
機器人策略學習的Game Changer?柏克萊提出Body Transformer

- 王林原創
- 2024-08-19 16:35:031124瀏覽
過去幾年間,Transformer 架構已經取得了巨大的成功,同時其也衍生出了大量變體,例如擅長處理視覺任務的 Vision Transformer(ViT)。本文要介紹的 Body Transformer(BoT) 則是非常適合機器人策略學習的 Transformer 變體。
我們知道,物理智能體在執行動作的校正和穩定時,往往會根據其感受到的外部刺激的位置給出空間上的響應。例如人類對這些刺激的反應迴路位於脊髓神經迴路層面,它們專門負責單一致動器的反應。起校正作用的局部執行是高效率運動的主要因素,這對機器人來說也特別重要。
但先前的學習架構通常都沒有建立感測器和致動器之間的空間關聯。鑑於機器人策略使用的架構基本是為自然語言和電腦視覺開發的架構,它們常常無法有效地利用機器人機體的結構。
不過,Transformer 在這方面還是頗具潛力的,已有研究表明,Transformer 可以有效地處理長序列依賴關係,還能輕鬆地吸收大量資料。 Transformer 架構原本是為非結構化自然語言處理(NLP)任務所開發的。在這些任務中(例如語言翻譯),輸入序列通常會被映射到一個輸出序列。
基於這一觀察,加州大學柏克萊分校 Pieter Abbeel 教授領導的團隊提出了 Body Transformer(BoT),增加了對機器人機體上的感測器和致動器的空間位置的關注。

論文標題:Body Transformer: Leveraging Robot Embodiment for Policy Learning
論文地址//arxiv.org/pdf/2408.06316v1
專案網站:https://sferrazza.cc/bot_site
https ://github.com/carlosferrazza/BodyTransformer
具體來說,BoT 是將機器人機體建模成圖(graph),其中的節點即為其感測器和執行器。然後,其在註意力層上使用高度稀疏的掩碼,以防止每個節點關注其直接近鄰之外的部分。將多個結構相同的 BoT 層連接起來,就能匯集整個圖的訊息,這樣便不會損害該架構的表徵能力。 BoT 在模仿學習和強化學習方面都表現不俗,甚至被一些人認為是策略學習的「Game Changer」。
Body Transformer
如果機器人學習策略使用原始 Transformer 架構為骨幹,則通常會忽略機器人機體結構所提供的有用資訊。但實際上,這些結構資訊能為 Transformer 提供更強的歸納偏壓。該團隊在利用這些資訊的同時也保留了原始架構的表徵能力。
