
如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求?

- Susan Sarandon原創
- 2025-01-20 10:32:11931瀏覽
如何使用 Node-Fetch API 在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中發出 HTTP 請求
我們目前的網站通常依賴數十種不同的資源,例如圖片、CSS、字體、JavaScript、JSON 資料等的整體集合。然而,世界上第一個網站僅用 HTML 編寫。
JavaScript作為一種優秀的客戶端腳本語言,在網站的發展過程中發揮了重要的作用。借助 XMLHttpRequest 或 XHR 對象,JavaScript 可以實現客戶端和伺服器之間的通信,而無需重新載入頁面。
然而,這個動態過程受到了 Fetch API 的挑戰。什麼是獲取 API?如何在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中使用 Fetch API?為什麼 Fetch API 是更好的選擇?
現在就開始從本文中取得答案!
如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中的 HTTP 請求是什麼?
在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中,HTTP 請求是建立 Web 應用程式或與 Web 服務互動的基本部分。它們允許客戶端(如瀏覽器或其他應用程式)向伺服器發送數據,或從伺服器請求數據。這些請求使用超文本傳輸協定 (HTTP),它是網路資料通訊的基礎。
- HTTP 請求:HTTP 請求由客戶端發送到伺服器,通常用於檢索資料(如網頁或 API 回應)或向伺服器發送資料(如提交表單)。
-
HTTP 方法:HTTP 請求通常包含一個方法,該方法指示客戶端希望伺服器執行什麼操作。常見的 HTTP 方法包括:
- GET:向伺服器請求資料。
- POST:將資料傳送到伺服器(例如,提交表單)。
- PUT:更新伺服器上的現有資料。
- 刪除:從伺服器中刪除資料。
- 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? HTTP 模組:如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 提供了內建的 http 模組來處理 HTTP 請求。此模組使您能夠建立 HTTP 伺服器、偵聽請求並回應它們。
為什麼 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 是網頁抓取和自動化的理想選擇?
如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 憑藉其獨特的特性、強大的生態系統以及非同步、非阻塞架構,已成為網頁抓取和自動化任務的首選技術之一。
為什麼 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 是網頁抓取和自動化的理想選擇?讓我們來弄清楚它們吧!
- 非同步與非阻塞 I/O
- 速度與效率
- 豐富的庫和框架生態系
- 使用無頭瀏覽器處理動態內容
- 跨平台相容性
- 即時數據處理
- 簡單文法,快速開發
- 支援代理輪替與反偵測
什麼是 Node-Fetch API?
Node-fetch 是一個輕量級模組,它將 Fetch API 引入 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 環境。它簡化了發出 HTTP 請求和處理回應的過程。
Fetch API 圍繞 Promises 構建,非常適合非同步操作,例如從網站抓取資料、與 RESTful API 互動或自動化任務。
如何在 Node.JS 中使用 Fetch API?
Fetch API 是一個基於 Promise 的現代接口,與傳統的 XMLHttpRequest 物件相比,旨在以更有效率、更靈活的方式處理網路請求。
當代瀏覽器原生支援它,這意味著不需要額外的函式庫或插件。在本指南中,我們將探討如何利用 Fetch API 執行 GET 和 POST 請求,以及如何有效管理回應和錯誤。
? 注意:如果您的電腦上沒有安裝 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求?,您需要先安裝它。您可以在這裡下載適合您作業系統的如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求?安裝套件。推薦的 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 版本為 18 以上。
步驟 1. 初始化您的 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 項目
如果您還沒有建立項目,可以使用以下命令建立新項目:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
開啟package.json文件,加入type字段,並將其設為module:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
步驟2.下載並安裝node-fetch函式庫
這是一個在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中使用 Fetch API 的函式庫。您可以使用以下命令安裝node-fetch庫:
npm install node-fetch
下載完成後,我們就可以開始使用Fetch API發送網路請求了。在專案根目錄下新檔案index.js,新增以下程式碼:
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
執行以下指令執行程式碼:
node index.js
我們將看到以下輸出:

步驟3.使用Fetch API發送POST請求
如何使用Fetch API發送POST請求?請參考以下方法。在專案根目錄下新檔案post.js,新增以下程式碼:
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
我們來分析這段程式碼:
- 我們先定義一個名為 postData 的對象,其中包含我們要傳送的資料。
- 然後我們使用 fetch 函數向 https://jsonplaceholder.typicode.com/posts 發送 POST 請求,並傳遞一個配置物件作為第二個參數。
- 設定物件包含請求方法、請求標頭和請求正文。
執行以下指令執行程式碼:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
您可以看到的輸出:

