
如何使用 Python 抓取 Target.com 評論

- DDD原創
- 2025-01-06 06:41:41568瀏覽
介紹
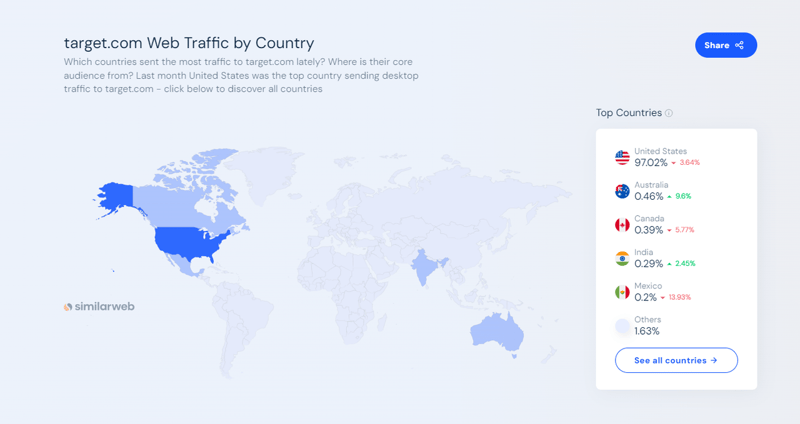
Target.com 是美國最大的電子商務和購物市場之一。它允許消費者在網上和店內購買從雜貨和必需品到服裝和電子產品的所有商品。截至2024年9月,根據SimilarWeb的數據,Target.com每月吸引的網路流量超過1.66億。
Target.com 網站提供顧客評論、動態定價資訊、產品比較和產品評級等。對於想要追蹤產品趨勢、監控競爭對手價格或透過評論分析客戶情緒的分析師、行銷團隊、企業或研究人員來說,它是寶貴的數據來源。
在本文中,您將學習如何:
- 設定並安裝 Python、Selenium 和 Beautiful Soup 進行網頁抓取
- 使用 Python 從 Target.com 抓取產品評論和評分
- 使用ScraperAPI有效繞過Target.com的反抓取機制
- 實施代理以避免 IP 禁令並提高抓取效能
在本文結束時,您將了解如何使用 Python、Selenium 和 ScraperAPI 從 Target.com 收集產品評論和評分而不被封鎖。您還將學習如何使用抓取的資料進行情緒分析。
如果您在我編寫本教學時感到興奮,那麼讓我們直接開始吧。 ?
TL;DR:抓取目標產品評論 [完整程式碼]
對於那些趕時間的人,這是我們將在本教程的基礎上構建的完整程式碼片段:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
查看 GitHub 上的完整程式碼:https://github.com/Eunit99/target_com_scraper。想理解每一行程式碼嗎?讓我們一起從頭開始建立網頁抓取工具!
如何使用 Python 與 ScraperAPI 抓取 Target.com 評論
在先前的文章中,我們介紹了抓取 Target.com 產品資料所需了解的所有內容。不過,在本文中,我將重點放在如何使用 Python 和 ScraperAPI 抓取 Target.com 的產品評分和評論。
先決條件
要遵循本教學並開始抓取 Target.com,您需要先執行一些操作。
1. 擁有 ScraperAPI 帳戶
從 ScraperAPI 上的免費帳戶開始。 ScraperAPI 可讓您使用我們易於使用的 Web 抓取 API 開始從數百萬個 Web 來源收集數據,而無需複雜且昂貴的解決方法。
ScraperAPI 甚至可以解鎖最困難的網站,降低基礎設施和開發成本,讓您更快地部署網頁抓取工具,並且還為您提供 1,000 個免費 API 積分以供您首先嘗試,等等。
2. 文字編輯器或IDE
使用程式碼編輯器,例如Visual Studio Code。其他選項包括 Sublime Text 或 PyCharm。
3. 專案要求和虛擬環境設置
開始抓取 Target.com 評論之前,請確保您具備以下條件:
- 您的電腦上安裝了 Python(版本 3.10 或更高版本)
- pip(Python 套件安裝程式)
最佳實踐是為 Python 專案使用虛擬環境來管理依賴關係並避免衝突。
要建立虛擬環境,請在終端機中執行以下命令:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
4. 啟動虛擬環境
根據您的作業系統啟動虛擬環境:
python3 -m venv env
有些IDE可以自動啟動虛擬環境。
5. 對 CSS 選擇器和導覽瀏覽器開發工具有基本的了解
為了有效地理解本文,必須對 CSS 選擇器有基本的了解。 CSS 選擇器用於定位網頁上的特定 HTML 元素,它允許您提取所需的資訊。