Body Transformer(BoT)架構是基於遮罩式註意力。在這個架構的每一層中,一個節點都只能看到其自身和其直接近鄰節點的資訊。如此一來,資訊就會依照圖的結構而流動,其中上游層會根據局部資訊執行推理,下游層則能匯集更多來自更遠節點的全局資訊。
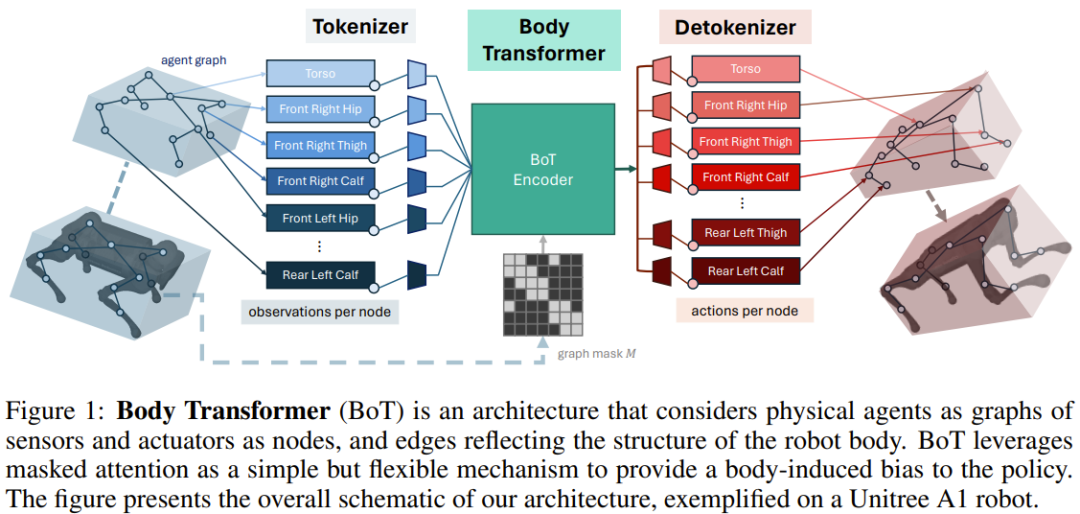
如圖1 所示,BoT 架構包含以下元件:
1.tokenizer:將感測器輸入投射成對應的節點嵌入;
2.Transformer 編碼器:處理輸入嵌入並產生同樣維度的輸出特徵;
3.detokenizer:解除token 化,即將特徵解碼成動作(或用於強化學習批評訓練的價值) 。
tokenizer
團隊選擇將觀察向量對應成局部觀察構成的圖。
在實踐中,他們將全局量分配給機器人機體的根元素,將局部量分配給表示對應肢體的節點。這種分配方式與先前的 GNN 方法類似。
然後,使用線性層將局部狀態向量投射成嵌入向量。每個節點的狀態都會被饋送給其節點特定的可學習的線性投射,從而得到一個包含 n 個嵌入的序列,其中 n 表示節點的數量(或序列長度)。這不同於先前的研究成果,它們通常僅使用單一共享的可學習的線性投射來處理多任務強化學習中不同數量的節點。
BoT 編碼器
團隊使用的骨幹網路是一個標準的多層 Transformer 編碼器,而該架構有兩種變體版本:
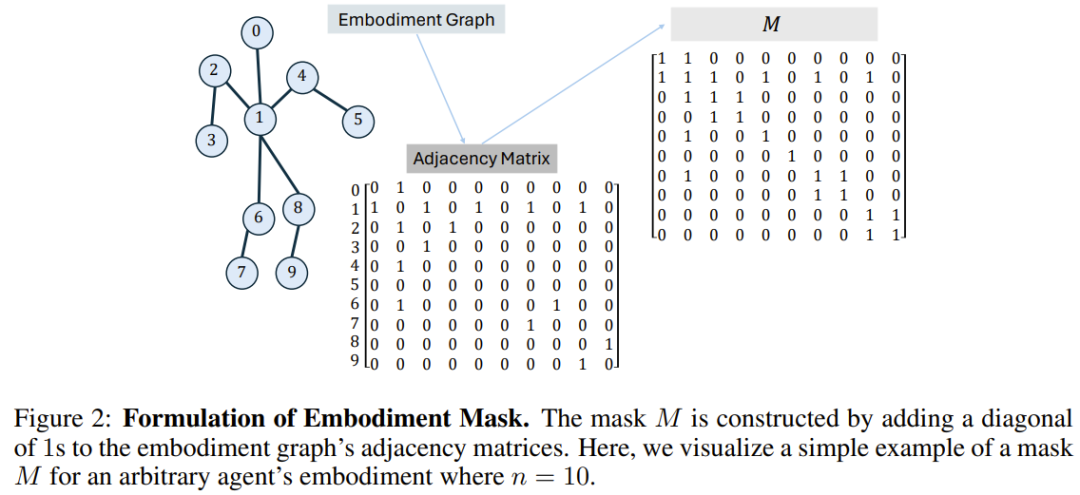
BoT-Hard:使用一個反映此圖結構的二元遮罩來遮蔽每一層。具體來說,他們建構掩碼的方式是 M = I_n + A,其中 I_n 是 n 維單位矩陣,A 是對應於該圖的鄰接矩陣。圖 2 展示了一個範例。這讓每個節點只能看到其自身和其直接近鄰,並且能為該問題引入相當可觀的稀疏性 —— 從計算成本角度看,這特別有吸引力。
BoT-Mix:將帶有掩碼式註意力的層(如BoT-Hard 一樣)與帶有無掩碼式註意力的層交織在一起。
detokenizer
Transformer 編碼器輸出的特徵會被饋送給線性層,然後被投射成與該節點的肢體關聯的動作;這些動作是根據對應執行器與肢體的接近程度來分配的。同樣,每個節點的這些可學習的線性投射層是分開的。如果將 BoT 用作強化學習設定中的批評架構,則 detokenizer 輸出的就不再是動作,而是價值,然後在機體部位上取平均值。
實驗
團隊在模仿學習和強化學習設定中評估了 BoT 的表現。他們維持了與圖 1 相同的結構,只用各種基線架構取代 BoT 編碼器,以確定編碼器的效果。
這些實驗的目標是解答以下問題:
遮罩式註意力是否能提升模仿學習的表現和泛化能力?
相較於原始的 Transformer 架構,BoT 是否能表現出正面的規模擴展趨勢?
