
Mamba作者新作:將Llama3蒸餾成混合線性 RNN

- 王林原創
- 2024-09-02 13:41:30938瀏覽
Transformer 在深度學習領域取得巨大成功的關鍵是注意力機制。注意力機制讓基於 Transformer 的模型專注於與輸入序列相關的部分,實現了更好的上下文理解。然而,注意力機制的缺點是計算開銷大,會隨輸入規模而二次成長,Transformer 也因此難以處理非常長的文字。
前段時間,Mamba 的出現打破了這個局面,它可以隨上下文長度的增加實現線性擴展。隨著 Mamba 的發布,這些狀態空間模型 (SSM) 在中小型規模上已經可以與 Transformer 匹敵,甚至超越 Transformer,同時還能維持隨序列長度的線性可擴展性,這讓 Mamba 具有有利的部署特性。
簡單來說,Mamba 首先引入了一個簡單卻有效的選擇機制,其可根據輸入對SSM 進行重新參數化,從而可讓模型在濾除不相關資訊的同時無限期地保留必要和相關的數據。
最近,一篇題為《The Mamba in the Llama: Distilling and Accelerating Hybrid Models》的論文證明:透過重用注意力層的權重,大型transformer 可以被蒸餾成大型混合線性RNN,只需最少的額外計算,同時可保留其大部分生成品質。