此外,熟悉瀏覽器開發工具對於檢查和識別網頁結構至關重要。
項目設定
滿足上述先決條件後,就可以開始設定您的項目了。首先建立一個包含 Target.com 抓取工具原始碼的資料夾。在這種情況下,我將我的資料夾命名為 python-target-dot-com-scraper。
執行下列指令建立名為 python-target-dot-com-scraper 的資料夾:
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
進入資料夾並透過執行以下命令建立新的 Python main.py 檔案:
mkdir python-target-dot-com-scraper
透過執行以下指令建立requirements.txt 檔案:
cd python-target-dot-com-scraper && touch main.py
在本文中,我將使用 Selenium 和 Beautiful Soup 以及 Python 庫的 Webdriver Manager 來建立網頁抓取工具。 Selenium 將處理瀏覽器自動化,Beautiful Soup 庫將從 Target.com 網站的 HTML 內容中提取資料。同時,Python 的 Webdriver Manager 提供了一種自動管理不同瀏覽器驅動程式的方法。
將以下行新增至您的requirements.txt 檔案中以指定必要的套件:
touch requirements.txt
要安裝軟體包,請執行以下命令:
selenium~=4.25.0 bs4~=0.0.2 python-dotenv~=1.0.1 webdriver_manager selenium-wire blinker==1.7.0 python-dotenv==1.0.1
使用 Selenium 提取 Target.com 產品評論
在本節中,我將引導您逐步了解如何從 Target.com 的產品頁面(例如 Target.com)取得產品評級和評論。
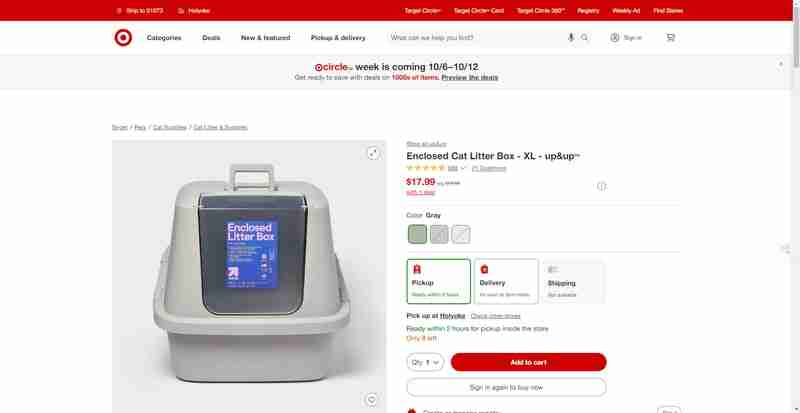
我將專注於以下螢幕截圖中突出顯示的網站這些部分的評論和評級:
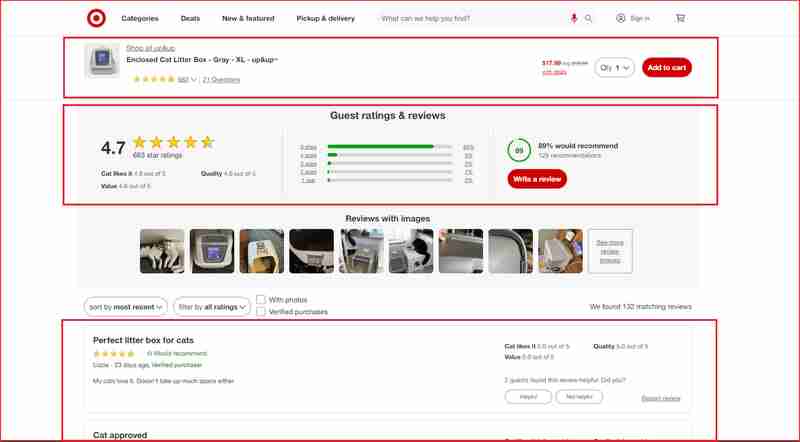
在進一步深入研究之前,您需要了解 HTML 結構並識別與包裝我們要提取的資訊的 HTML 標籤關聯的 DOM 選擇器。在下一節中,我將引導您使用 Chrome DevTools 來了解 Target.com 的網站架構。
使用 Chrome DevTools 了解 Target.com 的網站架構
按 F12 或右鍵單擊頁面上的任何位置並選擇“檢查”,開啟 Chrome DevTools。從上面的 URL 檢查頁面會發現以下內容:
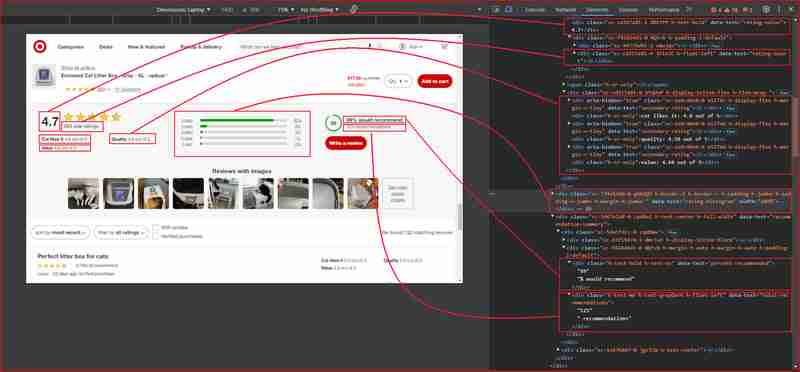
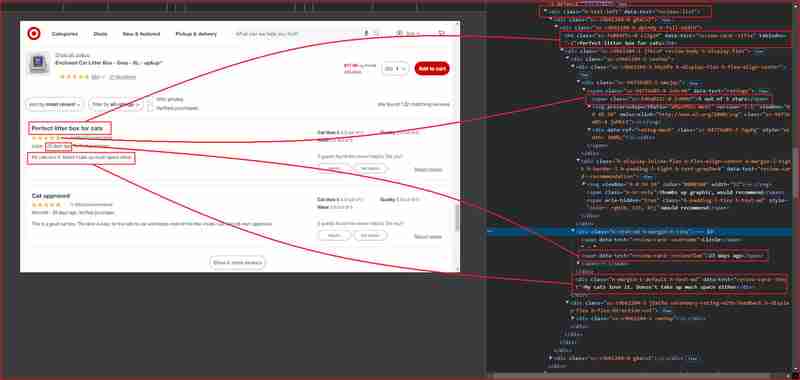
從上面的圖片中,以下是網頁抓取工具將用於提取資訊的所有 DOM 選擇器:
| Information | DOM selector | Value |
|---|---|---|
| Product ratings | ||
| Rating value | div[data-test='rating-value'] | 4.7 |
| Rating count | div[data-test='rating-count'] | 683 star ratings |
| Secondary rating | div[data-test='secondary-rating'] | 683 star ratings |
