


Hi there, this is Mrzaizai2k again!
In this series, I want to share my approach to solving the key information extraction (KIE) problem from invoices. We’ll explore how to leverage large language models (LLMs) like ChatGPT and Qwen2 for information extraction. Then, we’ll dive into using OCR models like PaddleOCR, zero-shot classification models, or Llama 3.1 to post-process the results.
— Damn, this is exciting!
To take things up a notch, we’ll handle invoices in any format and any language. Yes, that's right — this is real!
Analyzing the Requirements
Let’s imagine you need to build a service that extracts all relevant info from any type of invoice, in any language. Something like what you’d find on this sample website.
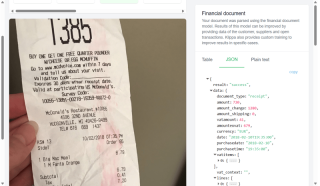
Here’s a sample invoice image we'll be working with:

Key Considerations
First, let’s analyze the requirements in detail. This will help us decide on the right tech stack for our system. While certain technologies may work well, they might not be ideal for every scenario. Here's what we need to prioritize, from top to bottom:
- Launch the system quickly
- Ensure accuracy
-
Make it work on limited computational resources
- (e.g., GPU RTX 3060 with 12 GB VRAM or even CPU)
-
Keep processing time reasonable
- ~1 minute per invoice on CPU, ~10 seconds on GPU
- Focus on extracting only useful and important details
Given these requirements, we're not going to fine-tune anything. Instead, we'll combine existing technologies and stack them together to get results fast and accurately—for any format and language.
As a benchmark, I noticed the sample website processes an invoice in about 3-4 seconds. So aiming for 10 seconds in our system is totally achievable.
The output format should match the one used on the sample website:
Chatgpt
Alright, let’s talk about the first tool: ChatGPT. You probably already know how easy it is to use. So, why bother reading this blog? Well, what if I told you that I can help you optimize token usage and speed up processing? Intrigued yet? Just hang tight—I'll explain how.
The Basic Approach
Here’s a basic code snippet. (Note: The code might not be perfect—this is more about the idea than the exact implementation). You can check out the full code in my repo Multilanguage Invoice OCR repository.
class OpenAIExtractor(BaseExtractor):
def __init__(self, config_path: str = "config/config.yaml"):
super().__init__(config_path)
self.config = self.config['openai']
self.model = self.config['model_name']
self.temperature = self.config['temperature']
self.max_tokens = self.config['max_tokens']
self.OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
from openai import OpenAI
self.client = OpenAI(api_key=self.OPENAI_API_KEY)
def _extract_invoice_llm(self, ocr_text, base64_image:str, invoice_template:str):
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": """You are a helpful assistant that responds in JSON format with the invoice information in English.
Don't add any annotations there. Remember to close any bracket. Number, price and amount should be number, date should be convert to dd/mm/yyyy,
time should be convert to HH:mm:ss, currency should be 3 chracters like VND, USD, EUR"""},
{"role": "user", "content": [
{"type": "text", "text": f"From the image of the bill and the text from OCR, extract the information. The ocr text is: {ocr_text} \n. Return the key names as in the template is a MUST. The invoice template: \n {invoice_template}"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}}
]}
],
temperature=self.temperature,
max_tokens=self.max_tokens,
)
return response.choices[0].message.content
def extract_json(self, text: str) -> dict:
start_index = text.find('{')
end_index = text.rfind('}') + 1
json_string = text[start_index:end_index]
json_string = json_string.replace('true', 'True').replace('false', 'False').replace('null', 'None')
result = eval(json_string)
return result
@retry_on_failure(max_retries=3, delay=1.0)
def extract_invoice(self, ocr_text, image: Union[str, np.ndarray], invoice_template:str) -> dict:
base64_image = self.encode_image(image)
invoice_info = self._extract_invoice_llm(ocr_text, base64_image,
invoice_template=invoice_template)
invoice_info = self.extract_json(invoice_info)
return invoice_info
ok, let's see the result
invoice {
"invoice_info": {
"amount": 32.0,
"amount_change": 0,
"amount_shipping": 0,
"vatamount": 0,
"amountexvat": 32.0,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"vatitems": [
{
"amount": 32.0,
"amount_excl_vat": 32.0,
"amount_incl_vat": 32.0,
"amount_incl_excl_vat_estimated": false,
"percentage": 0,
"code": ""
}
],
"vat_context": "",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "Lunettes",
"description": "",
"amount": 22.0,
"amount_each": 22.0,
"amount_ex_vat": 22.0,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "Chapeau",
