


介紹
整個資料生命週期從產生資料並以某種方式在某個地方儲存它開始。我們稱之為早期資料生命週期,我們將探索如何使用本地工作流程將資料自動攝取到 Airtable 中。我們將介紹設定開發環境、設計攝取過程、建立批次腳本以及安排工作流程 - 保持事情簡單、本地/可複製和可存取。
首先,我們來談談Airtable。 Airtable 是一個強大且靈活的工具,它將電子表格的簡單性與資料庫的結構融為一體。我發現它非常適合組織資訊、管理專案、追蹤任務,而且它有免費套餐!
準備環境
設定開發環境
我們將使用 python 開發這個項目,所以使用你最喜歡的 IDE 並創建一個虛擬環境
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
要開始使用 Airtable,請造訪 Airtable 的網站。註冊免費帳戶後,您需要建立一個新的工作區。將工作區視為所有相關表格和資料的容器。
接下來,在您的工作區中建立一個新表。表本質上是一個電子表格,您將在其中儲存資料。定義表中的欄位(列)以符合資料結構。
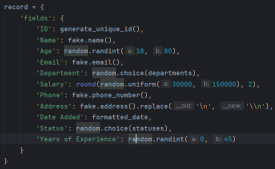
這是教學中使用的欄位片段,它是 文字、日期 和 數字 的組合:
要將腳本連接到 Airtable,您需要產生 API 金鑰或個人存取權杖。該金鑰充當密碼,允許您的腳本與 Airtable 資料進行互動。若要產生金鑰,請導覽至您的 Airtable 帳戶設置,找到 API 部分,然後依照指示建立新金鑰。
*請記得確保您的 API 金鑰安全。避免公開分享或將其提交到公共儲存庫。 *
安裝必要的依賴項(Python、函式庫等)
接下來,觸碰requirements.txt。在此 .txt 檔案中放置以下軟體套件:
pyairtable schedule faker python-dotenv
現在執行 pip install -rrequirements.txt 來安裝所需的軟體包。
組織專案結構
此步驟是我們建立腳本的地方,.env 是我們儲存憑證的位置,autoRecords.py - 為定義的欄位和ingestData. py 將記錄插入Airtable。
設計攝取過程:環境變數
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
設計攝取過程:自動記錄
聽起來不錯,讓我們為您在此員工資料產生器上的部落格文章整理一個重點副主題內容。
為您的專案產生真實的員工數據
在處理涉及員工資料的專案時,擁有可靠的方法來產生真實的樣本資料通常會很有幫助。無論您是建立人力資源管理系統、員工名錄還是介於兩者之間的任何系統,存取可靠的測試資料都可以簡化您的開發並使您的應用程式更具彈性。
在本節中,我們將探索一個 Python 腳本,該腳本產生具有各種相關欄位的隨機員工記錄。當您需要快速輕鬆地使用真實資料填充應用程式時,此工具可能是一項寶貴的資產。
產生唯一 ID
資料產生過程的第一步是為每個員工記錄建立唯一識別碼。這是一個重要的考慮因素,因為您的應用程式可能需要一種唯一引用每位員工的方法。我們的腳本包含一個簡單的函數來產生這些 ID:
pyairtable schedule faker python-dotenv
此函數產生一個格式為「N-#####」的唯一 ID,其中數字是隨機的 5 位數字。您可以自訂此格式以滿足您的特定需求。
產生隨機員工記錄
接下來我們來看看產生員工記錄的核心函數。 generate_random_records() 函數將要建立的記錄數作為輸入並返回字典列表,其中每個字典代表具有各個字段的員工:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
此函數使用 Faker 函式庫為各種員工欄位產生逼真的數據,例如姓名、電子郵件、電話號碼和地址。它還包括一些基本的約束,例如將年齡範圍和工資範圍限制在合理的值。
函數傳回一個字典列表,其中每個字典代表一條與 Airtable 相容的格式的員工記錄。
為 Airtable 準備數據
最後,讓我們來看看prepare_records_for_airtable() 函數,該函數會取得員工記錄清單並提取每筆記錄的「欄位」部分。這是 Airtable 期望導入資料的格式:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