由此產生的混合模型包含四分之一的注意力層,在聊天基準測試中實現了與原始Transformer 相當的性能,並且在聊天基準測試和一般基準測試中優於使用數萬億token 從頭開始訓練的開源混合Mamba 模型。此外,該研究還提出了一種硬體感知推測解碼演算法,可以加快 Mamba 和混合模型的推理速度。

論文地址:https://arxiv.org/pdf/2408.15237
研究的最佳表現模型是從Llama3-8B-Instruct 中蒸餾出來的,在AlpacaEval 2 上相對於GPT-4 實現了29.61 的長度控制(length-controlled)勝率,在MT-Bench 上實現了7.35 的勝率,超越了最好的指令調整線性RNN 模型。
方法
知識蒸餾(KD)作為一種模型壓縮技術,用於將大型模型(教師模型)的知識遷移到較小的模型(學生模型)中,旨在訓練學生網路模仿教師網路的行為。該研究旨在對 Transformer 進行蒸餾,使其性能與原始語言模型相當。
研究提出了一種多層蒸餾方法,結合了漸進式蒸餾、監督微調和定向偏好最佳化。與普通蒸餾相比,這種方法可以獲得更好的困惑度和下游評估結果。
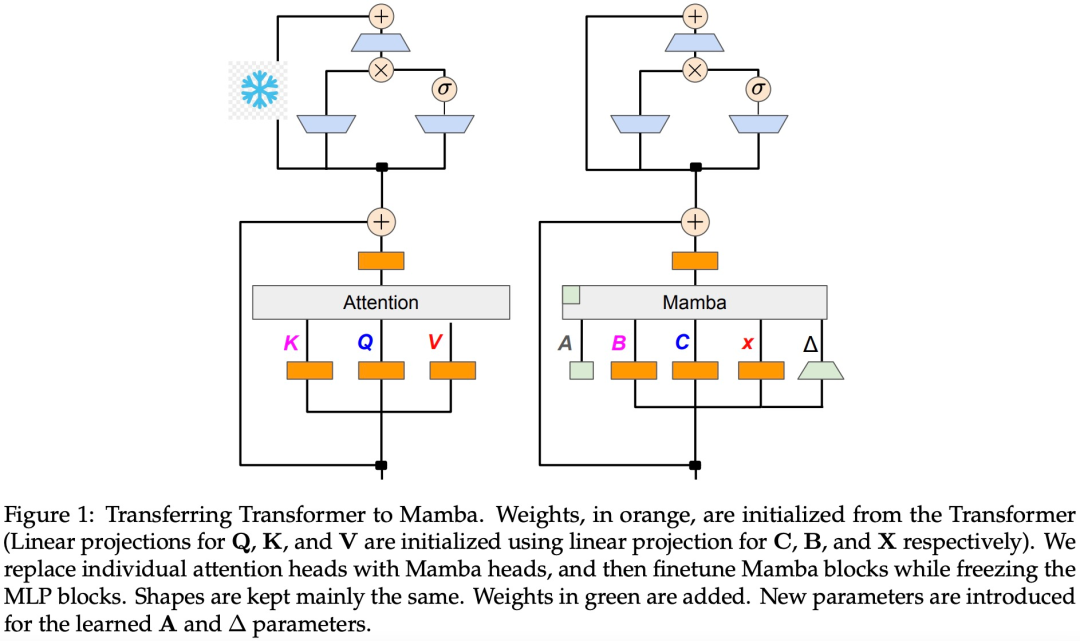