"description": "",
"amount": 10.0,
"amount_each": 10.0,
"amount_ex_vat": 10.0,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"paymentmethod": "CB EMV",
"payment_auth_code": "",
"payment_card_number": "",
"payment_card_account_number": "",
"payment_card_bank": "",
"payment_card_issuer": "",
"payment_due_date": "",
"terminal_number": "",
"document_subject": "",
"package_number": "",
"invoice_number": "",
"receipt_number": "000130",
"shop_number": "",
"transaction_number": "000148",
"transaction_reference": "",
"order_number": "",
"table_number": "",
"table_group": "",
"merchant_name": "G\u00e9ant Casino",
"merchant_id": "",
"merchant_coc_number": "",
"merchant_vat_number": "",
"merchant_bank_account_number": "",
"merchant_bank_account_number_bic": "",
"merchant_chain_liability_bank_account_number": "",
"merchant_chain_liability_amount": 0,
"merchant_bank_domestic_account_number": "",
"merchant_bank_domestic_bank_code": "",
"merchant_website": "",
"merchant_email": "",
"merchant_address": "Annecy",
"merchant_phone": "04.50.88.20.00",
"customer_name": "",
"customer_address": "",
"customer_phone": "",
"customer_website": "",
"customer_vat_number": "",
"customer_coc_number": "",
"customer_bank_account_number": "",
"customer_bank_account_number_bic": "",
"customer_email": "",
"document_language": ""
}
}
Test_Openai_Invoice Took 0:00:11.15
The result is pretty solid, but the processing time is a problem—it exceeds our 10-second limit. You might also notice that the output includes a lot of empty fields, which not only increases the processing time but can also introduce errors and consume more tokens—essentially costing more money.
The Advanced Approach
It turns out, we only need a small tweak to fix this.
Simply add the following sentence to your prompt:
"Only output fields that have values, and don’t return any empty fields."
Voila! Problem solved!
invoice_info {
"invoice_info": {
"amount": 32,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "LUNETTES",
"description": "",
"amount": 22,
"amount_each": 22,
"amount_ex_vat": 22,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "CHAPEAU",
"description": "",
"amount": 10,
"amount_each": 10,
"amount_ex_vat": 10,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"invoice_number": "000130"
}
}
Test_Openai_Invoice Took 0:00:05.79
Wow, what a game-changer! Now the results are shorter and more precise, and the processing time has dropped from 11.15 seconds to just 5.79 seconds. With that single sentence tweak, we’ve cut the cost and processing time by around 50%. Pretty cool, right?
In this case, I’m using GPT-4o-mini, which works well, but in my experience, Gemini Flash performs even better—faster and free! Definitely worth checking out.
You can further optimize things by shortening the template, focusing only on the most important fields based on your specific requirements.
PaddleOCR
The results are looking pretty good, but there are still a few missing fields, like the telephone number or cashier name, which we’d also like to capture. While we could simply re-prompt ChatGPT, relying solely on LLMs can be unpredictable—the results can vary with each run. Moreover, the prompt template is quite long (since we're trying to extract all possible information for all formats), which can cause ChatGPT to "forget" certain details.
This is where PaddleOCR comes in—it enhances the vision capabilities of the LLM by providing precise OCR text, helping the model focus on exactly what needs to be extracted.
In my previous prompt, I used this structure:
{"type": "text", "text": f"From the image of the bill and the text from OCR, extract the information. The ocr text is: {ocr_text} \n.
Previously, I set ocr_text = '', but now we'll populate it with the output from PaddleOCR. Since I'm unsure of the specific language for now, I'll use English (as it's the most commonly supported). In the next part, I’ll guide you on detecting the language, so hang tight!
Here’s the updated code to integrate PaddleOCR:
ocr = PaddleOCR(lang='en', show_log=False, use_angle_cls=True, cls=True) result = ocr.ocr(np.array(image))
This is the OCR output.
"Geant Casino ANNECY BIENVENUE DANS NOTRE MAGASIN Caisse014 Date28/06/2008 VOTRE MAGASIN VOUS ACCUEILLE DU LUNDI AU SAMEDI DE 8H30 A21H00 TEL.04.50.88.20.00 LUNETTES 22.00E CHAPEAU 10.00E =TOTAL2) 32.00E CB EMV 32.00E Si vous aviez la carte fidelite, vous auriez cumule 11SMILES Caissier:000148/Heure:17:46:26 Numero de ticket :000130 Rapidite,confort d'achat budget maitrise.. Scan' Express vous attend!! Merci de votre visite A bientot"
As you can see, the results are pretty good. In this case, the invoice is in French, which looks similar to English, so the output is decent. However, if we were dealing with languages like Japanese or Chinese, the results wouldn't be as accurate.