此功能簡化了資料結構,使產生的資料與 Airtable 或其他系統整合時更容易使用。
把它們放在一起
要使用此資料產生工具,我們可以使用所需的記錄數來呼叫generate_random_records()函數,然後將結果清單傳遞給prepare_records_for_airtable()函數:
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
這將產生 2 個隨機員工記錄,以原始格式列印它們,然後以適合 Airtable 的平面格式列印記錄。
運行:
pyairtable schedule faker python-dotenv
輸出:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
將產生的資料與 Airtable 集成
除了產生真實的員工資料之外,我們的腳本還提供了將這些資料與 Airtable 無縫整合的功能
設定 Airtable 連接
在開始將產生的資料插入 Airtable 之前,我們需要建立與平台的連線。我們的腳本使用 pyairtable 庫與 Airtable API 互動。我們首先載入必要的環境變量,包括 Airtable API 金鑰以及我們要儲存資料的基本 ID 和表名稱:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
使用這些憑證,我們可以初始化 Airtable API 用戶端並取得我們要使用的特定資料表的參考:
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
插入產生的數據
現在我們已經建立了連接,我們可以使用上一節中的generate_random_records()函數來建立一批員工記錄,然後將它們插入Airtable:
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
prep_for_insertion()函式負責將generate_random_records()傳回的巢狀記錄格式轉換為Airtable API所期望的平面格式。準備好資料後,我們使用 table.batch_create() 方法在單一批次操作中插入記錄。
錯誤處理和日誌記錄
為了確保我們的整合過程穩健且易於調試,我們也提供了一些基本的錯誤處理和日誌記錄功能。如果在資料插入過程中出現任何錯誤,腳本將記錄錯誤訊息以幫助排除故障:
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
透過將我們早期腳本的強大資料產生功能與此處顯示的整合功能相結合,您可以使用真實的員工資料快速可靠地填充基於 Airtable 的應用程式。
使用批次腳本安排自動資料攝取
為了讓資料攝取過程完全自動化,我們可以建立一個批次腳本(.bat 檔案)來定期執行 Python 腳本。這允許您將資料攝取設定為自動發生,無需手動幹預。
以下是可用於執行 ingestData.py 腳本的批次腳本範例:
python autoRecords.py
讓我們分解這個腳本的關鍵部分:
- @echo off:此行禁止將每個命令列印到控制台,使輸出更清晰。
- echo Running Airtable Automated Data Ingestion Service...:此行向控制台列印一則訊息,表示腳本已啟動。
- cd /d C:UsersbuascPycharmProjectsscrapEngineering:此行將目前工作目錄變更為ingestData.py腳本所在的專案目錄。
- call C:UsersbuascPycharmProjectsscrapEngineeringvenv_airtableScriptsactivate.bat:此行啟動安裝了必要的 Python 相依性的虛擬環境。
- python ingestData.py:此行運行 ingestData.py Python 腳本。
- if %ERRORLEVEL% NEQ 0 (... ):此區塊檢查 Python 腳本是否遇到錯誤(即 ERRORLEVEL 是否不為零)。如果發生錯誤,它會列印錯誤訊息並暫停腳本,以便您調查問題。
要安排此批次腳本自動執行,您可以使用 Windows 工作排程器。以下是步驟的簡要概述:
- 開啟「開始」功能表並蒐索「任務計畫程式」。
或者
Windows R 和

