


在本教學中,我們將建立一個簡單的聊天介面,讓使用者上傳PDF,使用OpenAI 的API 檢索其內容,並使用 在類似聊天的介面中顯示回應Streamlit 。我們也將利用@pinata上傳和儲存PDF檔案。
在繼續之前讓我們先看一下我們正在建造的內容:
先決條件:
- Python基礎
- Pinata API 金鑰(用於上傳 PDF)
- OpenAI API 金鑰(用於產生回應)
- 已安裝 Streamlit(用於建置 UI)
第 1 步:項目設定
先建立一個新的Python專案目錄:
mkdir chat-with-pdf cd chat-with-pdf python3 -m venv venv source venv/bin/activate pip install streamlit openai requests PyPDF2
現在,在專案的根目錄中建立一個 .env 檔案並新增以下環境變數:
PINATA_API_KEY=<your pinata api key> PINATA_SECRET_API_KEY=<your pinata secret key> OPENAI_API_KEY=<your openai api key> </your></your></your>
需要自己管理 OPENAI_API_KEY,因為它是付費的。但讓我們來看看在 Pinita 中建立 api 金鑰的過程。
所以,在繼續之前,請讓我們知道 Pinata 是什麼,這就是我們使用它的原因。

Pinata 是一項服務,提供用於在IPFS(星際文件系統)上儲存和管理文件的平台,這是一個去中心化 和分佈式 檔案儲存系統。
- 去中心化儲存: Pinata 幫助您在去中心化網路 IPFS 上儲存檔案。
- 易於使用:它提供使用者友善的工具和API用於檔案管理。
- 檔案可用性: Pinata 透過將檔案「固定」在 IPFS 上來保持檔案的可存取性。
- NFT 支援: 它非常適合儲存 NFT 和 Web3 應用程式的元資料。
- 成本效益: Pinata 可以成為傳統雲端儲存的更便宜的替代品。
讓我們透過登入來建立所需的令牌:
下一步是驗證您的註冊電子郵件:

驗證登入後產生 API 金鑰:

之後,前往 API 金鑰部分並建立新的 API 金鑰:
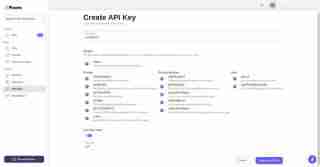
最後,金鑰已成功產生。請複製該密鑰並將其保存在程式碼編輯器中。
OPENAI_API_KEY=<your openai api key> PINATA_API_KEY=dfc05775d0c8a1743247 PINATA_SECRET_API_KEY=a54a70cd227a85e68615a5682500d73e9a12cd211dfbf5e25179830dc8278efc </your>
第 2 步:使用 Pinata 上傳 PDF
我們將使用 Pinata 的 API 上傳 PDF 並取得每個檔案的雜湊值 (CID)。建立一個名為 pinata_helper.py 的檔案來處理 PDF 上傳。
import os # Import the os module to interact with the operating system
import requests # Import the requests library to make HTTP requests
from dotenv import load_dotenv # Import load_dotenv to load environment variables from a .env file
# Load environment variables from the .env file
load_dotenv()
# Define the Pinata API URL for pinning files to IPFS
PINATA_API_URL = "https://api.pinata.cloud/pinning/pinFileToIPFS"
# Retrieve Pinata API keys from environment variables
PINATA_API_KEY = os.getenv("PINATA_API_KEY")
PINATA_SECRET_API_KEY = os.getenv("PINATA_SECRET_API_KEY")
def upload_pdf_to_pinata(file_path):
"""
Uploads a PDF file to Pinata's IPFS service.
Args:
file_path (str): The path to the PDF file to be uploaded.
Returns:
str: The IPFS hash of the uploaded file if successful, None otherwise.
"""
# Prepare headers for the API request with the Pinata API keys
headers = {
"pinata_api_key": PINATA_API_KEY,
"pinata_secret_api_key": PINATA_SECRET_API_KEY
}
# Open the file in binary read mode
with open(file_path, 'rb') as file:
# Send a POST request to Pinata API to upload the file
response = requests.post(PINATA_API_URL, files={'file': file}, headers=headers)
# Check if the request was successful (status code 200)
if response.status_code == 200:
print("File uploaded successfully") # Print success message
# Return the IPFS hash from the response JSON
return response.json()['IpfsHash']
else:
# Print an error message if the upload failed
print(f"Error: {response.text}")
return None # Return None to indicate failure
第 3 步:設定 OpenAI
接下來,我們將建立一個使用 OpenAI API 與從 PDF 中提取的文字進行互動的函數。我們將利用 OpenAI 的 gpt-4o 或 gpt-4o-mini 模型進行聊天回應。
建立一個新檔案openai_helper.py:
import os
from openai import OpenAI
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI client with the API key
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
def get_openai_response(text, pdf_text):
try:
# Create the chat completion request
print("User Input:", text)
print("PDF Content:", pdf_text) # Optional: for debugging
# Combine the user's input and PDF content for context
messages = [
{"role": "system", "content": "You are a helpful assistant for answering questions about the PDF."},
{"role": "user", "content": pdf_text}, # Providing the PDF content
{"role": "user", "content": text} # Providing the user question or request
]
response = client.chat.completions.create(
model="gpt-4", # Use "gpt-4" or "gpt-4o mini" based on your access
messages=messages,
max_tokens=100, # Adjust as necessary
temperature=0.7 # Adjust to control response creativity
)
# Extract the content of the response
return response.choices[0].message.content # Corrected access method
except Exception as e:
return f"Error: {str(e)}"
第 4 步:建立 Streamlit 介面
現在我們已經準備好了輔助函數,是時候建立 Streamlit 應用程式來上傳 PDF、從 OpenAI 取得回應並顯示聊天了。
建立一個名為app.py的檔案:
import streamlit as st
import os
import time
from pinata_helper import upload_pdf_to_pinata
from openai_helper import get_openai_response
from PyPDF2 import PdfReader
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
st.set_page_config(page_title="Chat with PDFs", layout="centered")
st.title("Chat with PDFs using OpenAI and Pinata")
uploaded_file = st.file_uploader("Upload your PDF", type="pdf")
# Initialize session state for chat history and loading state
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "loading" not in st.session_state:
st.session_state.loading = False
if uploaded_file is not None:
# Save the uploaded file temporarily
file_path = os.path.join("temp", uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
# Upload PDF to Pinata
st.write("Uploading PDF to Pinata...")
pdf_cid = upload_pdf_to_pinata(file_path)
if pdf_cid:
st.write(f"File uploaded to IPFS with CID: {pdf_cid}")
# Extract PDF content
reader = PdfReader(file_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
if pdf_text:
st.text_area("PDF Content", pdf_text, height=200)
# Allow user to ask questions about the PDF
user_input = st.text_input("Ask something about the PDF:", disabled=st.session_state.loading)
if st.button("Send", disabled=st.session_state.loading):
if user_input:
# Set loading state to True
st.session_state.loading = True
# Display loading indicator
with st.spinner("AI is thinking..."):
# Simulate loading with sleep (remove in production)
time.sleep(1) # Simulate network delay
# Get AI response
response = get_openai_response(user_input, pdf_text)
# Update chat history
st.session_state.chat_history.append({"user": user_input, "ai": response})
# Clear the input box after sending
st.session_state.input_text = ""
# Reset loading state
st.session_state.loading = False
# Display chat history
if st.session_state.chat_history:
for chat in st.session_state.chat_history:
st.write(f"**You:** {chat['user']}")
st.write(f"**AI:** {chat['ai']}")
# Auto-scroll to the bottom of the chat
st.write("<style>div.stChat {overflow-y: auto;}</style>", unsafe_allow_html=True)
# Add three dots as a loading indicator if still waiting for response
if st.session_state.loading:
st.write("**AI is typing** ...")
else:
st.error("Could not extract text from the PDF.")
else:
st.error("Failed to upload PDF to Pinata.")
第 5 步:執行應用程式
要在本地運行應用程序,請使用以下命令:
streamlit run app.py
我們的檔案已成功上傳至 Pinata 平台:

第 6 步:解釋代碼
皮納塔上傳
- 使用者上傳一個PDF文件,該文件暫時保存在本機,並使用upload_pdf_to_pinata函數上傳到Pinata。 Pinata 傳回一個雜湊值 (CID),它代表儲存在 IPFS 上的檔案。
PDF 提取
- Once the file is uploaded, the content of the PDF is extracted using PyPDF2. This text is then displayed in a text area.
OpenAI Interaction
- The user can ask questions about the PDF content using the text input. The get_openai_response function sends the user’s query along with the PDF content to OpenAI, which returns a relevant response.
Final code is available in this github repo :
https://github.com/Jagroop2001/chat-with-pdf
That's all for this blog! Stay tuned for more updates and keep building amazing apps! ?✨
Happy coding! ?
以上是使用 Pinata、OpenAI 和 Streamlit 與您的 PDF 聊天的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AM
Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AMPython和C 各有優勢,選擇應基於項目需求。 1)Python適合快速開發和數據處理,因其簡潔語法和動態類型。 2)C 適用於高性能和系統編程,因其靜態類型和手動內存管理。
 Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM選擇Python還是C 取決於項目需求:1)如果需要快速開發、數據處理和原型設計,選擇Python;2)如果需要高性能、低延遲和接近硬件的控制,選擇C 。
 達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM
達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM通過每天投入2小時的Python學習,可以有效提升編程技能。 1.學習新知識:閱讀文檔或觀看教程。 2.實踐:編寫代碼和完成練習。 3.複習:鞏固所學內容。 4.項目實踐:應用所學於實際項目中。這樣的結構化學習計劃能幫助你係統掌握Python並實現職業目標。
 最大化2小時:有效的Python學習策略Apr 20, 2025 am 12:20 AM
最大化2小時:有效的Python學習策略Apr 20, 2025 am 12:20 AM在兩小時內高效學習Python的方法包括:1.回顧基礎知識,確保熟悉Python的安裝和基本語法;2.理解Python的核心概念,如變量、列表、函數等;3.通過使用示例掌握基本和高級用法;4.學習常見錯誤與調試技巧;5.應用性能優化與最佳實踐,如使用列表推導式和遵循PEP8風格指南。
 在Python和C之間進行選擇:適合您的語言Apr 20, 2025 am 12:20 AM
在Python和C之間進行選擇:適合您的語言Apr 20, 2025 am 12:20 AMPython適合初學者和數據科學,C 適用於系統編程和遊戲開發。 1.Python簡潔易用,適用於數據科學和Web開發。 2.C 提供高性能和控制力,適用於遊戲開發和系統編程。選擇應基於項目需求和個人興趣。
 Python與C:編程語言的比較分析Apr 20, 2025 am 12:14 AM
Python與C:編程語言的比較分析Apr 20, 2025 am 12:14 AMPython更適合數據科學和快速開發,C 更適合高性能和系統編程。 1.Python語法簡潔,易於學習,適用於數據處理和科學計算。 2.C 語法複雜,但性能優越,常用於遊戲開發和系統編程。
 每天2小時:Python學習的潛力Apr 20, 2025 am 12:14 AM
每天2小時:Python學習的潛力Apr 20, 2025 am 12:14 AM每天投入兩小時學習Python是可行的。 1.學習新知識:用一小時學習新概念,如列表和字典。 2.實踐和練習:用一小時進行編程練習,如編寫小程序。通過合理規劃和堅持不懈,你可以在短時間內掌握Python的核心概念。
 Python與C:學習曲線和易用性Apr 19, 2025 am 12:20 AM
Python與C:學習曲線和易用性Apr 19, 2025 am 12:20 AMPython更易學且易用,C 則更強大但複雜。 1.Python語法簡潔,適合初學者,動態類型和自動內存管理使其易用,但可能導致運行時錯誤。 2.C 提供低級控制和高級特性,適合高性能應用,但學習門檻高,需手動管理內存和類型安全。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

SublimeText3漢化版
中文版,非常好用

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