研究假設來自 Transformer 的大部分知識都保留在從原始模型遷移而來的 MLP 層中,並專注於蒸餾 LLM 的微調和對齊步驟。在此階段,MLP 層保持凍結狀態,Mamba 層進行訓練。
研究認為線性 RNN 和注意力機制之間自然存在一些關聯。刪除 softmax 可以線性化注意力公式:
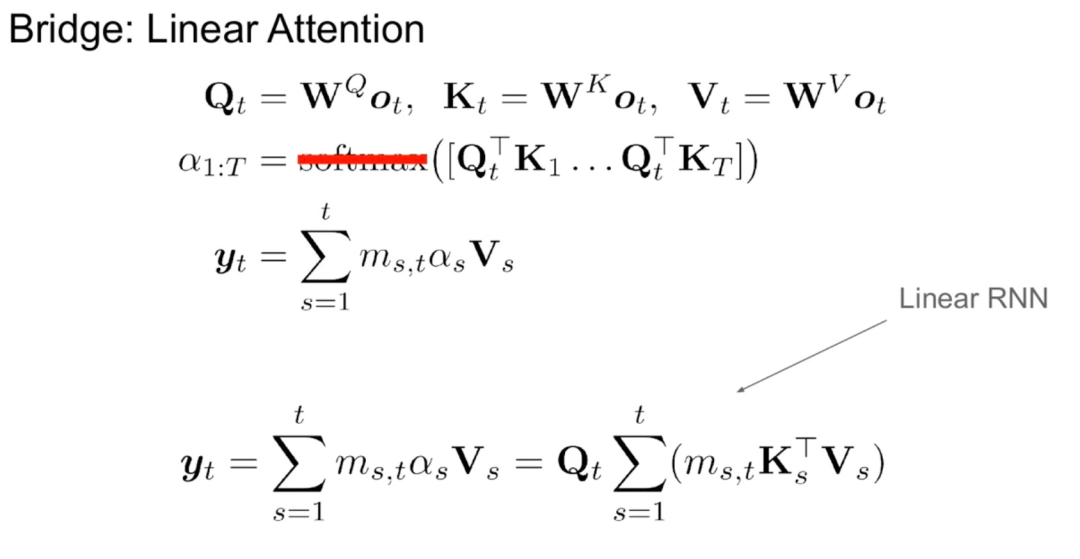
但線性化注意力會導致模型能力退化。為了設計一個有效的蒸餾線性 RNN,研究盡可能接近原始 Transformer 參數化,同時以有效的方式擴展線性 RNN 的容量。該研究並沒有嘗試讓新模型捕捉精確的原始注意力函數,而是使用線性化形式作為蒸餾的起點。
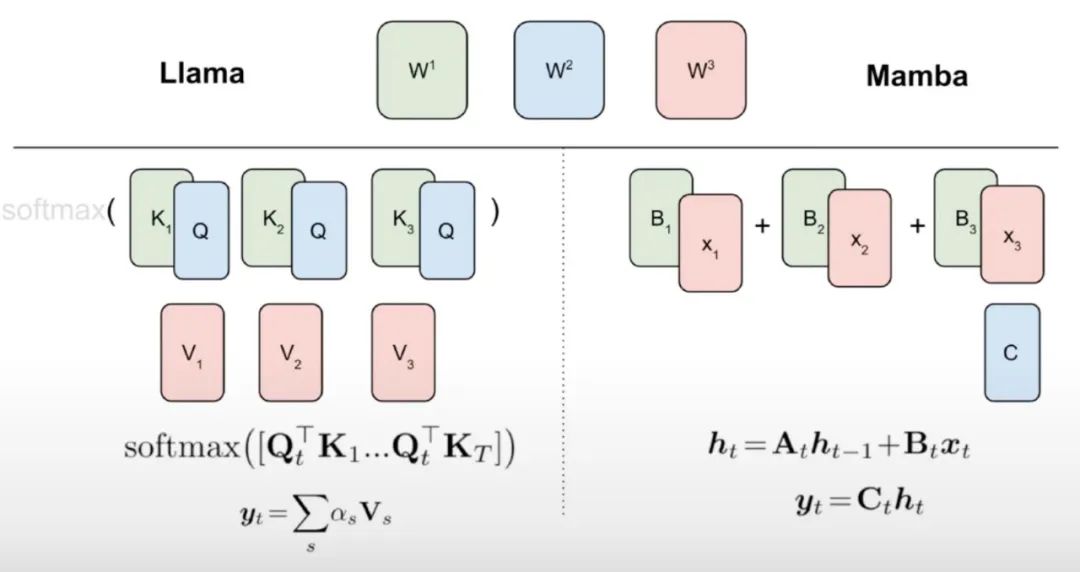
如演算法 1 所示,研究將來自註意力機制的標準 Q、K、V 頭直接饋入到 Mamba 離散化中,然後應用得到的線性 RNN。這可以看作是使用線性注意力進行粗略初始化,並允許模型透過擴展的隱藏狀態學習更豐富的互動。

研究用微調線性 RNN 層直接取代 Transformer 注意力頭,保持 Transformer MLP 層不變,不訓練它們。這種方法還需要處理其他元件,例如跨頭共享鍵和值的分組查詢注意力。研究團隊注意到,這種架構與許多 Mamba 系統中使用的架構不同,這種初始化允許用線性 RNN 區塊取代任何注意力區塊。