Now, let’s see what happens when we combine the OCR output with ChatGPT.
invoice_info {
"invoice_info": {
"amount": 32,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "LUNETTES",
"description": "",
"amount": 22,
"amount_each": 22,
"amount_ex_vat": 22,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "CHAPEAU",
"description": "",
"amount": 10,
"amount_each": 10,
"amount_ex_vat": 10,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"paymentmethod": "CB EMV",
"receipt_number": "000130",
"transaction_number": "000130",
"merchant_name": "G\u00e9ant Casino",
"customer_email": "",
"customer_name": "",
"customer_address": "",
"customer_phone": ""
}
}
Test_Openai_Invoice Took 0:00:06.78
Awesome! It uses a few more tokens and takes slightly longer, but it returns additional fields like payment_method, receipt_number, and cashier. That’s a fair trade-off and totally acceptable!
Language Detection
Right now, we’re facing two major challenges. First, PaddleOCR cannot automatically detect the language, which significantly affects the OCR output, and ultimately impacts the entire result. Second, most LLMs perform best with English, so if the input is in another language, the quality of the results decreases.
To demonstrate, I’ll use a challenging example.
Here’s a Japanese invoice:

Let’s see what happens if we fail to auto-detect the language and use lang='en' to extract OCR on this Japanese invoice.
The result
'TEL045-752-6131 E TOP&CIubQJMB-FJ 2003 20130902 LNo.0102 No0073 0011319-2x198 396 00327111 238 000805 VR-E--E 298 003276 9 -435 298 001093 398 000335 138 000112 7 2x158 316 A000191 92 29 t 2.111 100) 10.001 10.001 7.890'
As you can see, the result is pretty bad.
Now, let’s detect the language using a zero-shot classification model. In this case, I’m using "facebook/metaclip-b32-400m". This is one of the best ways to detect around 80 languages supported by PaddleOCR without needing fine-tuning while still maintaining accuracy.
def initialize_language_detector(self):
# Initialize the zero-shot image classification model
self.image_classifier = pipeline(task="zero-shot-image-classification",
model="facebook/metaclip-b32-400m",
device=self.device,
batch_size=8)
def _get_lang(self, image: Image.Image) -> str:
# Define candidate labels for language classification
candidate_labels = [f"language {key}" for key in self.language_dict]
# Perform inference to classify the language
outputs = self.image_classifier(image, candidate_labels=candidate_labels)
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
# Extract the language with the highest score
language_names = [entry['label'].replace('language ', '') for entry in outputs]
scores = [entry['score'] for entry in outputs]
abbreviations = [self.language_dict.get(language) for language in language_names]
first_abbreviation = abbreviations[0]
lang = 'en' # Default to English
if scores[0] > self.language_thresh:
lang = first_abbreviation
print("The source language", abbreviations)
return lang
Let's see the result
Recognized Text:
{'ori_text': '根岸 東急ストア TEL 045-752-6131 領収証 [TOP2C!UbO J3カード」 クレヅッ 卜でのお支払なら 200円で3ボイン卜 お得なカード! 是非こ入会下さい。 2013年09月02日(月) レジNO. 0102 NOO07さ と う 001131 スダフエウ卜チーネ 23 単198 1396 003271 オインイ年 ユウ10 4238 000805 ソマ一ク スモー一クサーモン 1298 003276 タカナン ナマクリーム35 1298 001093 ヌテラ スフレクト 1398 000335 バナサ 138 000112 アボト 2つ 単158 1316 A000191 タマネキ 429 合計 2,111 (内消費税等 100 現金 10001 お預り合計 110 001 お釣り 7 890',
'ori_language': 'ja',
'text': 'Negishi Tokyu Store TEL 045-752-6131 Receipt [TOP2C!UbO J3 Card] If you pay with a credit card, you can get 3 points for 200 yen.A great value card!Please join us. Monday, September 2, 2013 Cashier No. 0102 NOO07 Satou 001131 Sudafue Bucine 23 Single 198 1396 003271 Oinyen Yu 10 4238 000805 Soma Iku Smo Iku Salmon 1298 003276 Takanan Nama Cream 35 1 298 001093 Nutella Sprect 1398 000335 Banasa 138 000112 Aboto 2 AA 158 1316 A000191 Eggplant 429 Total 2,111 (including consumption tax, etc. 100 Cash 10001 Total deposited 110 001 Change 7 890',
'language': 'en',}
The results are much better now! I also translated the original Japanese into English. With this approach, the output will significantly improve for other languages as well.
