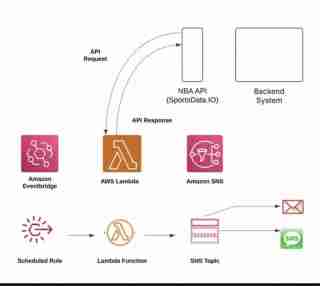
本教學詳細介紹如何使用 AWS 服務、Python 和 DynamoDB 建立自動化 NBA 統計資料管道。 無論您是體育數據愛好者還是 AWS 學習者,這個實踐項目都可以提供現實數據處理的寶貴經驗。
專案概覽
此管道會自動從 SportsData API 擷取 NBA 統計資料、處理資料並將其儲存在 DynamoDB 中。 使用的AWS服務包括:
- DynamoDB:資料儲存
- Lambda:無伺服器執行
- CloudWatch:監控與日誌記錄
先決條件
開始之前,請確保您擁有:
- 基本的 Python 技能
- AWS 帳號
- 已安裝並設定 AWS CLI
- SportsData API 金鑰
項目設定
複製儲存庫並安裝相依性:
git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt
環境配置
使用下列變數在專案根目錄中建立一個 .env 檔案:
<code>SPORTDATA_API_KEY=your_api_key_here AWS_REGION=us-east-1 DYNAMODB_TABLE_NAME=nba-player-stats</code>
專案結構
專案的目錄結構如下:
<code>nba-stats-pipeline/ ├── src/ │ ├── __init__.py │ ├── nba_stats.py │ └── lambda_function.py ├── tests/ ├── requirements.txt ├── README.md └── .env</code>
資料儲存與結構
DynamoDB 架構
管道使用以下架構將 NBA 球隊統計數據儲存在 DynamoDB 中:
- 分割區鍵: TeamID
- 排序鍵:時間戳
- 屬性:球隊統計數據(勝/負、每場比賽得分、會議排名、分區排名、歷史指標)
AWS 基礎設施
DynamoDB 表配置
如下設定 DynamoDB 表:
- 表名稱:
nba-player-stats - 主鍵:
TeamID(字串) - 排序鍵:
Timestamp(數字) - 配置容量:依需求調整
Lambda 函數配置(如果使用 Lambda)
- 運行時:Python 3.9
- 記憶體:256MB
- 超時:30秒
- 處理者:
lambda_function.lambda_handler
錯誤處理與監控
管道包括針對 API 故障、DynamoDB 限制、資料轉換問題和無效 API 回應的強大錯誤處理。 CloudWatch 以結構化 JSON 記錄所有事件,以進行效能監控、調試並確保資料處理成功。
資源清理
完成專案後,清理AWS資源:
git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt
重點
此項目標示:
- AWS 服務整合:有效使用多個 AWS 服務來建立內聚的資料管道。
- 錯誤處理:生產環境中徹底錯誤處理的重要性。
- 監控:日誌記錄和監控在維護資料管道中的重要角色。
- 成本管理: 了解 AWS 資源使用與清理。
未來增強
可能的項目擴充包括:
- 即時遊戲統計整合
- 資料視覺化實作
- 用於資料存取的API端點
- 先進的資料分析能力
結論
此 NBA 統計管道展示了結合 AWS 服務和 Python 來建立功能資料管道的強大功能。對於那些對體育分析或 AWS 數據處理感興趣的人來說,這是寶貴的資源。 分享您的經驗和改進建議!
追蹤更多AWS和Python教學! 欣賞一個❤️和一個?如果您覺得這有幫助!
以上是使用 AWS、Python 和 DynamoDB 建立 NBA 統計管道的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Numpy數組與使用數組模塊創建的數組有何不同?Apr 24, 2025 pm 03:53 PM
Numpy數組與使用數組模塊創建的數組有何不同?Apr 24, 2025 pm 03:53 PMnumpyArraysareAreBetterFornumericalialoperations andmulti-demensionaldata,而learthearrayModuleSutableforbasic,內存效率段
 Numpy數組的使用與使用Python中的數組模塊陣列相比如何?Apr 24, 2025 pm 03:49 PM
Numpy數組的使用與使用Python中的數組模塊陣列相比如何?Apr 24, 2025 pm 03:49 PMnumpyArraySareAreBetterForHeAvyNumericalComputing,而lelethearRayModulesiutable-usemoblemory-connerage-inderabledsswithSimpleDatateTypes.1)NumpyArsofferVerverVerverVerverVersAtility andPerformanceForlargedForlargedAtatasetSetsAtsAndAtasEndCompleXoper.2)
 CTYPES模塊與Python中的數組有何關係?Apr 24, 2025 pm 03:45 PM
CTYPES模塊與Python中的數組有何關係?Apr 24, 2025 pm 03:45 PMctypesallowscreatingingangandmanipulatingc-stylarraysinpython.1)usectypestoInterfacewithClibrariesForperfermance.2)createc-stylec-stylec-stylarraysfornumericalcomputations.3)passarraystocfunctions foreforfunctionsforeffortions.however.however,However,HoweverofiousofmemoryManageManiverage,Pressiveo,Pressivero
 在Python的上下文中定義'數組”和'列表”。Apr 24, 2025 pm 03:41 PM
在Python的上下文中定義'數組”和'列表”。Apr 24, 2025 pm 03:41 PMInpython,一個“列表” isaversatile,mutableSequencethatCanholdMixedDatateTypes,而“陣列” isamorememory-sepersequeSequeSequeSequeSequeRingequiringElements.1)列表
 Python列表是可變還是不變的?那Python陣列呢?Apr 24, 2025 pm 03:37 PM
Python列表是可變還是不變的?那Python陣列呢?Apr 24, 2025 pm 03:37 PMpythonlistsandArraysareBothable.1)列表Sareflexibleandsupportereceneousdatabutarelessmory-Memory-Empefficity.2)ArraysareMoremoremoremoreMemoremorememorememorememoremorememogeneSdatabutlesserversEversementime,defteringcorcttypecrecttypececeDepeceDyusagetoagetoavoavoiDerrors。
 Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AM
Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AMPython和C 各有優勢,選擇應基於項目需求。 1)Python適合快速開發和數據處理,因其簡潔語法和動態類型。 2)C 適用於高性能和系統編程,因其靜態類型和手動內存管理。
 Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM選擇Python還是C 取決於項目需求:1)如果需要快速開發、數據處理和原型設計,選擇Python;2)如果需要高性能、低延遲和接近硬件的控制,選擇C 。
 達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM
達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM通過每天投入2小時的Python學習,可以有效提升編程技能。 1.學習新知識:閱讀文檔或觀看教程。 2.實踐:編寫代碼和完成練習。 3.複習:鞏固所學內容。 4.項目實踐:應用所學於實際項目中。這樣的結構化學習計劃能幫助你係統掌握Python並實現職業目標。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

Dreamweaver Mac版
視覺化網頁開發工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