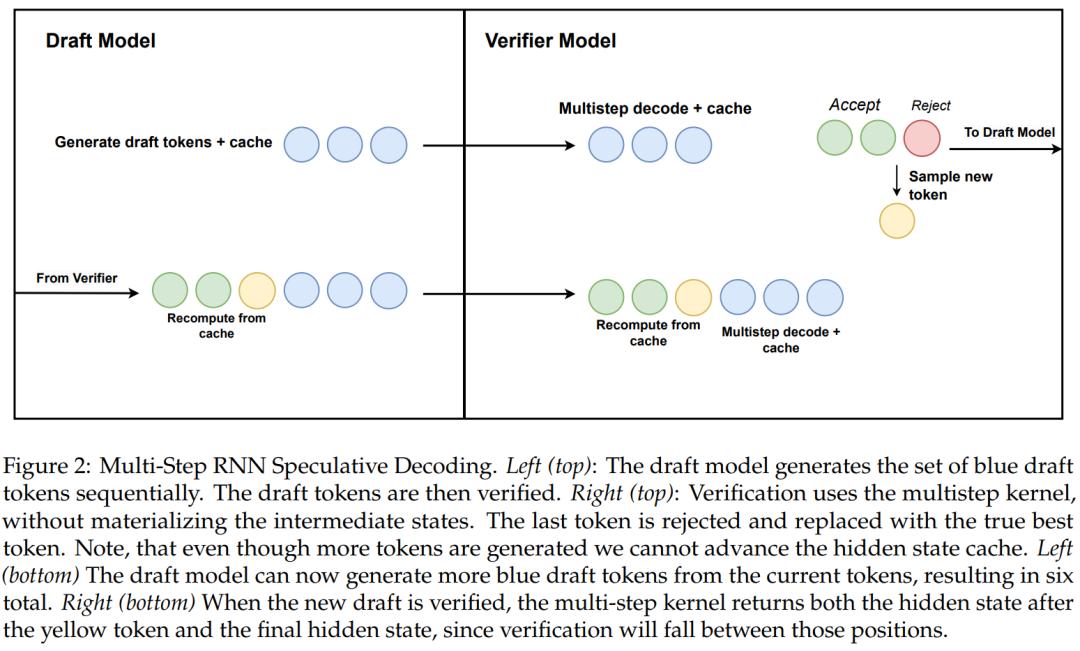
研究也提出了一種使用硬體感知多步驟產生的線性 RNN 推測解碼新演算法。
演算法 2 和圖 2 顯示了完整的演算法。該方法僅在快取中保留一個 RNN 隱藏狀態以進行驗證,並根據多步驟核心的成功來延遲推進它。由於蒸餾模型包含 transformer 層,研究也將推測解碼擴展到 Attention/RNN 混合架構。在此設定中,RNN 層根據演算法 2 執行驗證,而 Transformer 層僅執行平行驗證。

為了驗證此方法的有效性,研究使用 Mamba 7B 和 Mamba 2.8B 作為目標模型進行推測。結果如表 1 所示。
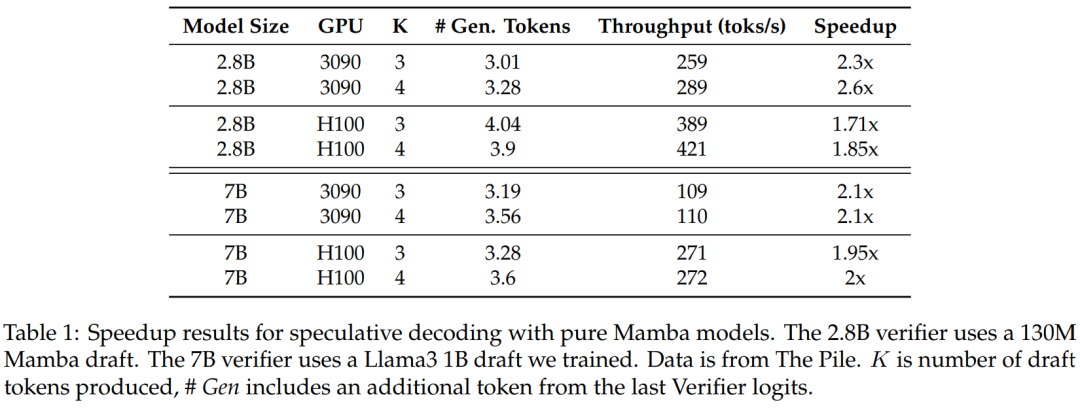
圖 3 顯示了多步驟內核本身的效能特徵。
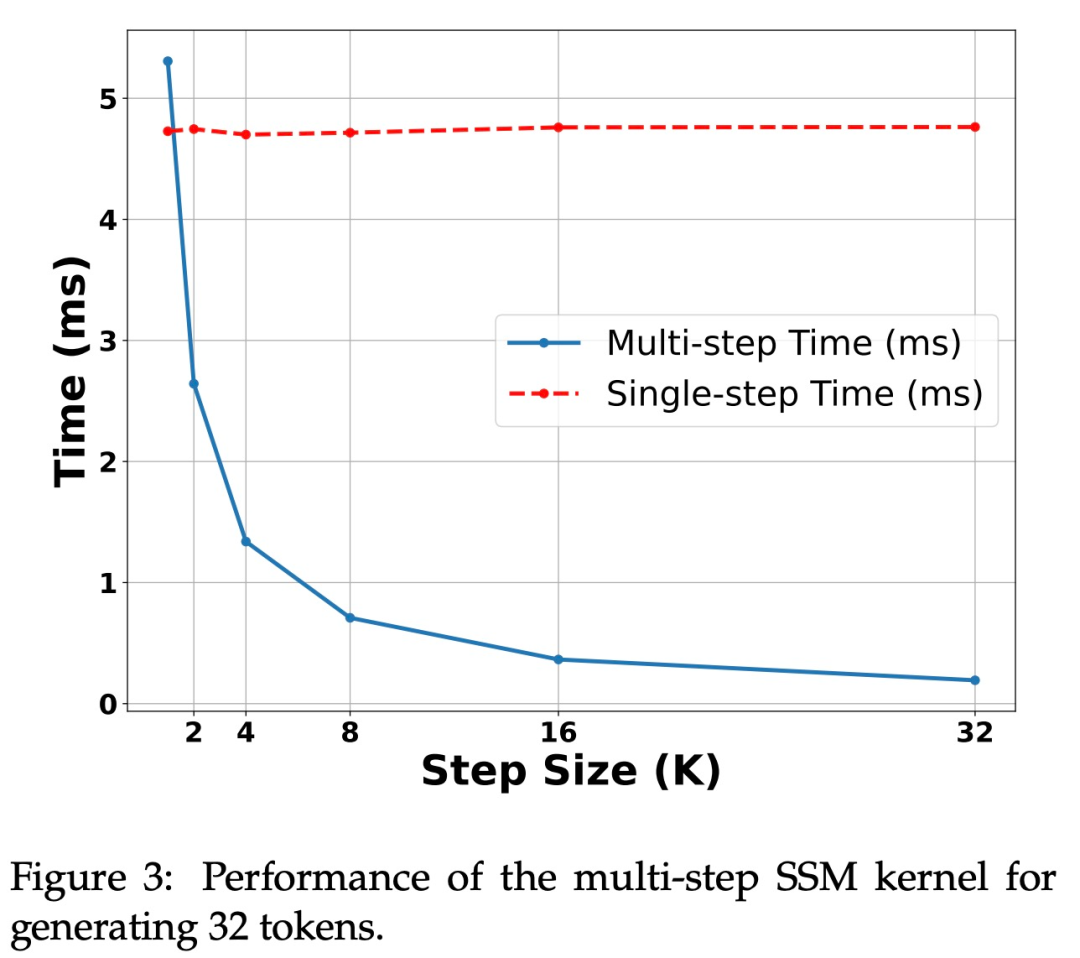
H100 GPU 上的加速。該研究提出的演算法在 Ampere GPU 上表現出強大的效能,如上表 1 所示。但在 H100 GPU 上面臨巨大挑戰。這主要是因為 GEMM 操作速度太快,這使得快取和重新計算操作產生的開銷更加明顯。實際上,該研究的演算法的簡單實作(使用多個不同的核心呼叫)在 3090 GPU 上實現了相當大的加速,但在 H100 上根本沒有加速。
實驗及結果
