


介紹
我目前正在維護一個強大的開源創意畫板。這款畫板整合了許多有趣的畫筆和輔助繪圖功能,可以讓使用者體驗到全新的繪圖效果。無論是在行動端還是PC端,都可以享受到更好的互動體驗和效果展示。
在這篇文章中,我將詳細講解如何結合 Transformers.js 實現背景移除和影像標記分割。結果如下

連結:https://songlh.top/paint-board/
Github:https://github.com/LHRUN/paint-board 歡迎Star ⭐️
Transformers.js
Transformers.js 是一個基於 Hugging Face 的 Transformers 的強大 JavaScript 庫,可以直接在瀏覽器中運行,無需依賴伺服器端計算。這意味著您可以在本地運行模型,從而提高效率並降低部署和維護成本。
目前Transformers.js 在Hugging Face 上提供了1000 個模型,涵蓋各個領域,可以滿足你的大部分需求,例如影像處理、文字產生、翻譯、情緒分析等任務處理,你都可以透過Transformers 輕鬆實作.js。依下列方式搜尋型號。
目前 Transformers.js 的主要版本已更新為 V3,增加了很多很棒的功能,詳細資訊:Transformers.js v3:WebGPU 支援、新模型和任務以及更多......
我在這篇文章中添加的兩個功能都使用了 WebGpu 支持,該支持僅在 V3 中可用,並且大大提高了處理速度,現在解析速度為毫秒級。不過要注意的是,支援WebGPU的瀏覽器並不多,建議使用最新版本的Google進行存取。
功能一:去除背景
為了刪除背景,我使用 Xenova/modnet 模型,如下圖
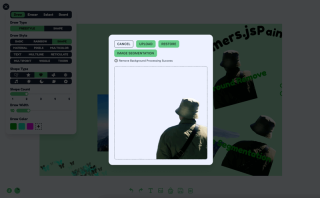
處理邏輯可以分為三步驟
- 初始化狀態,並載入模型和處理器。
- 介面的顯示,這是你自己設計的,不是我的。
- 展示效果,這是你自己設計的,不是我的。現在比較流行的是用邊框線來動態展示去除背景前後的對比效果。
程式碼邏輯如下,React TS ,具體參見我的專案原始碼,原始碼位於 src/components/boardOperation/uploadImage/index.tsx
import { useState, FC, useRef, useEffect, useMemo } from 'react'
import {
env,
AutoModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor
} from '@huggingface/transformers'
const REMOVE_BACKGROUND_STATUS = {
LOADING: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
LOAD_SUCCESS: 3,
PROCESSING: 4,
PROCESSING_SUCCESS: 5
}
type RemoveBackgroundStatusType =
(typeof REMOVE_BACKGROUND_STATUS)[keyof typeof REMOVE_BACKGROUND_STATUS]
const UploadImage: FC = ({ url }) => {
const [removeBackgroundStatus, setRemoveBackgroundStatus] =
useState<removebackgroundstatustype>()
const [processedImage, setProcessedImage] = useState('')
const modelRef = useRef<pretrainedmodel>()
const processorRef = useRef<processor>()
const removeBackgroundBtnTip = useMemo(() => {
switch (removeBackgroundStatus) {
case REMOVE_BACKGROUND_STATUS.LOADING:
return 'Remove background function loading'
case REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU:
return 'WebGPU is not supported in this browser, to use the remove background function, please use the latest version of Google Chrome'
case REMOVE_BACKGROUND_STATUS.LOAD_ERROR:
return 'Remove background function failed to load'
case REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS:
return 'Remove background function loaded successfully'
case REMOVE_BACKGROUND_STATUS.PROCESSING:
return 'Remove Background Processing'
case REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS:
return 'Remove Background Processing Success'
default:
return ''
}
}, [removeBackgroundStatus])
useEffect(() => {
;(async () => {
try {
if (removeBackgroundStatus === REMOVE_BACKGROUND_STATUS.LOADING) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOADING)
// Checking WebGPU Support
if (!navigator?.gpu) {
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/modnet'
if (env.backends.onnx.wasm) {
env.backends.onnx.wasm.proxy = false
}
// Load model and processor
modelRef.current ??= await AutoModel.from_pretrained(model_id, {
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_ERROR)
}
})()
}, [])
const processImages = async () => {
const model = modelRef.current
const processor = processorRef.current
if (!model || !processor) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING)
// load image
const img = await RawImage.fromURL(url)