Summary
In this blog, we explored how to extract key information from invoices by combining LLMs and OCR, while also optimizing processing time, minimizing token usage, and improving multilingual support. By incorporating PaddleOCR and a zero-shot language detection model, we boosted both accuracy and reliability across different formats and languages. I hope these examples help you grasp the full process, from initial concept to final implementation.
Reference:
Mrzaizai2k - Multilanguage invoice ocr
More
If you’d like to learn more, be sure to check out my other posts and give me a like! It would mean a lot to me. Thank you.
- Real-Time Data Processing with MongoDB Change Streams and Python
- Replay Attack: Let’s Learn
- Reasons to Write
以上是關鍵資訊擷取的實用方法(第 1 部分)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AM
Python vs. C:了解關鍵差異Apr 21, 2025 am 12:18 AMPython和C 各有優勢,選擇應基於項目需求。 1)Python適合快速開發和數據處理,因其簡潔語法和動態類型。 2)C 適用於高性能和系統編程,因其靜態類型和手動內存管理。
 Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的項目選擇哪種語言?Apr 21, 2025 am 12:17 AM選擇Python還是C 取決於項目需求:1)如果需要快速開發、數據處理和原型設計,選擇Python;2)如果需要高性能、低延遲和接近硬件的控制,選擇C 。
 達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM
達到python目標:每天2小時的力量Apr 20, 2025 am 12:21 AM通過每天投入2小時的Python學習,可以有效提升編程技能。 1.學習新知識:閱讀文檔或觀看教程。 2.實踐:編寫代碼和完成練習。 3.複習:鞏固所學內容。 4.項目實踐:應用所學於實際項目中。這樣的結構化學習計劃能幫助你係統掌握Python並實現職業目標。
 最大化2小時:有效的Python學習策略Apr 20, 2025 am 12:20 AM
最大化2小時:有效的Python學習策略Apr 20, 2025 am 12:20 AM在兩小時內高效學習Python的方法包括:1.回顧基礎知識,確保熟悉Python的安裝和基本語法;2.理解Python的核心概念,如變量、列表、函數等;3.通過使用示例掌握基本和高級用法;4.學習常見錯誤與調試技巧;5.應用性能優化與最佳實踐,如使用列表推導式和遵循PEP8風格指南。
 在Python和C之間進行選擇:適合您的語言Apr 20, 2025 am 12:20 AM
在Python和C之間進行選擇:適合您的語言Apr 20, 2025 am 12:20 AMPython適合初學者和數據科學,C 適用於系統編程和遊戲開發。 1.Python簡潔易用,適用於數據科學和Web開發。 2.C 提供高性能和控制力,適用於遊戲開發和系統編程。選擇應基於項目需求和個人興趣。
 Python與C:編程語言的比較分析Apr 20, 2025 am 12:14 AM
Python與C:編程語言的比較分析Apr 20, 2025 am 12:14 AMPython更適合數據科學和快速開發,C 更適合高性能和系統編程。 1.Python語法簡潔,易於學習,適用於數據處理和科學計算。 2.C 語法複雜,但性能優越,常用於遊戲開發和系統編程。
 每天2小時:Python學習的潛力Apr 20, 2025 am 12:14 AM
每天2小時:Python學習的潛力Apr 20, 2025 am 12:14 AM每天投入兩小時學習Python是可行的。 1.學習新知識:用一小時學習新概念,如列表和字典。 2.實踐和練習:用一小時進行編程練習,如編寫小程序。通過合理規劃和堅持不懈,你可以在短時間內掌握Python的核心概念。
 Python與C:學習曲線和易用性Apr 19, 2025 am 12:20 AM
Python與C:學習曲線和易用性Apr 19, 2025 am 12:20 AMPython更易學且易用,C 則更強大但複雜。 1.Python語法簡潔,適合初學者,動態類型和自動內存管理使其易用,但可能導致運行時錯誤。 2.C 提供低級控制和高級特性,適合高性能應用,但學習門檻高,需手動管理內存和類型安全。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