研究使用兩個LLM 聊天模型進行實驗:Zephyr-7B 是在Mistral 7B 模型的基礎上微調而來, 以及Llama- 3 Instruct 8B。對於線性 RNN 模型,研究使用 Mamba 和 Mamba2 的混合版本,其中註意力層分別為 50%、25%、12.5% 和 0%,並將 0% 稱為純 Mamba 模型。 Mamba2 是 Mamba 的變體架構,主要針對最近的 GPU 架構而設計。
在聊天基準上的評估
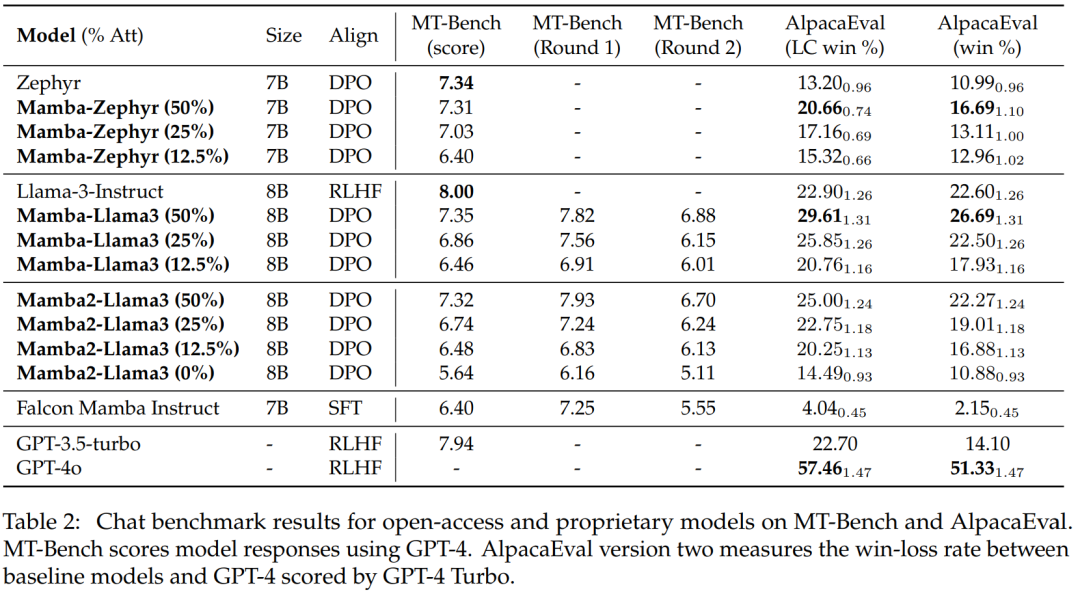
表 2 顯示了模型在聊天基准上的性能,主要對比的模型是大型 Transformer 模型。結果顯示:
蒸餾後的混合Mamba 模型(50%) 在MT 基準測試中取得的分數與教師模型相似,在LC 勝率和總體勝率方面都略優於AlpacaEval 基準測試中的教師模型。
蒸餾後的混合 Mamba (25% 和 12.5%) 的性能在 MT 基準測試中略遜於教師模型,但即使在 AlpcaaEval 中具有更多參數,它仍然超越了一些大型 Transformer。
蒸餾後的純 (0%) Mamba 模型的準確度確實顯著下降。
值得注意的是,蒸餾後的混合模型的表現優於 Falcon Mamba,後者是從頭開始訓練的,使用了超過 5T 的 token。
一般基準評估