步驟 4. 處理 Fetch API 回應結果和錯誤
我們需要在專案根目錄下新建一個檔案response.js,並加入以下程式碼:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
在上面的程式碼中,我們先填入了錯誤的URL位址來觸發HTTP錯誤。然後我們在 then 方法中檢查結果回應的狀態碼,如果狀態碼不是 200 則拋出錯誤。最後,我們在 catch 方法中捕獲錯誤並列印出來。
執行以下指令執行程式碼:
npm install node-fetch
程式碼執行後,您將看到以下輸出:

網頁抓取中的 3 個常見挑戰
1. 驗證碼
CAPTCHA(區分電腦和人類的完全自動化公共圖靈測試)旨在防止網路抓取工具等自動化系統存取網站。它們通常要求使用者透過解決謎題、識別圖像中的物體或輸入扭曲的字元來證明自己是人類。
2. 動態內容
許多現代網站使用 React、Angular 或 Vue.js 等 JavaScript 框架來動態載入內容。這意味著您在瀏覽器中看到的內容通常是在頁面載入後呈現的,因此很難使用依賴靜態 HTML 的傳統方法進行抓取。
3.IP封禁
網站通常會採取措施來偵測和阻止抓取活動,最常見的方法之一是 IP 封鎖。當短時間內從相同 IP 位址發送太多請求時,就會發生這種情況,導致網站標記並封鎖該 IP。
Scrapeless 刮擦工具包 - 高效刮擦工具
Scrapeless 是最好的綜合抓取工具之一,因為它能夠即時繞過網站封鎖,包括 IP 封鎖、CAPTCHA 挑戰和 JavaScript 渲染。它支援 IP 輪換、TLS 指紋管理和驗證碼解決等高級功能,非常適合大規模網頁抓取。
Scrapeless 如何增強 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 網頁抓取專案?
它與 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 的輕鬆整合和避免檢測的高成功率使 Scrapeless 成為繞過現代反機器人防禦的可靠且高效的選擇,確保抓取操作順利且不間斷。
使用 Scrapeless 等抓取工具包相對於手動抓取的優勢
- 高效處理網站屏蔽:Scrapeless 可以即時繞過常見的反抓取防禦,例如 IP 屏蔽、驗證碼和 JavaScript 渲染,而手動抓取無法有效處理這些防禦。
- 可靠性和成功率:Scrapeless 使用 IP 輪換和 TLS 指紋管理等高級功能來避免檢測,與手動抓取相比,確保更高的成功率和不間斷的抓取。
- 輕鬆集成和自動化:與 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 無縫集成,並自動化整個抓取工作流程,與手動資料收集相比,節省時間並減少人為錯誤。
只需遵循一些簡單的步驟,您就可以將 Scrapeless 整合到您的 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 專案中。
是時候繼續滾動了!下面將會更加精彩!
將 Scrapeless Scraping 工具包整合到您的 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 專案中
開始之前,您需要註冊一個Scrapeless帳戶。
步驟 1. 在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中存取 Scrapeless Scraping API
我們需要進入 Scrapeless Dashboard,點擊左側的「Scraping API」選單,然後選擇您要使用的服務。
這裡我們可以使用「亞馬遜」服務

