
掌握影像分割:傳統技術如何在數位時代仍然大放異彩

- DDD原創
- 2024-09-14 06:23:021118瀏覽
介紹
影像分割是電腦視覺中最基本的過程之一,它允許系統分解和分析影像中的各個區域。無論您是在處理物件辨識、醫學影像還是自動駕駛,分割都可以將影像分解為有意義的部分。
儘管深度學習模型在這項任務中越來越受歡迎,但數位影像處理中的傳統技術仍然強大且實用。本文回顧的方法包括閾值處理、邊緣檢測、基於區域和透過實施公認的細胞影像分析資料集(MIVIA HEp-2 影像資料集)進行聚類。
MIVIA HEp-2 影像資料集
MIVIA HEp-2 影像資料集是一組細胞圖片,用於分析 HEp-2 細胞的抗核抗體 (ANA) 模式。它由透過螢光顯微鏡拍攝的 2D 圖片組成。這使得它非常適合分割任務,最重要的是那些與醫學影像分析相關的任務,其中細胞區域檢測是最重要的。
現在,讓我們繼續討論用於處理這些影像的分割技術,根據 F1 分數比較它們的表現。
1. 閾值分割
閾值處理是根據像素強度將灰階影像轉換為二值影像的過程。在 MIVIA HEp-2 資料集中,此過程對於從背景中提取細胞非常有用。它在很大程度上是簡單且有效的,特別是使用大津方法,因為它會自動計算最佳閾值。
Otsu 方法 是一種自動閾值方法,它試圖找到最佳閾值以產生最小的類內方差,從而分離兩個類別:前景(細胞)和背景。此方法檢查影像直方圖並計算完美閾值,其中每個類別中的像素強度變異數的總和最小化。
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
return thresh
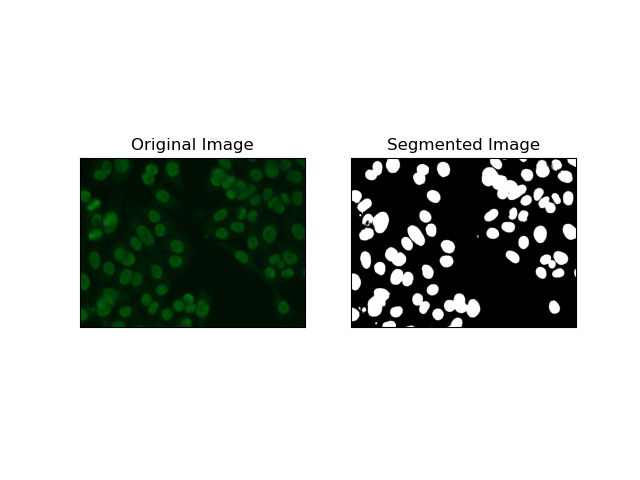
2. 邊緣偵測分割
邊緣偵測涉及識別物件或區域的邊界,例如 MIVIA HEp-2 資料集中的細胞邊緣。在許多檢測強度突然變化的可用方法中,Canny 邊緣偵測器 是最好的,因此也是最適合用於偵測細胞邊界的方法。
Canny 邊緣偵測器 是一種多階段演算法,可以透過偵測強度梯度較強的區域來偵測邊緣。該過程包括使用高斯濾波器進行平滑、計算強度梯度、應用非極大值抑制來消除寄生響應,以及最終的雙閾值操作以僅保留顯著邊緣。
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 + sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
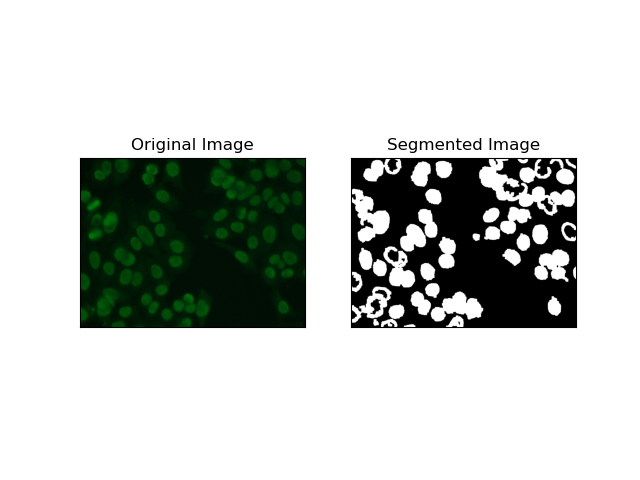
3. 基於區域的分割
基於區域的分割會根據某些標準(例如強度或顏色)將相似的像素分組到區域中。 分水嶺分割技術可用於幫助分割 HEp-2 細胞影像,以便能夠檢測代表細胞的那些區域;它將像素強度視為地形表面並勾勒出區分區域的輪廓。
分水嶺分割將像素的強度視為地形表面。該演算法識別“盆地”,在其中識別局部最小值,然後逐漸淹沒這些盆地以擴大不同的區域。當人們想要分離觸摸物體時(例如顯微圖像中的細胞),這種技術非常有用,但它可能對雜訊敏感。該過程可以透過標記來指導,並且通常可以減少過度分割。
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers + 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
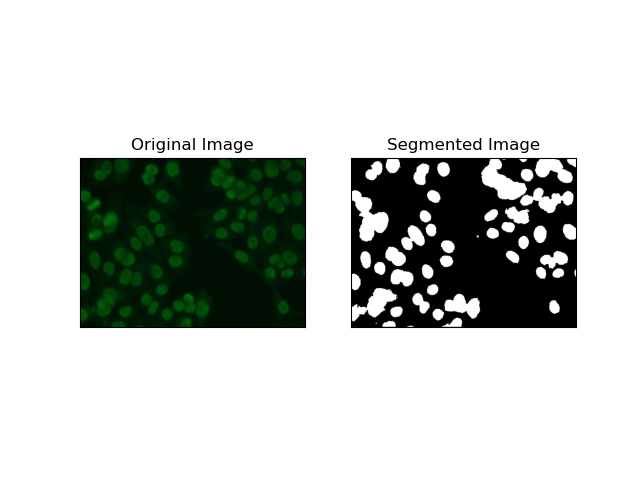
4. 基於聚類的分割
諸如K-Means之類的聚類技術傾向於將像素分組為相似的聚類,當想要在多色或複雜環境中分割細胞時,這種方法效果很好,如HEp-2 細胞影像所示。從根本上來說,這可以代表不同的類別,例如細胞區域與背景。
K-means is an unsupervised learning algorithm for clustering images based on the pixel similarity of color or intensity. The algorithm randomly selects K centroids, assigns each pixel to the nearest centroid, and updates the centroid iteratively until it converges. It is particularly effective in segmenting an image that has multiple regions of interest that are very different from one another.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