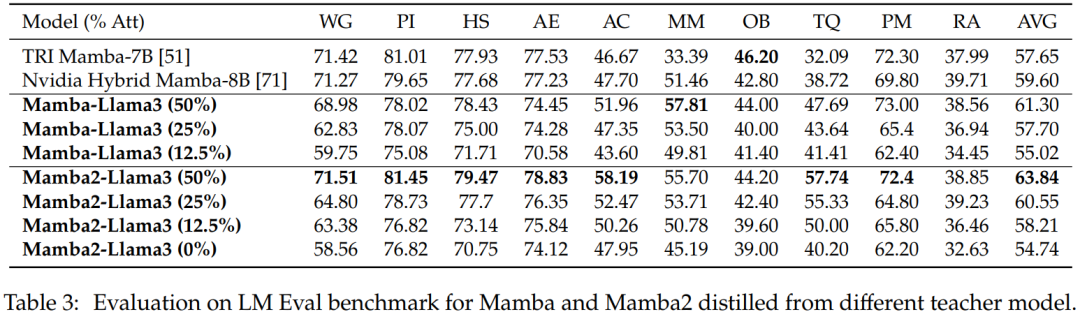
零樣本評估。表 3 顯示了從不同教師模型中蒸餾出的 Mamba 和 Mamba2 在 LM Eval 基準中的零樣本表現。從 Llama-3 Instruct 8B 中蒸餾出的混合 Mamba-Llama3 和 Mamba2-Llama3 模型與從頭開始訓練的開源 TRI Mamba 和 Nvidia Mamba 模型相比表現更好。
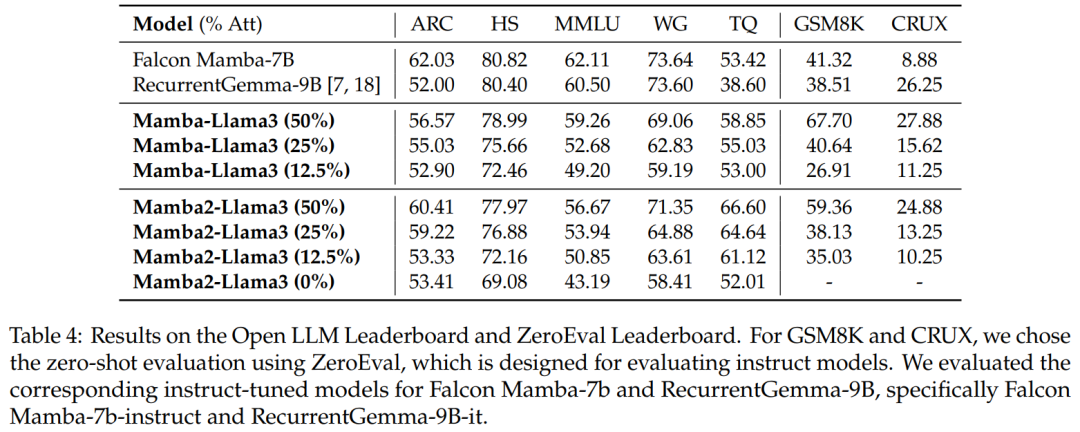
基準評估。表 4 顯示經過蒸餾的混合模型的效能與 Open LLM Leaderboard 上最好的開源線性 RNN 模型相匹配,同時在 GSM8K 和 CRUX 中優於相應的開源指令模型。
混合推測性解碼
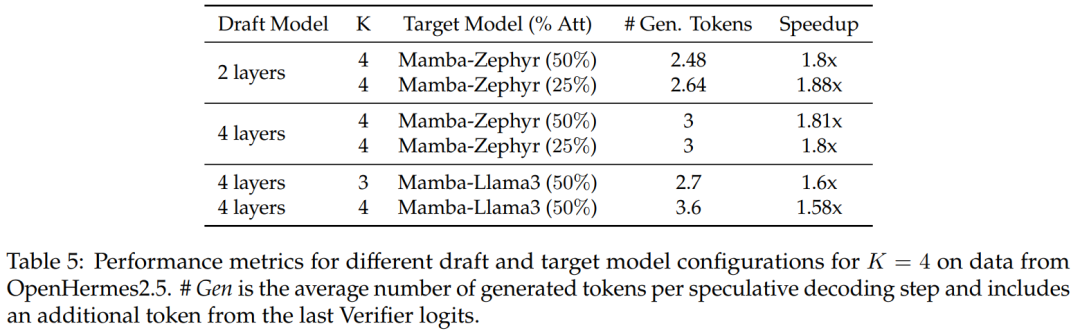
對於50% 和25% 的蒸餾模型,與非推測基線相比,研究在Zephyr-Hybrid 上實現了超過1.8 倍的加速。
實驗還表明,該研究訓練的 4 層 draft 模型實現了更高的接收率,不過由於 draft 模型規模的增加,額外開銷也變大了。在後續工作中,研究將專注於縮小這些 draft 模型。