// Pre-processed image
const { pixel_values } = await processor(img)
// Generate image mask
const { output } = await model({ input: pixel_values })
const maskData = (
await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(
img.width,
img.height
)
).data
// Create a new canvas
const canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D
// Draw the original image
ctx.drawImage(img.toCanvas(), 0, 0)
// Updating the mask area
const pixelData = ctx.getImageData(0, 0, img.width, img.height)
for (let i = 0; i
<button classname="{`btn" btn-primary btn-sm remove_background_status.load_success remove_background_status.processing_success undefined : onclick="{processImages}">
Remove background
</button>
<div classname="text-xs text-base-content mt-2 flex">
{removeBackgroundBtnTip}
</div>
<div classname="relative mt-4 border border-base-content border-dashed rounded-lg overflow-hidden">
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-[50vw]" max-w- h- max-h- object-contain alt="探索Canvas系列:結合Transformers.js實現智慧型影像處理" >
{processedImage && (
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-full" h-full absolute top-0 left-0 z- object-contain alt="探索Canvas系列:結合Transformers.js實現智慧型影像處理" >
)}
</div>
)
}
export default UploadImage
</processor></pretrainedmodel></removebackgroundstatustype>
功能2:影像標記分割
影像標記分割是使用 Xenova/slimsam-77-uniform 模型實現的。效果如下,圖片載入完成後點擊即可,根據你點擊的座標產生分割
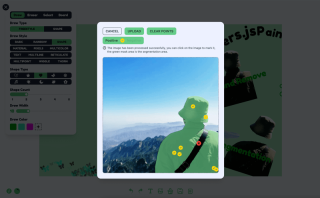
處理邏輯可以分為五個步驟
- 初始化狀態,並載入模型和處理器
- 取得圖像並加載,然後儲存圖像加載資料和嵌入資料。
- 監聽影像點擊事件,記錄點擊數據,分為正標記和負標記,每次點擊後根據點擊數據解碼產生mask數據,然後根據mask數據繪製分割效果.
- 介面展示,這個要自己設計任意發揮,不是我的為準
- 點擊儲存影像,根據mask像素數據,匹配原始影像數據,然後透過canvas繪圖匯出
程式碼邏輯如下,React TS ,具體參見我的專案原始碼,原始碼位於 src/components/boardOperation/uploadImage/imageSegmentation.tsx
從 'react' 導入 { useState, useRef, useEffect, useMemo, MouseEvent, FC }
進口 {
薩姆模型,
自動處理器,
原始影像,
預訓練模型,
處理器,
張量,
SamImageProcessor結果
} 來自 '@huggingface/transformers'
從 '@/components/icons/loading.svg?react' 導入 LoadingIcon
從 '@/components/icons/boardOperation/image-segmentation-positive.svg?react' 導入 PositiveIcon
從 '@/components/icons/boardOperation/image-segmentation-negative.svg?react' 導入 NegativeIcon
介面標記點{
位置:數字[]
標籤: 數字
}
常數 SEGMENTATION_STATUS = {
正在加載:0,
NO_SUPPORT_WEBGPU:1,
載入錯誤:2,
載入成功:3,
加工:4、
處理成功:5
}
類型分段狀態類型 =
(SEGMENTATION_STATUS 類型)[SEGMENTATION_STATUS 類型鍵]
const ImageSegmentation: FC; = ({ url }) =>; {
const [markPoints, setMarkPoints] = useState<markpoint>([])
const [segmentationStatus, setSegmentationStatus] =
useState<segmentationstatustype>()
const [pointStatus, setPointStatus] = useState<boolean>(true)
const maskCanvasRef = useRef<htmlcanvaselement>(null) // 分段遮罩
const modelRef = useRef<pretrainedmodel>() // 模型
const handlerRef = useRef<processor>() // 處理器
const imageInputRef = useRef<rawimage>() // 原始影像
const imageProcessed = useRef<samimageprocessorresult>() // 處理後的映像
const imageEmbeddings = useRef<tensor>() // 嵌入數據
const分段提示 = useMemo(() => {
開關(分段狀態){
案例 SEGMENTATION_STATUS.LOADING:
return '在圖像分割函數載入中'
案例 SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU:
return '此瀏覽器不支援WebGPU,若要使用影像分割功能,請使用最新版本的Google Chrome。 '
案例 SEGMENTATION_STATUS.LOAD_ERROR:
return '圖像分割函數載入失敗'
案例SEGMENTATION_STATUS.LOAD_SUCCESS:
return '圖像分割函數載入成功'
案例 SEGMENTATION_STATUS.PROCESSING:
返回“圖像處理...”