return res

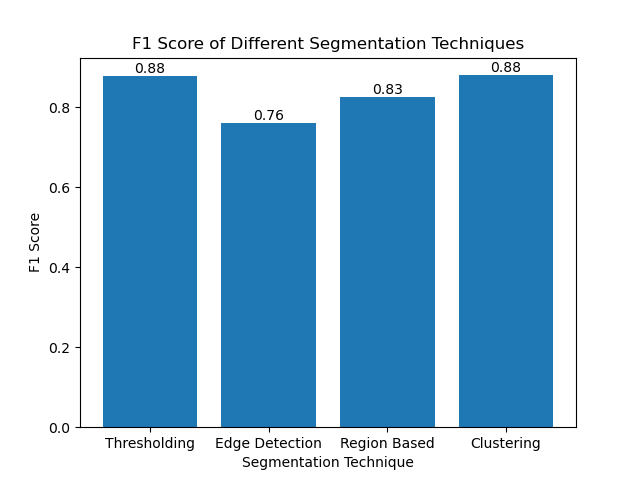
Evaluating the Techniques Using F1 Scores
The F1 score is a measure that combines precision and recall together to compare the predicted segmentation image with the ground truth image. It is the harmonic mean of precision and recall, which is useful in cases of high data imbalance, such as in medical imaging datasets.
We calculated the F1 score for each segmentation method by flattening both the ground truth and the segmented image and calculating the weighted F1 score.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
We then visualized the F1 scores of different methods using a simple bar chart:
Conclusion
Although many recent approaches for image segmentation are emerging, traditional segmentation techniques such as thresholding, edge detection, region-based methods, and clustering can be very useful when applied to datasets such as the MIVIA HEp-2 image dataset.
Each method has its strength:
- Thresholding is good for simple binary segmentation.
- Edge Detection is an ideal technique for the detection of boundaries.
- Region-based segmentation is very useful in separating connected components from their neighbors.
- Clustering methods are well-suited for multi-region segmentation tasks.
By evaluating these methods using F1 scores, we understand the trade-offs each of these models has. These methods may not be as sophisticated as what is developed in the newest models of deep learning, but they are still fast, interpretable, and serviceable in a broad range of applications.
Thanks for reading! I hope this exploration of traditional image segmentation techniques inspires your next project. Feel free to share your thoughts and experiences in the comments below!
以上是掌握影像分割:傳統技術如何在數位時代仍然大放異彩的詳細內容。更多資訊請關注PHP中文網其他相關文章!