


視覺與機器人學習的深度融合。
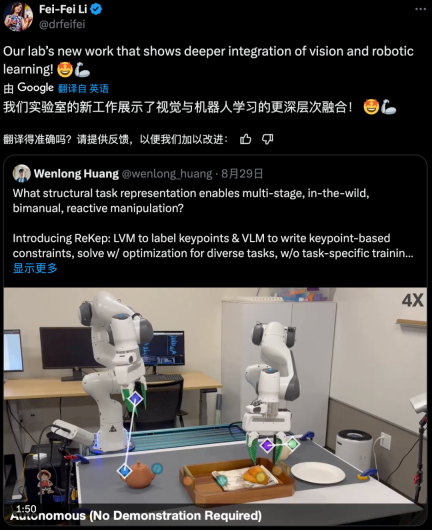
當兩隻機器手絲滑地互相合作疊衣服、倒茶、將鞋子打包時,加上最近老上頭條的1X 人形機器人NEO,你可能會產生一種感覺:我們似乎開始進入機器人時代了。

事實上,這些絲滑動作正是先進機器人技術 + 精妙框架設計 + 多模態大模型的產物。
我們知道,有用的機器人往往需要與環境進行複雜精妙的交互,而環境則可被表示成空間域和時間域上的約束。
舉個例子,如果要讓機器人倒茶,那麼機器人首先需要抓住茶壺手柄並使之保持直立,不潑灑出茶水,然後平穩移動,一直到讓壺口與杯口對齊,之後以一定角度傾斜茶壺。這裡,約束條件不僅包含中間目標(如對齊壺口與杯口),還包括過渡狀態(如保持茶壺直立);它們共同決定了機器人相對於環境的動作的空間、時間和其它組合要求。
然而,現實世界紛繁複雜,如何建構這些限制是一個極具挑戰性的問題。
近日,李飛飛團隊在這一研究方向取得了一個突破,提出了關係關鍵點約束(ReKep/Relational Keypoint Constraints)。簡單來說,這個方法就是將任務表示成一個關係關鍵點序列。並且,這套框架還能很好地與 GPT-4o 等多模態大模型很好地整合。從示範影片來看,這種方法的表現相當不錯。該團隊也已發布相關程式碼。本文一為 Wenlong Huang。

論文標題:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
。網址:https://rekep-robot.github.io/rekep.pdf
專案網站:https://rekep-robot.github.io
代碼位址:https://github.com/huangwl18/ReKep
李飛飛表示,該工作展示了視覺與機器人學習的更深層融合!雖然論文中沒有提及李飛飛在今年 5 年初創立的專注空間智慧的 AI 公司 World Labs,但 ReKep 顯然在空間智慧方面大有潛力。
方法
關係關鍵點約束(Recep)
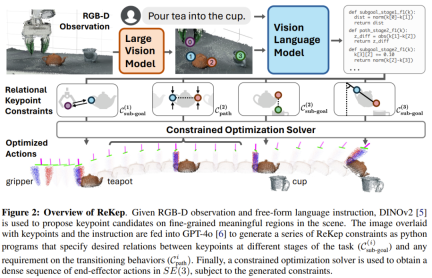
首先,我們先來看一個ReKep 實例。這裡先假設已經指定了一組 K 個關鍵點。具體來說,每個關鍵點 k_i ∈ ℝ^3 都是在具有笛卡爾座標的場景表面上的 3D 點。 一個ReKep 實例便是一個這樣的函數:?: ℝ^{K×3}→ℝ;其可將一組關鍵點(記為?)映射成一個無界成本(unbounded cost),當?(?) ≤ 0 時即表示滿足限制條件。至於具體實現,該團隊將函數 ? 實現為了一個無狀態 Python 函數,其中包含對關鍵點的 NumPy 操作,這些操作可能是非線性的和非凸的。本質上講,一個 ReKep 實例編碼了關鍵點之間的一個所需空間關係。 但是,一個操作任務通常涉及多個空間關係,並且可能具有多個與時間有關的階段,其中每個階段都需要不同的空間關係。為此,團隊的做法是將一個任務分解成N 個階段並使用ReKep 為每個階段i ∈ {1, ..., N } 指定兩類限制: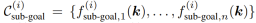
- 一組子目標約束
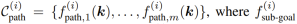
- 一組路徑約束一組路徑約束一組路徑約束一組路徑約束一組路徑限制
其中  編碼了階段 i 結束時要實現的一個關鍵點關係,而
編碼了階段 i 結束時要實現的一個關鍵點關係,而  編碼了階段 i 內每個狀態要滿足的一個關鍵點關係。以圖 2 的倒茶任務為例,包含三個階段:抓拿、對齊、倒茶。
編碼了階段 i 內每個狀態要滿足的一個關鍵點關係。以圖 2 的倒茶任務為例,包含三個階段:抓拿、對齊、倒茶。
階段 1 子目標約束是將末端執行器伸向茶壺把手。階段 2 子目標約束是讓茶壺口位於杯口上方。此外,階段 2 路徑約束是保持茶壺直立,避免茶水灑出。最後的階段 3 子目標限制是到達指定的倒茶角度。
使用 ReKep 將操作任務定義成約束最佳化問題
使用 ReKep,可將機器人操作任務轉換成一個涉及子目標和路徑的約束最佳化問題。這裡將末端執行器姿勢記為 ? ∈ SE (3)。為了執行操作任務,這裡的目標是取得整體的離散時間軌跡?_{1:T}:
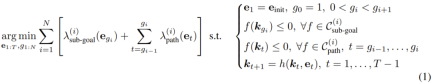
也就是說,對於每個階段i,此最佳化問題的目標是:基於給定的ReKep 約束集和輔助成本,找到一個末端執行器姿勢作為下一個子目標(及其相關時間),以及實現該子目標的姿勢序列。此公式可視為軌跡優化中的 direct shooting。
分解和演算法實例化
為了能即時地求解上述公式1,該團隊選擇對整體問題進行分解,僅針對下一個子目標和達成該子目標的相應路徑進行最佳化。演算法 1 給出了該過程的偽代碼。