案例SEGMENTATION_STATUS.PROCESSING_SUCCESS:
return '圖片處理成功,可以點擊圖片標記,綠色遮罩區域為分割區域。 '
預設:
返回 ''
}
}, [分段狀態])
// 1. 載入模型和處理器
useEffect(() => {
;(非同步() => {
嘗試 {
if (segmentationStatus === SEGMENTATION_STATUS.LOADING) {
返回
}
setSegmentationStatus(SEGMENTATION_STATUS.LOADING)
if (!navigator?.gpu) {
setSegmentationStatus(SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU)
返回
}const model_id = 'Xenova/slimsam-77-uniform'
modelRef.current ??= 等待 SamModel.from_pretrained(model_id, {
dtype: 'fp16', // 或 "fp32"
設備:'webgpu'
})
handlerRef.current ??= 等待 AutoProcessor.from_pretrained(model_id)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_SUCCESS)
} 捕獲(錯誤){
console.log('錯誤', 錯誤)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_ERROR)
}
})()
}, [])
// 2. 處理影像
useEffect(() => {
;(非同步() => {
嘗試 {
如果 (
!modelRef.current ||
!processorRef.current ||
!url ||
分段狀態 === SEGMENTATION_STATUS.PROCESSING
){
返回
}
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING)
清除點()
imageInputRef.current = 等待 RawImage.fromURL(url)
imageProcessed.current = 等待處理器Ref.current(
imageInputRef.current
)
imageEmbeddings.current = 等待 (
modelRef.current 為任意
).get_image_embeddings(imageProcessed.current)
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING_SUCCESS)
} 捕獲(錯誤){
console.log('錯誤', 錯誤)
}
})()
},[url,modelRef.current,processorRef.current])
// 更新遮罩效果
函數 updateMaskOverlay(掩碼:RawImage,分數:Float32Array) {
const maskCanvas = maskCanvasRef.current
如果(!maskCanvas){
返回
}
const maskContext = maskCanvas.getContext('2d') as CanvasRenderingContext2D
// 更新畫布尺寸(如果不同)
if (maskCanvas.width !== mask.width || maskCanvas.height !== mask.height) {
maskCanvas.width = mask.width
maskCanvas.height = mask.高度
}
// 為像素資料分配緩衝區
const imageData = maskContext.createImageData(
maskCanvas.寬度,
maskCanvas.height
)
// 選擇最佳遮罩
const numMasks = Scores.length // 3
讓最佳索引 = 0
for (令 i = 1; i scores[bestIndex]) {
最佳索引 = i
}
}
// 用顏色填滿蒙版
const PixelData = imageData.data
for (令 i = 0; i {
如果 (
!modelRef.current ||
!imageEmbeddings.current ||
!processorRef.current ||
!imageProcessed.current
){
返回
}// 沒有點擊資料直接清除分割效果
if (!markPoints.length && maskCanvasRef.current) {
const maskContext = maskCanvasRef.current.getContext(
'2d'
) 作為 CanvasRenderingContext2D
maskContext.clearRect(
0,
0,
maskCanvasRef.current.width,
maskCanvasRef.current.height
)
返回
}
// 準備解碼輸入
const reshape = imageProcessed.current.reshape_input_sizes[0]
常數點 = 標記點
.map((x) => [x.position[0] * 重塑[1], x.position[1] * 重塑[0]])
.flat(無窮大)
const labels = markPoints.map((x) => BigInt(x.label)).flat(Infinity)
const num_points = markPoints.length
const input_points = new Tensor('float32', 點, [1, 1, num_points, 2])
const input_labels = new Tensor('int64', labels, [1, 1, num_points])
// 產生掩碼
const { pred_masks, iou_scores } = 等待 modelRef.current({
...imageEmbeddings.current,
輸入點,
輸入標籤
})
// 對遮罩進行後處理
const mask = wait (processorRef.current as any).post_process_masks(
pred_masks,
imageProcessed.current.original_sizes,
imageProcessed.current.reshape_input_sizes
)