與其它蒸餾方法的比較:表 6(左)比較了不同模型變體的困惑度。研究在一個 epoch 內使用 Ultrachat 作為種子提示進行蒸餾,並比較困惑度。結果發現刪除更多層會使情況變得更糟。該研究還將蒸餾方法與先前的基線進行了比較,發現新方法顯示出較小的退化,而Distill Hyena 模型是在WikiText 數據集中使用小得多的模型進行訓練的,並且顯示出較大的困惑度退化。
表 6(右)展示了單獨使用 SFT 或 DPO 不會產生太大的改進,而使用 SFT + DPO 會產生最佳分數。
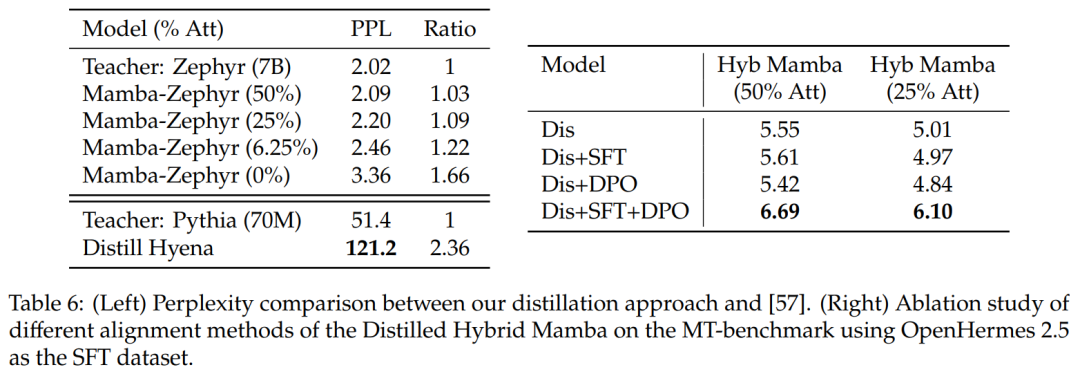
表 7 比較了幾種不同模型的消融研究。表 7(左)展示了使用各種初始化的蒸餾結果,表 7(右)顯示漸進式蒸餾和將注意層與 Mamba 交錯帶來的收益較小。
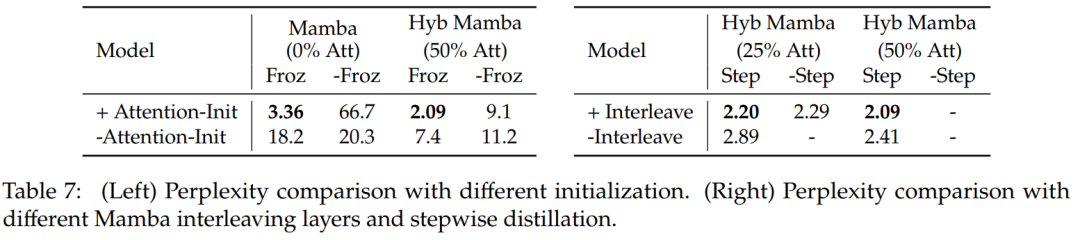
表 8 比較了使用兩種不同初始化方法的混合模型的性能:結果證實注意力權重的初始化至關重要。

表 9 比較了有 Mamba 區塊和沒有 Mamba 區塊的模型的效能。有 Mamba 區塊的模型效能明顯優於沒有 Mamba 區塊的模型。這證實了添加 Mamba 層至關重要,並且性能的提高不僅僅歸功於剩餘的注意力機制。

有興趣的讀者可以閱讀論文原文,並了解更多研究內容。
以上是Mamba作者新作:將Llama3蒸餾成混合線性 RNN的詳細內容。更多資訊請關注PHP中文網其他相關文章!