| Rating histogram | div[data-test='rating-histogram'] | 5 stars 85%4 stars 8%3 stars 3%2 stars 1%1 star 2% |
| Percent recommended | div[data-test='percent-recommended'] | 89% would recommend |
| Total recommendations | div[data-test='total-recommendations'] | 125 recommendations |
| Product reviews | ||
| Reviews list | div[data-test='reviews-list'] | Returns children elements corresponding to individual product review |
| Review card title | h4[data-test='review-card--title'] | Perfect litter box for cats |
| Ratings | span[data-test='ratings'] | 4.7 out of 5 stars with 683 reviews |
| Review time | span[data-test='review-card--reviewTime'] | 23 days ago |
| Review card text | div[data-test='review-card--text'] | My cats love it. Doesn't take up much space either |
建立你的目標評論刮刀
現在我們已經概述了所有要求,並在 Target.com 產品評論頁面上找到了我們感興趣的不同元素。我們將進入下一步,導入必要的模組:
1. 導入Selenium等模組
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
在此程式碼中,每個模組都有特定的用途來建立我們的網頁抓取工具:
- os 處理 API 金鑰等環境變數。
- 時間會在頁面載入過程中引入延遲。
- dotenv 從 .env 檔案載入 API 金鑰。
- selenium 支援瀏覽器自動化和互動。
- webdriver_manager 自動安裝 ChromeDriver。
- BeautifulSoup 解析 HTML 以擷取資料。
- seleniumwire 管理抓取代理,無需 IP 禁令。
2. 設定網路驅動程式
在此步驟中,您將初始化 Selenium 的 Chrome WebDriver 並設定重要的瀏覽器選項。這些選項包括停用不必要的功能以提高效能、設定視窗大小和管理日誌。您將使用 webdriver.Chrome() 實例化 WebDriver,以在整個抓取過程中控制瀏覽器。
python3 -m venv env
建立滾動到底部功能
在本節中,我們建立一個滾動整個頁面的函數。 Target.com 網站在使用者向下捲動時動態載入其他內容(例如評論)。
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
scroll_down_page() 函數逐漸滾動網頁一定數量的像素(距離),每次滾動之間有短暫的暫停(延遲)。它首先計算頁面的總高度並向下滾動直到到達底部。當它滾動時,總頁面高度會動態更新,以適應在此過程中可能加載的新內容。
將 Selenium 與 BeautifulSoup 結合起來
