
MLOps:如何建立工具包來提高 AI 專案效能

- 百草原創
- 2024-09-04 13:35:57702瀏覽
Numerous AI projects launched with promise fail to set sail. This is not usually because of the quality of the machine learning (ML) models. Poor implementation and system integration sink 90% of projects. Organizations can save their AI endeavors. They should adopt adequate MLOps practices and choose the right set of tools. This article discusses MLOps practices and tools that can save sinking AI projects and boost robust ones, potentially doubling project launch speed.

Numerous AI projects launched with promise fail to set sail. This is not usually because of the quality of the machine learning (ML) models. Poor implementation and system integration sink 90% of projects. Organizations can save their AI endeavors. They should adopt adequate MLOps practices and choose the right set of tools. This article discusses MLOps practices and tools that can save sinking AI projects and boost robust ones, potentially doubling project launch speed.
MLOps in a Nutshell
MLOps is a mix of machine learning application development (Dev) and operational activities (Ops). It is a set of practices that helps automate and streamline the deployment of ML models. As a result, the entire ML lifecycle becomes standardized.
MLOps is complex. It requires harmony between data management, model development, and operations. It may also need shifts in technology and culture within an organization. If adopted smoothly, MLOps allows professionals to automate tedious tasks, such as data labeling, and make deployment processes transparent. It helps ensure that project data is secure and compliant with data privacy laws.
Organizations enhance and scale their ML systems through MLOps practices. This makes collaboration between data scientists and engineers more effective and fosters innovation.
Weaving AI Projects From Challenges
MLOps professionals transform raw business challenges into streamlined, measurable machine learning goals. They design and manage ML pipelines, ensuring thorough testing and accountability throughout an AI project's lifecycle.
In the initial phase of an AI project called use case discovery, data scientists work with businesses to define the problem. They translate it into an ML problem statement and set clear objectives and KPIs.
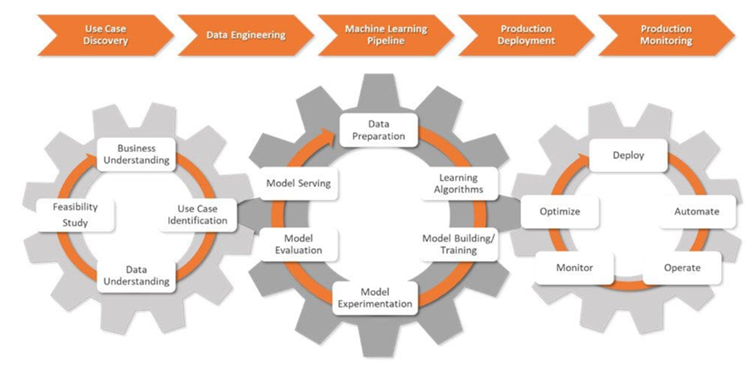
Next, data scientists team up with data engineers. They gather data from various sources, and then clean, process, and validate this data.
When data is ready for modeling, data scientists design and deploy robust ML pipelines, integrated with CI/CD processes. These pipelines support testing and experimentation and help track data, model lineage, and associated KPIs across all experiments.
In the production deployment stage, ML models are deployed in the chosen environment: cloud, on-premises, or hybrid.
Data scientists monitor the models and infrastructure, using key metrics to spot changes in data or model performance. When they detect changes, they update the algorithms, data, and hyperparameters, creating new versions of the ML pipelines. They also manage memory and computing resources to keep models scalable and running smoothly.
MLOps Tools Meet AI Projects
Picture a data scientist developing an AI application to enhance a client’s product design process. This solution will accelerate the prototyping phase by providing AI-generated design alternatives based on specified parameters.
Data scientists navigate through diverse tasks, from designing the framework to monitoring the AI model in real-time. They need the right tools and a grasp of how to use them at every step.
Better LLM Performance, Smarter AI Apps
At the core of an accurate and adaptable AI solution are vector databases and these key tools to boost LLMs performance:
Guardrails is an open-source Python package that helps data scientists add structure, type, and quality checks to LLM outputs. It automatically handles errors and takes actions, like re-querying the LLM, if validation fails. It also enforces guarantees on output structure and types, such as JSON.
Data scientists need a tool for efficient indexing, searching, and analyzing large datasets. This is where LlamaIndex steps in. The framework provides powerful capabilities to manage and extract insights from extensive information repositories.
The DUST framework allows LLM-powered applications to be created and deployed without execution code. It helps with the introspection of model outputs, supports iterative design improvements, and tracks different solution versions.
Track Experiments and Manage Model Metadata
Data scientists experiment to better understand and improve ML models over time. They need tools to set up a system that enhances model accuracy and efficiency based on real-world results.
MLflow is an open-source powerhouse, useful to oversee the entire ML lifecycle. It provides features like experiment tracking, model versioning, and deployment capabilities. This suite lets data scientists log and compare experiments, monitor metrics, and keep ML models and artifacts organized.
Comet ML is a platform for tracking, comparing, explaining, and optimizing ML models and experiments. Data scientists can use Comet ML with Scikit-learn, PyTorch, TensorFlow, or HuggingFace — it will provide insights to improve ML models.