進入Amazon API頁面,我們可以看到Scrapeless為我們提供了三種語言的預設參數和程式碼範例:
- Python
- 走
- 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求?
這裡我們選擇 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 並將程式碼範例複製到我們的專案中:
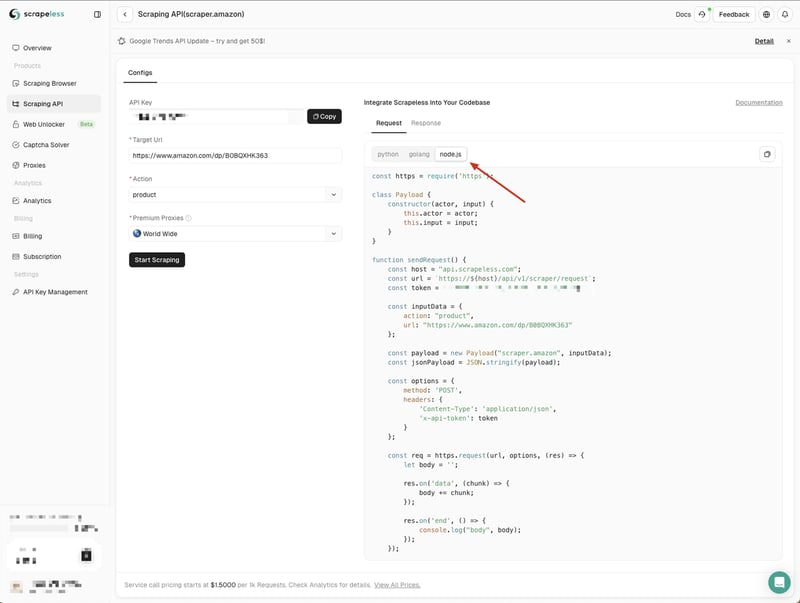
Scrapeless 的 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 程式碼範例預設使用 http 模組。我們可以使用node-fetch模組來取代http模組,這樣我們就可以使用Fetch API來發送網路請求了。
首先在我們的專案中建立一個 scraping-api-amazon.js 文件,然後將 Scrapeless 提供的程式碼範例替換為以下程式碼範例:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
透過執行以下指令來執行程式碼:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
我們將看到 Scrapeless API 傳回的結果。這裡我們只是將它們列印出來。您可以根據需要對傳回結果進行處理。

步驟 2. 利用 Web Unlocker 繞過常見的反抓取措施
Scrapeless提供了Web解鎖器服務,可以幫助您繞過常見的反抓取措施,如驗證碼繞過、IP封禁等。 Web解鎖器服務可以幫助您解決一些常見的爬取問題,讓您的爬行任務更加順利。
為了驗證Web解鎖服務的有效性,我們可以先使用curl命令訪問需要驗證碼的網站,然後使用Scrapeless Web解鎖服務訪問同一網站,看看驗證碼是否能夠成功繞過。
- 使用curl指令造訪需要驗證碼的網站,如https://identity.getpostman.com/login:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
透過查看回傳結果,可以看到網站已連接到Cloudflare驗證機制,需要輸入驗證碼才能繼續造訪該網站。

- 我們使用Scrapeless Web解鎖服務來造訪相同網站:
- 前往無刮擦儀表板
- 點選左側的 Web 解鎖器選單

- 將 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 程式碼範例複製到我們的專案
在這裡我們建立一個新的 web-unlocker.js 檔案。我們仍然需要使用node-fetch模組來發送網路請求,所以我們需要將Scrapeless提供的程式碼範例中的http模組替換為node-fetch模組:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
執行以下命令來執行腳本:
npm install node-fetch


看! Scrapeless Web解鎖器成功繞過驗證碼,我們可以看到回傳結果包含了我們需要的網頁內容。
常見問題解答
Q1. Node-Fetch 與 Axios:哪個比較適合網頁抓取?
為了讓您的選擇更方便,Axios 和 Fetch API 有以下差異:
- Fetch API 使用請求的 body 屬性,而 Axios 使用 data 屬性。
- 使用 Axios 可以直接傳送 JSON 數據,而 Fetch API 則需要轉換為字串。
- axios可以直接處理JSON。 Fetch API 需要先呼叫response.json()方法來取得JSON格式的回應。
- 對axios來說,回應資料變數名稱必須是data;對於 Fetch API,回應資料變數名稱可以是任何內容。
- Axios 允許使用進度事件輕鬆監控和更新進度。 Fetch API 中沒有直接的方法。
- Fetch API 不支援攔截器,而 Axios 支援。
- Fetch API 允許串流回應,而 Axios 則不允許。
Q2。節點獲取穩定嗎?
Node 最顯著的特性。 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? v21 是 Fetch API 的穩定性。
Q3。 Fetch API 比 AJAX 好嗎?
對於新項目,建議使用 Fetch API,因為它具有現代功能且簡單。但是,如果您需要支援非常舊的瀏覽器或維護遺留程式碼,Ajax 可能仍然是必要的。
底線
如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中加入 Fetch API 是一個期待已久的功能。在 如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求? 中使用 Fetch API 可以確保您的抓取工作輕鬆完成。但使用 Node Fetch API 時難免會遇到嚴重的網路阻塞
以上是如何使用 Node-Fetch API 在 Node.js 中發出 HTTP 請求?的詳細內容。更多資訊請關注PHP中文網其他相關文章!