- 在任務規劃程式中,建立一個新任務並為其指定一個描述性名稱(例如「Airtable Data Ingestion」)。
- 在「操作」標籤中,新增操作並指定批次腳本的路徑(例如 C:UsersbuascPycharmProjectsscrapEngineeringestData.bat)。
- 設定您希望腳本運行的時間表,例如每天、每週或每月。
- 儲存任務並啟用它。

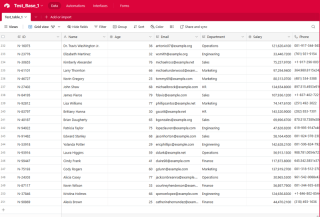
現在,Windows 任務排程器將按照指定的時間間隔自動執行批次腳本,確保您的 Airtable 資料定期更新,無需手動幹預。
結論
這對於測試、開發甚至演示來說都是一個非常寶貴的工具。
透過本指南,您學習如何設定必要的開發環境、設計攝取流程、建立批次腳本來自動執行任務,以及安排工作流程以實現無人值守執行。現在,我們對如何利用本地自動化的力量來簡化我們的資料攝取操作並從 Airtable 驅動的資料生態系統中釋放有價值的見解有了深入的了解。
現在您已經設定了自動資料擷取流程,您可以透過多種方式在此基礎上進行構建,並從 Airtable 資料中釋放更多價值。我鼓勵您嘗試程式碼,探索新的用例,並與社群分享您的經驗。
這裡有一些可以幫助您入門的想法:
- 自訂資料產生
- 利用取得的資料[基於Markdown 的探索性資料分析(EDA),使用Tableau、Power BI 或Plotly 等工具建立互動式儀表板或視覺化,試驗機器學習工作流程(預測員工流動率或辨識表現最佳的員工)]
- 與其他系統整合[雲端函數、Webhook 或資料倉儲]
可能性是無限的!我很高興看到您如何建立這個自動化資料攝取流程,並從 Airtable 資料中釋放新的見解和價值。請毫不猶豫地進行實驗、協作並分享您的進度。我會一路支持你。
查看完整程式碼https://github.com/AkanimohOD19A/scheduling_airtable_insertion,完整影片教學正在路上。
以上是本地工作流程:將資料攝取編排到 Airtable 中的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AM
Python中的合併列表:選擇正確的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作員,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入兩個列表?May 14, 2025 am 12:09 AM在Python3中,可以通過多種方法連接兩個列表:1)使用 運算符,適用於小列表,但對大列表效率低;2)使用extend方法,適用於大列表,內存效率高,但會修改原列表;3)使用*運算符,適用於合併多個列表,不修改原列表;4)使用itertools.chain,適用於大數據集,內存效率高。
 Python串聯列表字符串May 14, 2025 am 12:08 AM
Python串聯列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中從列表連接字符串最有效的方法。 1)使用join()方法高效且易讀。 2)循環使用 運算符對大列表效率低。 3)列表推導式與join()結合適用於需要轉換的場景。 4)reduce()方法適用於其他類型歸約,但對字符串連接效率低。完整句子結束。
 Python執行,那是什麼?May 14, 2025 am 12:06 AM
Python執行,那是什麼?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:關鍵功能是什麼May 14, 2025 am 12:02 AM
Python:關鍵功能是什麼May 14, 2025 am 12:02 AMPython的關鍵特性包括:1.語法簡潔易懂,適合初學者;2.動態類型系統,提高開發速度;3.豐富的標準庫,支持多種任務;4.強大的社區和生態系統,提供廣泛支持;5.解釋性,適合腳本和快速原型開發;6.多範式支持,適用於各種編程風格。
 Python:編譯器還是解釋器?May 13, 2025 am 12:10 AM
Python:編譯器還是解釋器?May 13, 2025 am 12:10 AMPython是解釋型語言,但也包含編譯過程。 1)Python代碼先編譯成字節碼。 2)字節碼由Python虛擬機解釋執行。 3)這種混合機制使Python既靈活又高效,但執行速度不如完全編譯型語言。
 python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AM
python用於循環與循環時:何時使用哪個?May 13, 2025 am 12:07 AMUseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.forloopsareIdealForkNownsences,而WhileLeleLeleLeleLeleLoopSituationSituationsItuationsItuationSuationSituationswithUndEtermentersitations。
 Python循環:最常見的錯誤May 13, 2025 am 12:07 AM
Python循環:最常見的錯誤May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐個偏置,零indexingissues,andnestedloopineflinefficiencies


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

SublimeText3漢化版
中文版,非常好用

Dreamweaver Mac版
視覺化網頁開發工具

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

