


作者:特里克斯·賽勒斯
Waymap滲透測試工具:點這裡
TrixSec Github:點這裡
TrixSec Telegram:點此
開始使用人工智慧和機器學習需要準備充分的開發環境。本文將引導您設定 AI/ML 之旅所需的工具和函式庫,確保初學者順利起步。我們還將為那些想要避免複雜的本地設定的人討論 Google Colab 等線上平台。
AI/ML 開發的系統需求
在深入研究人工智慧和機器學習專案之前,必須確保您的系統能夠處理運算需求。雖然大多數基本任務可以在標準機器上運行,但更高級的專案(例如深度學習)可能需要更好的硬體。以下是根據專案複雜性劃分的系統需求:
1.對於初學者:小項目和學習
- 作業系統: Windows 10/11、macOS 或任何現代 Linux 發行版。
- 處理器:雙核心CPU(Intel i5或AMD同等產品)。
- RAM: 8 GB(最低);建議使用 16 GB,以實現更流暢的多工處理。
-
儲存:
- 20 GB 可用空間用於 Python、函式庫和小型資料集。
- 強烈建議使用 SSD,以獲得更快的效能。
- GPU(顯示卡): 不需要; CPU 足以滿足基本的 ML 任務。
- 網路連線:下載庫、資料集和使用雲端平台所需。
2.對於中間項目:更大的資料集
- 處理器: 四核心 CPU(Intel i7 或 AMD Ryzen 5 同等產品)。
- RAM: 至少 16 GB;對於大型資料集,建議使用 32 GB。
-
儲存:
- 50–100 GB 可用空間用於資料集和實驗。
- SSD 用於快速資料載入和操作。
-
GPU:
- 具有至少 4 GB VRAM 的專用 GPU(例如 NVIDIA GTX 1650 或 AMD Radeon RX 550)。
- 對於訓練較大的模型或試驗神經網路很有用。
- 顯示:雙顯示器可以提高模型除錯和視覺化過程中的工作效率。
3.對於高階專案:深度學習與大型模型
- 處理器:高效能CPU(Intel i9或AMD Ryzen 7/9)。
- RAM: 32–64 GB,用於處理記憶體密集操作和大型資料集。
-
儲存:
- 1 TB 或更多(強烈建議使用 SSD)。
- 資料集可能需要外部儲存。
-
GPU:
- 由於 CUDA 支持,NVIDIA GPU 是深度學習的首選。
- 建議:NVIDIA RTX 3060 (12 GB VRAM) 或更高版本(例如 RTX 3090、RTX 4090)。
- 預算選項:NVIDIA RTX 2060 或 RTX 2070。
-
冷氣與電源:
- 確保 GPU 適當冷卻,尤其是在長時間訓練期間。
- 可靠的電源支援硬體。
4.雲端平台:如果您的系統無法達到要求
如果您的系統不符合上述規格或您需要更多運算能力,請考慮使用雲端平台:
- Google Colab: 免費,可使用 GPU(可升級至 Colab Pro,以獲得更長的運行時間和更好的 GPU)。
- AWS EC2 或 SageMaker: 適用於大型 ML 專案的高效能執行個體。
- Azure ML 或 GCP AI Platform: 適合企業級專案。
- Kaggle Kernels: 免費用於較小資料集的實驗。
基於用例的建議設定
| Use Case | CPU | RAM | GPU | Storage |
|---|---|---|---|---|
| Learning Basics | Dual-Core i5 | 8–16 GB | None/Integrated | 20–50 GB |
| Intermediate ML Projects | Quad-Core i7 | 16–32 GB | GTX 1650 (4 GB) | 50–100 GB |
| Deep Learning (Large Models) | High-End i9/Ryzen 9 | 32–64 GB | RTX 3060 (12 GB) | 1 TB SSD |
| Cloud Platforms | Not Required Locally | N/A | Cloud GPUs (e.g., T4, V100) | N/A |
第 1 步:安裝 Python
Python 因其簡單性和龐大的庫生態系統而成為 AI/ML 的首選語言。安裝方法如下:
-
下載Python:
- 造訪 python.org 並下載最新的穩定版本(最好是 Python 3.9 或更高版本)。
-
安裝Python:
- 按照適合您的作業系統(Windows、macOS 或 Linux)的安裝步驟進行操作。
- 確保在安裝過程中選取將 Python 新增至 PATH 選項。
-
驗證安裝:
- 開啟終端機並輸入:
python --version
您應該會看到已安裝的 Python 版本。
第 2 步:設定虛擬環境
為了保持專案井井有條並避免依賴衝突,最好使用虛擬環境。
- 建立虛擬環境:
python -m venv env
-
啟動虛擬環境:
- 在 Windows 上:
.\env\Scripts\activate
-
在 macOS/Linux 上:
source env/bin/activate
- 在環境下安裝庫: 啟動後,任何安裝的庫都會被隔離到這個環境。
第 3 步:安裝必要的庫
Python 準備好後,安裝以下對 AI/ML 至關重要的函式庫:
- NumPy: 用於數值計算。
pip install numpy
- pandas: 用於資料操作和分析。
pip install pandas
- Matplotlib 和 Seaborn: 用於資料視覺化。
pip install matplotlib seaborn
- scikit-learn: 用於基本的 ML 演算法和工具。
pip install scikit-learn
- TensorFlow/PyTorch: 用於深度學習。
pip install tensorflow
或
pip install torch torchvision
- Jupyter Notebook: 用於編碼和視覺化的互動式環境。
pip install notebook
第 4 步:探索 Jupyter Notebook
Jupyter Notebooks 提供了一種互動式方式來編寫和測試程式碼,使其非常適合學習 AI/ML。
- 啟動 Jupyter Notebook:
jupyter notebook
這將在您的瀏覽器中開啟一個網頁介面。
-
建立一個新筆記本:
- 點選新建> Python 3 Notebook 並開始編碼!