Amazon SageMaker covers the entire machine-learning lifecycle. It helps label and prepare data, as well as build, train, and deploy complex ML models. Using this tool, data scientists quickly deploy and scale models across various environments.
Microsoft Azure ML is a cloud-based platform that helps streamline machine learning workflows. It supports frameworks like TensorFlow and PyTorch, and it can also integrate with other Azure services. This tool helps data scientists with experiment tracking, model management, and deployment.
DVC (data version control) is an open-source tool meant to handle large data sets and machine learning experiments. This tool makes data science workflows more agile, reproducible, and collaborative. DVC works with existing version control systems like Git, simplifying how data scientists track changes and share progress on complex AI projects.
Optimize and Manage ML Workflows
Data scientists need optimized workflows to achieve smoother and more effective processes on AI projects. The following tools can assist:
Prefect is a modern open-source tool that data scientists use to monitor and orchestrate workflows. Lightweight and flexible, it has options to manage ML pipelines (Prefect Orion UI and Prefect Cloud).
Metaflow is a powerful tool for managing workflows. It is meant for data science and machine learning. It eases focusing on model development without the hassle of MLOps complexities.
Kedro is a Python-based tool that helps data scientists keep a project reproducible, modular, and easy to maintain. It applies key software engineering principles to machine learning (modularity, separation of concerns, and versioning). This helps data scientists build efficient, scalable projects.
Manage Data and Control Pipeline Versions
ML workflows need precise data management and pipeline integrity. With the right tools, data scientists stay on top of those tasks and handle even the most complex data challenges with confidence.
Pachyderm helps data scientists automate data transformation and offers robust features for data versioning, lineage, and end-to-end pipelines. These features can run seamlessly on Kubernetes. Pachyderm supports integration with various data types: images, logs, videos, CSVs, and multiple languages (Python, R, SQL, and C/C ). It scales to handle petabytes of data and thousands of jobs.
LakeFS is an open-source tool designed for scalability. It adds Git-like version control to object storage and supports data version control on an exabyte scale. This tool is ideal for handling extensive data lakes. Data scientists use this tool to manage data lakes with the same ease as they handle code.
Test ML Models for Quality and Fairness
Data scientists focus on developing more reliable and fair ML solutions. They test models to minimize biases. The right tools help them assess key metrics, like accuracy and AUC, support error analysis and version comparison, document processes, and integrate seamlessly into ML pipelines.
Deepchecks is a Python package that assists with ML models and data validation. It also eases model performance checks, data integrity, and distribution mismatches.
Truera is a modern model intelligence platform that helps data scientists increase trust and transparency in ML models. Using this tool, they can understand model behavior, identify issues, and reduce biases. Truera provides features for model debugging, explainability, and fairness assessment.
Kolena is a platform that enhances team alignment and trust through rigorous testing and debugging. It provides an online environment for logging results and insights. Its focus is on ML unit testing and validation at scale, which is key to consistent model performance across different scenarios.
Bring Models to Life
Data scientists need reliable tools to efficiently deploy ML models and serve predictions reliably. The following tools help them achieve smooth and scalable ML operations:
BentoML is an open platform that helps data scientists handle ML operations in production. It helps streamline model packaging and optimize serving workloads for efficiency. It also assists with faster setup, deployment, and monitoring of prediction services.
Kubeflow simplifies deploying ML models on Kubernetes (locally, on-premises, or in the cloud). With this tool, the entire process becomes straightforward, portable, and scalable. It supports everything from data preparation to prediction serving.
Simplify the ML Lifecycle With End-To-End MLOps Platforms
End-to-end MLOps platforms are essential for optimizing the machine learning lifecycle, offering a streamlined approach to developing, deploying, and managing ML models effectively. Here are some leading platforms in this space:
Amazon SageMaker offers a comprehensive interface that helps data scientists handle the entire ML lifecycle. It streamlines data preprocessing, model training, and experimentation, enhancing collaboration among data scientists. With features like built-in algorithms, automated model tuning, and tight integration with AWS services, SageMaker is a top pick for developing and deploying scalable machine learning solutions.
Microsoft Azure ML Platform creates a collaborative environment that supports various programming languages and frameworks. It allows data scientists to use pre-built models, automate ML tasks, and seamlessly integrate with other Azure services, making it an efficient and scalable choice for cloud-based ML projects.
Google Cloud Vertex AI provides a seamless environment for both automated model development with AutoML and custom model training using popular frameworks. Integrated tools and easy access to Google Cloud services make Vertex AI ideal for simplifying the ML process, helping data science teams build and deploy models effortlessly and at scale.
Signing Off
MLOps is not just another hype. It is a significant field that helps professionals train and analyze large volumes of data more quickly, accurately, and easily. We can only imagine how this will evolve over the next ten years, but it's clear that AI, big data, and automation are just beginning to gain momentum.
以上是MLOps:如何建立工具包來提高 AI 專案效能的詳細內容。更多資訊請關注PHP中文網其他相關文章!