updateMaskOverlay(RawImage.fromTensor(masks[0][0]), iou_scores.data)
}
const 箝位 = (x: 數字, 最小值 = 0, 最大值 = 1) => {
返回 Math.max(Math.min(x, max), min)
}
const clickImage = (e: MouseEvent) =>; {
if (segmentationStatus !== SEGMENTATION_STATUS.PROCESSING_SUCCESS) {
返回
}
const { clientX, clientY, currentTarget } = e
const { 左,上 } = currentTarget.getBoundingClientRect()
常數 x = 箝位(
(clientX - 左 currentTarget.scrollLeft) / currentTarget.scrollWidth
)
常數 y = 箝位(
(clientY - 頂部 currentTarget.scrollTop) / currentTarget.scrollHeight
)
const現有PointIndex = markPoints.findIndex(
(點)=>
Math.abs(point.position[0] - x) ; {
設定標記點([])
解碼([])
}
返回 (
<div classname="cardshadow-xloverflow-auto">
<div classname="flex items-center gap-x-3">
清除積分
按鈕>
; setPointStatus(true)}
>
{點狀態? 「正」:「負」}
按鈕>
</div>
<div classname="text-xs text-base-content mt-2">{segmentationTip}</div>;
<div>
<h2>
結論
</h2>
<p>感謝您的閱讀。這就是本文的全部內容,希望本文對您有所幫助,歡迎點讚收藏。如有任何疑問,歡迎在留言區討論! </p>
</div>
</div></tensor></samimageprocessorresult></rawimage></processor></pretrainedmodel></htmlcanvaselement></boolean></segmentationstatustype></markpoint>以上是探索Canvas系列:結合Transformers.js實現智慧型影像處理的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 C和JavaScript:連接解釋Apr 23, 2025 am 12:07 AM
C和JavaScript:連接解釋Apr 23, 2025 am 12:07 AMC 和JavaScript通過WebAssembly實現互操作性。 1)C 代碼編譯成WebAssembly模塊,引入到JavaScript環境中,增強計算能力。 2)在遊戲開發中,C 處理物理引擎和圖形渲染,JavaScript負責遊戲邏輯和用戶界面。
 從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AM
從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AMJavaScript在網站、移動應用、桌面應用和服務器端編程中均有廣泛應用。 1)在網站開發中,JavaScript與HTML、CSS一起操作DOM,實現動態效果,並支持如jQuery、React等框架。 2)通過ReactNative和Ionic,JavaScript用於開發跨平台移動應用。 3)Electron框架使JavaScript能構建桌面應用。 4)Node.js讓JavaScript在服務器端運行,支持高並發請求。
 Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AMPython更適合數據科學和自動化,JavaScript更適合前端和全棧開發。 1.Python在數據科學和機器學習中表現出色,使用NumPy、Pandas等庫進行數據處理和建模。 2.Python在自動化和腳本編寫方面簡潔高效。 3.JavaScript在前端開發中不可或缺,用於構建動態網頁和單頁面應用。 4.JavaScript通過Node.js在後端開發中發揮作用,支持全棧開發。
 C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AM
C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AMC和C 在JavaScript引擎中扮演了至关重要的角色,主要用于实现解释器和JIT编译器。1)C 用于解析JavaScript源码并生成抽象语法树。2)C 负责生成和执行字节码。3)C 实现JIT编译器,在运行时优化和编译热点代码,显著提高JavaScript的执行效率。
 JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AMJavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。
 JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AMJavaScript在Web開發中的主要用途包括客戶端交互、表單驗證和異步通信。 1)通過DOM操作實現動態內容更新和用戶交互;2)在用戶提交數據前進行客戶端驗證,提高用戶體驗;3)通過AJAX技術實現與服務器的無刷新通信。
 了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM
了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM理解JavaScript引擎內部工作原理對開發者重要,因為它能幫助編寫更高效的代碼並理解性能瓶頸和優化策略。 1)引擎的工作流程包括解析、編譯和執行三個階段;2)執行過程中,引擎會進行動態優化,如內聯緩存和隱藏類;3)最佳實踐包括避免全局變量、優化循環、使用const和let,以及避免過度使用閉包。
 Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AMPython更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

禪工作室 13.0.1
強大的PHP整合開發環境

SublimeText3漢化版
中文版,非常好用

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