第 5 步:設定 Google Colab(可選)
對於不想設定本地環境的人來說,Google Colab 是一個不錯的選擇。它是免費的,並提供強大的 GPU 用於訓練 AI 模型。
-
訪問 Google Colab:
- 前往 colab.research.google.com。
-
建立一本新筆記本:
- 點選新筆電開始。
安裝庫(如果需要):
NumPy 和 pandas 等庫已預先安裝,但您可以使用以下方式安裝其他庫:
python --version
第 6 步:測試設定
為了確保一切正常,請在 Jupyter Notebook 或 Colab 中執行這個簡單的測試:
python -m venv env
輸出應該是
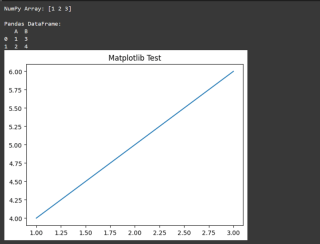
常見錯誤及解決方案
-
找不到庫:
- 確保您已在活動虛擬環境中安裝該程式庫。
-
Python 無法辨識:
- 驗證 Python 是否已加入您的系統 PATH。
-
Jupyter 筆記本問題:
- 確保您已在正確的環境中安裝 Jupyter。
~Trixsec
以上是建立您自己的 AI 部分 - 設定 AI/ML 開發環境的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 您如何將元素附加到Python列表中?May 04, 2025 am 12:17 AM
您如何將元素附加到Python列表中?May 04, 2025 am 12:17 AMtoAppendElementStoApythonList,usetheappend()方法forsingleements,Extend()formultiplelements,andinsert()forspecificpositions.1)useeAppend()foraddingoneOnelementAttheend.2)useextendTheEnd.2)useextendexendExendEnd(
 您如何創建Python列表?舉一個例子。May 04, 2025 am 12:16 AM
您如何創建Python列表?舉一個例子。May 04, 2025 am 12:16 AMTocreateaPythonlist,usesquarebrackets[]andseparateitemswithcommas.1)Listsaredynamicandcanholdmixeddatatypes.2)Useappend(),remove(),andslicingformanipulation.3)Listcomprehensionsareefficientforcreatinglists.4)Becautiouswithlistreferences;usecopy()orsl
 討論有效存儲和數值數據的處理至關重要的實際用例。May 04, 2025 am 12:11 AM
討論有效存儲和數值數據的處理至關重要的實際用例。May 04, 2025 am 12:11 AM金融、科研、医疗和AI等领域中,高效存储和处理数值数据至关重要。1)在金融中,使用内存映射文件和NumPy库可显著提升数据处理速度。2)科研领域,HDF5文件优化数据存储和检索。3)医疗中,数据库优化技术如索引和分区提高数据查询性能。4)AI中,数据分片和分布式训练加速模型训练。通过选择适当的工具和技术,并权衡存储与处理速度之间的trade-off,可以显著提升系统性能和可扩展性。
 您如何創建Python數組?舉一個例子。May 04, 2025 am 12:10 AM
您如何創建Python數組?舉一個例子。May 04, 2025 am 12:10 AMpythonarraysarecreatedusiseThearrayModule,notbuilt-Inlikelists.1)importThearrayModule.2)指定tefifythetypecode,例如,'i'forineizewithvalues.arreaysofferbettermemoremorefferbettermemoryfforhomogeNogeNogeNogeNogeNogeNogeNATATABUTESFELLESSFRESSIFERSTEMIFICETISTHANANLISTS。
 使用Shebang系列指定Python解釋器有哪些替代方法?May 04, 2025 am 12:07 AM
使用Shebang系列指定Python解釋器有哪些替代方法?May 04, 2025 am 12:07 AM除了shebang線,還有多種方法可以指定Python解釋器:1.直接使用命令行中的python命令;2.使用批處理文件或shell腳本;3.使用構建工具如Make或CMake;4.使用任務運行器如Invoke。每個方法都有其優缺點,選擇適合項目需求的方法很重要。
 列表和陣列之間的選擇如何影響涉及大型數據集的Python應用程序的整體性能?May 03, 2025 am 12:11 AM
列表和陣列之間的選擇如何影響涉及大型數據集的Python應用程序的整體性能?May 03, 2025 am 12:11 AMForhandlinglargedatasetsinPython,useNumPyarraysforbetterperformance.1)NumPyarraysarememory-efficientandfasterfornumericaloperations.2)Avoidunnecessarytypeconversions.3)Leveragevectorizationforreducedtimecomplexity.4)Managememoryusagewithefficientdata
 說明如何將內存分配給Python中的列表與數組。May 03, 2025 am 12:10 AM
說明如何將內存分配給Python中的列表與數組。May 03, 2025 am 12:10 AMInpython,ListSusedynamicMemoryAllocationWithOver-Asalose,而alenumpyArraySallaySallocateFixedMemory.1)listssallocatemoremoremoremorythanneededinentientary上,respizeTized.2)numpyarsallaysallaysallocateAllocateAllocateAlcocateExactMemoryForements,OfferingPrediCtableSageButlessemageButlesseflextlessibility。
 您如何在Python數組中指定元素的數據類型?May 03, 2025 am 12:06 AM
您如何在Python數組中指定元素的數據類型?May 03, 2025 am 12:06 AMInpython,YouCansspecthedatatAtatatPeyFelemereModeRernSpant.1)Usenpynernrump.1)Usenpynyp.dloatp.dloatp.ploatm64,formor professisconsiscontrolatatypes。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Dreamweaver Mac版
視覺化網頁開發工具

SublimeText3漢化版
中文版,非常好用