在本節中,我們結合 Selenium 和 BeautifulSoup 的優勢來創建高效可靠的網頁抓取設定。雖然 Selenium 用於與動態內容交互,例如載入頁面和處理 JavaScript 渲染元素,但 BeautifulSoup 在解析和提取靜態 HTML 元素方面更有效。我們首先使用 Selenium 導航網頁並等待載入特定元素,例如產品評級和評論計數。這些元素是使用 Selenium 的 WebDriverWait 函數提取的,該函數可確保資料在捕獲之前是可見的。然而,僅透過 Selenium 處理個人評論可能會變得複雜且低效。
使用 BeautifulSoup,我們簡化了循環瀏覽頁面上多個評論的過程。一旦 Selenium 完全加載頁面,BeautifulSoup 就會解析 HTML 內容以有效地提取評論。使用 BeautifulSoup 的 select() 和 select_one() 方法,我們可以導覽頁面結構並收集每個評論的標題、評分、時間和文字。與單獨透過 Selenium 管理所有內容相比,這種方法可以更清晰、更結構化地抓取重複元素(例如評論清單),並在處理 HTML 方面提供更大的靈活性。
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
在 Python Selenium 中使用代理:與無頭瀏覽器的複雜交互
抓取複雜網站時,尤其是那些具有強大反機器人措施(例如 Target.com)的網站時,經常會出現 IP 禁令、速率限製或訪問限制等挑戰。使用 Selenium 執行此類任務會變得很複雜,尤其是在部署無頭瀏覽器時。無頭瀏覽器允許在沒有 GUI 的情況下進行交互,但在這種環境中手動管理代理變得具有挑戰性。您必須配置代理設定、輪換 IP 並處理 JavaScript 渲染等其他交互,這使得抓取速度變慢且容易失敗。
相較之下,ScraperAPI 透過自動管理代理程式顯著簡化了此流程。 ScraperAPI 的代理模式不是在 Selenium 中處理手動配置,而是跨多個 IP 位址分發請求,確保更順暢的抓取,而無需擔心 IP 禁令、速率限製或地理限制。當使用無頭瀏覽器時,這變得特別有用,因為處理動態內容和複雜的網站互動需要額外的編碼。
使用 Selenium 設定 ScraperAPI
透過使用 Selenium Wire(一種允許輕鬆進行代理設定的工具),可以簡化 ScraperAPI 代理模式與 Selenium 的整合。這是一個快速設定:
- 註冊 ScraperAPI:建立帳戶並檢索您的 API 金鑰。
- 安裝 Selenium Wire:透過執行 pip install selenium-wire 將標準 Selenium 替換為 Selenium Wire。
- 設定代理程式:在 WebDriver 設定中使用 ScraperAPI 的代理程式池來輕鬆管理 IP 輪調。
整合後,此配置可以實現與動態頁面、自動輪換 IP 位址和繞過速率限制的更順暢交互,而無需在無頭瀏覽器環境中手動管理代理的麻煩。
下面的程式碼片段示範如何在 Python 中設定 ScraperAPI 的代理程式:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
透過此設置,發送到 ScraperAPI 代理伺服器的請求將被重定向到 Target.com 網站,從而隱藏您的真實 IP,並針對 Target.com 網站反抓取機制提供強大的防禦。也可以透過包含用於 JavaScript 渲染的 render=true 等參數或指定用於地理位置的國家/地區程式碼來自訂代理程式。
從 Target.com 抓取評論數據
下面的 JSON 程式碼是使用 Target Reviews Scraper 的回應範例:
python3 -m venv env
如何使用我們的 Cloud Target.com 評論 Scraper
如果您想在不設定環境、不知道如何編碼或設定代理的情況下快速獲得 Target.com 評論,您可以使用我們的 Target Scraper API 免費取得所需的資料。 Target Scraper API 託管在 Apify 平台上,無需設定即可使用。
前往 Apify 並點擊「免費試用」立即開始。

使用目標評論進行情感分析
現在您已經有了 Target.com 評論和評級數據,是時候了解這些數據了。這些評論和評級數據可以提供有關客戶對特定產品或服務的看法的寶貴見解。透過分析這些評論,您可以識別常見的讚揚和投訴,衡量客戶滿意度,預測未來的行為,並將這些評論轉化為可行的見解。
作為行銷專業人士或企業主,尋求更好地了解主要受眾並改善行銷和產品策略的方法。您可以透過以下一些方法將這些數據轉化為可行的見解,以優化行銷工作、改進產品策略並提高客戶參與度:
- 完善產品供應:識別常見的客戶投訴或讚揚,以微調產品功能。
- 改善顧客服務:及早發現負面評論以解決問題並維持顧客滿意度。
- 優化行銷活動:利用正向回饋中的見解來制定個人化、有針對性的活動。
透過使用 ScraperAPI 大規模收集大規模評論數據,您可以自動化和擴展情緒分析,從而實現更好的決策和成長。
抓取目標產品評論的常見問題解答
抓取 Target.com 產品頁面是否合法?
是的,從 Target.com 獲取公開資訊(例如產品評級和評論)是合法的。但重要的是要記住,這些公共資訊可能仍然包含個人詳細資訊。
我們寫了一篇關於網頁抓取的法律面向和道德考慮的部落格文章。您可以在那裡了解更多。
Target.com 會封鎖抓取工具嗎?
是的,Target.com 實作了各種反抓取措施來阻止自動抓取。其中包括 IP 封鎖、速率限制和驗證碼挑戰,所有這些都旨在檢測和阻止來自抓取工具或機器人的過多自動請求。
如何避免被 Target.com 封鎖?
為了避免被 Target.com 屏蔽,您應該減慢請求速度、輪換用戶代理、使用驗證碼解決技術,並避免發出重複或高頻請求。將這些方法與代理程式結合有助於降低檢測的可能性。
此外,請考慮使用專用抓取工具(例如 Target Scraper API 或 Scraping API)來繞過這些 Target.com 限制。
我需要使用代理程式來抓取 Target.com 嗎?
是的,使用代理程式對於有效抓取 Target.com 至關重要。代理有助於跨多個 IP 位址分發請求,最大限度地減少被封鎖的可能性。 ScraperAPI 代理程式隱藏您的 IP,讓反抓取系統更難以偵測您的活動。
總結
在本文中,您學習如何使用 Python、Selenium 建立 Target.com 評分和評論抓取工具,並使用 ScraperAPI 有效繞過 Target.com 的反抓取機制,避免 IP 封鎖並提高抓取效能。
使用此工具,您可以有效可靠地收集有價值的客戶回饋。
收集完這些數據後,下一步就是使用情緒分析來發現關鍵洞見。透過分析客戶評論,您作為企業可以確定產品優勢、解決痛點並優化行銷策略,以更好地滿足客戶需求。
透過使用 Target Scraper API 進行大規模資料收集,您可以持續監控評論並在了解客戶情緒方面保持領先地位,從而使您能夠完善產品開發並創建更有針對性的行銷活動。
立即嘗試 ScraperAPI 進行無縫大規模資料擷取或使用我們的 Cloud Target.com Reviews Scraper!
欲了解更多教學和精彩內容,請在 Twitter (X) @eunit99 上關注我
以上是如何使用 Python 抓取 Target.com 評論的詳細內容。更多資訊請關注PHP中文網其他相關文章!