其中子目標問題的解公式為:
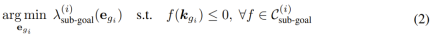
路徑問題的解公式為:
 路徑問題的解公式為:
路徑問題的解公式為: 現實環境複雜多變,有時候在任務進行過程中,上一階段的子目標限制可能不再成立(例如倒茶時茶杯被拿走了),這時候需要重新規劃。該團隊的做法是檢查路徑是否有問題。如果發現問題,就迭代式地回溯到前一階段。
現實環境複雜多變,有時候在任務進行過程中,上一階段的子目標限制可能不再成立(例如倒茶時茶杯被拿走了),這時候需要重新規劃。該團隊的做法是檢查路徑是否有問題。如果發現問題,就迭代式地回溯到前一階段。 為了求解2 和3 式,團隊使用了一個前向模型h,其可在最佳化過程中根據∆? 估計∆?。具體來說,給定末端執行器姿勢∆? 的變化,透過應用相同的相對剛性變換?′[grasped] = T_{∆?}・?[grasped] 來計算關鍵點位置的變化,同時假設其它關鍵點保持靜止。
關鍵點提議和 ReKep 生成
為了讓該系統能在實際情況下自由地執行各種任務,該團隊還用上了大模型!具體來說,他們使用大型視覺模型和視覺 - 語言模型設計了一套管道流程來實現關鍵點提議和 ReKep 生成。 關鍵點提議給定一張 RGB 圖像,首先用 DINOv2 提取圖塊層面的特徵 F_patch。然後執行雙線性內插以將特徵上取樣到原始影像大小,F_interp。為了確保提議涵蓋場景中的所有相關物體,他們使用了 Segment Anything(SAM)來提取場景中的所有遮罩 M = {m_1, m_2, ... , m_n}。 對於每個遮罩 j,使用 k 均值(k = 5)和餘弦相似度度量對遮罩特徵 F_interp [m_j] 進行聚類。聚類的質心用作候選關鍵點,再使用經過校準的 RGB-D 相機將其投影到世界坐標 ℝ^3。距離候選關鍵點 8cm 以內的其它候選將被過濾掉。總體而言,團隊發現此過程可以識別大量細粒度且語義上有意義的物件區域。 ReKep 產生取得候選關鍵點後,再將它們疊加在原始 RGB 影像上,並標註數字。結合特定任務的語言指令,再查詢 GPT-4o 以產生所需階段的數量以及每個階段 i 對應的子目標限制和路徑限制。
實驗
團隊透過實驗對這套約束設計進行了驗證,並嘗試解答了以下三個問題:1. 該框架自動建構和合成操作行為的表現如何?2. How well does the system generalize to new objects and manipulation strategies?
3. How might various components contribute to system failure?
Using ReKep to operate two robotic arms
They examined the system through a series of tasks for multi-stage (m), field/practical scenarios (w), two-hand (b) and reaction (r) behavior. These tasks include pouring tea (m, w, r), arranging books (w), recycling cans (w), taping boxes (w, r), folding laundry (b), packing shoes (b) and collaborative folding (b, r).
The results are shown in Table 1, where success rate data are reported.
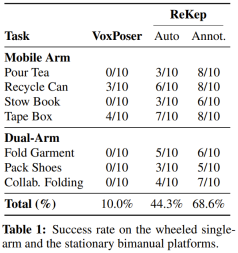
Overall, the newly proposed system is able to construct the correct constraints and execute in an unstructured environment even if task-specific data or environment models are not provided they. Notably, ReKep effectively handles the core puzzle of each task.
Here are some animations of the actual execution process:


Generalization of the operation strategy
The team explored the generalization performance of the new strategy based on the laundry folding task. In short, it’s about seeing if the system can fold different kinds of clothes — which requires geometry and common sense reasoning.
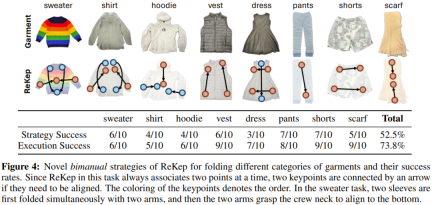
GPT-4o is used here, and the prompt contains only generic instructions without contextual examples. "Strategy success" means that the generated ReKep is feasible, and "execution success" measures the system success rate of a given feasible strategy for each type of clothing.
The results are interesting. It can be seen that the system uses different strategies for different clothes, and some of the methods of folding clothes are the same as those commonly used by humans.


Analyzing system errors
The design of the framework is modular and therefore easy to Convenient for analyzing system errors. The team manually inspected the failure cases encountered in the experiments in Table 1 and then based on this calculated the likelihood that the modules caused the error, taking into account their temporal dependencies in the pipeline process. The results are shown in Figure 5.

It can be seen that among the different modules, the key point tracker produces the most errors because frequent and intermittent occlusions make it difficult for the system to track accurately.
以上是李飛飛團隊提出ReKep,讓機器人具備空間智能,還能整合GPT-4o的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM
軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM軟AI(被定義為AI系統,旨在使用近似推理,模式識別和靈活的決策執行特定的狹窄任務 - 試圖通過擁抱歧義來模仿類似人類的思維。 但是這對業務意味著什麼
 為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM
為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM答案很明確 - 只是雲計算需要向雲本地安全工具轉變,AI需要專門為AI獨特需求而設計的新型安全解決方案。 雲計算和安全課程的興起 在
 生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM企業家,並使用AI和Generative AI來改善其業務。同時,重要的是要記住生成的AI,就像所有技術一樣,都是一個放大器 - 使得偉大和平庸,更糟。嚴格的2024研究O
 Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM
Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM解鎖嵌入模型的力量:深入研究安德魯·NG的新課程 想像一個未來,機器可以完全準確地理解和回答您的問題。 這不是科幻小說;多虧了AI的進步,它已成為R
 大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM
大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM大型語言模型(LLM)和不可避免的幻覺問題 您可能使用了諸如Chatgpt,Claude和Gemini之類的AI模型。 這些都是大型語言模型(LLM)的示例,在大規模文本數據集上訓練的功能強大的AI系統
 60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根據行業和搜索類型,AI概述可能導致有機交通下降15-64%。這種根本性的變化導致營銷人員重新考慮其在數字可見性方面的整個策略。 新的
 麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大學(Elon University)想像的數字未來中心的最新報告對近300名全球技術專家進行了調查。由此產生的報告“ 2035年成為人類”,得出的結論是,大多數人擔心AI系統加深的採用


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Atom編輯器mac版下載
最受歡迎的的開源編輯器

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

WebStorm Mac版
好用的JavaScript開發工具

