



身為資料專業人員,您需要處理來自各個領域的大量數據 各種來源。這可以使數據管理和分析成為 挑戰。幸運的是,兩項 AWS 服務可以提供協助:AWS Glue 和 Amazon 雅典娜。
當您整合這些服務時,您就釋放了 AWS 生態系統中的資料發現、編目和查詢。讓我們 了解他們如何簡化您的數據分析工作流程。

什麼是 AWS Glue?
AWS Glue 是一種無伺服器託管服務,可讓您發現、準備、 行動和整合來自多個來源的數據。作為數據集成 服務,AWS Glue 讓您能夠集中管理數據 位置,而無需管理基礎設施。
什麼是 AWS Glue 爬網程式?
Glue爬蟲是掃描資料的自動化資料發現工具 自動將其中的資料分類、分組和編目。 然後,它會在您的 AWS Glue 資料中建立新資料表或更新現有表 目錄。
什麼是 Glue 資料目錄?
AWS Glue 資料目錄是資料位置的索引, 架構和運行時指標。您需要此資訊來創建和 監控您的提取、轉換和載入 (ETL) 作業。
為什麼要使用 Amazon Athena 和 AWS Glue?
現在我們已經介紹了Amazon Athena、AWS Glue 和 AWS 的基礎知識 膠水爬蟲,讓我們更深入地討論它們。
4 個主要Amazon Athena 使用案例
Amazon Athena 有四個主要用例:
- 在S3、本地資料中心或其他雲端上執行查詢
- 為機器學習模型準備資料
- 在SQL 查詢或Python 中使用機器學習模型
簡化複雜的任務,例如異常檢測、客戶群
分析與銷售預測
- 執行多雲分析(例如在 Azure 中查詢資料)
Synapse Analytics,然後透過 Amazon 將結果視覺化
QuickSight)
>現在我們已經介紹了Amazon Athena,接下來我們來談談AWS Glue。您可以使用 AWS Glue 執行一些不同的操作。
- 您也可以使用 AWS Glue 執行 ETL 作業。這些工作可以讓你
隔離客戶數據,保護傳輸中和現場的客戶數據
休息,僅在回應客戶需要時存取客戶數據
請求。當配置 ETL 作業時,您需要做的就是提供
虛擬專用中的輸入資料來源與輸出資料目標
雲。
使用 AWS Glue 的最後一種方法是透過資料目錄 快速發現並搜尋多個 AWS 資料集,而無需移動 數據。資料編目後,可立即用於搜索 並使用 Amazon Athena、Amazon EMR 和 Amazon Redshift 進行查詢 頻譜。 - AWS Glue 入門:如何將資料從AWS Glue 取得Amazon Athena
-
那麼,如何將資料從AWS Glue 取得到Amazon Athena 中?請依照以下步驟操作: -
先將資料上傳到資料來源。最受歡迎的 選項是 S3 儲存桶,但 DynamoDB 表和 Amazon RedShift 也是 選項。 -
選擇您的資料來源並建立分類器,如果 必要的。分類器讀取資料並產生模式(如果滿足) 識別格式。您可以建立自訂分類器來查看 不同的資料類型。
設定爬網程式的名稱,然後選擇您的資料來源
並新增任何自訂分類器以確保 AWS Glue 識別
數據正確。
設定身分和存取管理 (IAM) 角色以確保爬網程式可以正確運作流程。 建立將保存資料集的資料庫。設定爬網程式的運行時間和頻率,以保持您的資料最新狀態。 執行爬網程式。此過程可能需要一段時間,具體取決於 數據集有多大。爬蟲成功運行後,您將 查看資料庫中表格的變更。 現在您已經完成了此過程,您可以跳到 Amazon Athena 並執行您需要的查詢來過濾資料並獲取 您正在尋找的結果。
以上是如何將 AWS Glue 爬網程式與 Amazon Athena 結合使用的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
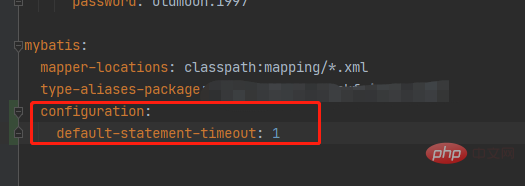 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