BoT 是否與強化學習框架相容,有哪些合理設計選擇可以盡可能地提升表現?
BoT 策略是否可以應用在真實世界機器人任務?
遮罩式註意力在運算上有哪些優點?
模仿學習實驗
團隊在機體追蹤任務上評估了BoT 架構的模仿學習效能,該任務是透過MoCapAct 資料集定義的。
結果如圖 3a 所示,可以看到 BoT 的表現總是優於 MLP 和 Transformer 基準。值得注意的是,在未曾見過的驗證影片片段上,BoT 相對於這些架構的優勢還會進一步增大,這證明機體感知型歸納偏壓能帶來泛化能力的提升。
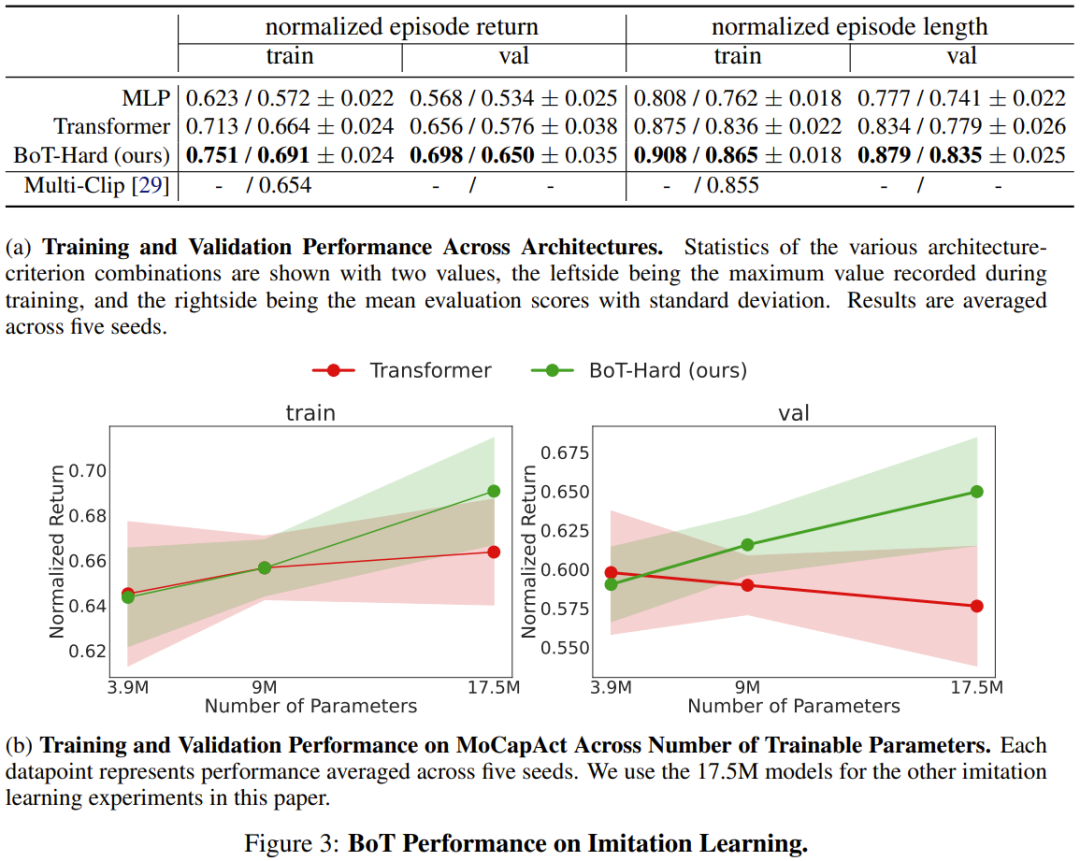
而圖3b 則顯示BoT-Hard 的規模擴展性很不錯,相較於Transformer 基線,其在訓練和驗證視頻片段上的性能都會隨著可訓練參數量的增長而增長這進一步表明BoT-Hard 傾向於不過擬合訓練數據,而這種過擬合是由具身偏移引起的。下面展示了更多實驗範例,詳見原論文。


強化學習實驗
團隊在Isaac Gym 中的4 個機器人控制任務上評估了BoT 與使用PPO 的基線的強化學習表現。這 4 個任務分別是:Humanoid-Mod、Humanoid-Board、Humanoid-Hill 和 A1-Walk。
圖 5 展示了 MLP、Transformer 和 BoT(Hard 和 Mix)在訓練期間的評估 rollout 的平均情節回報。其中,實線對應於平均值,陰影區域對應於五個種子的標準誤差。
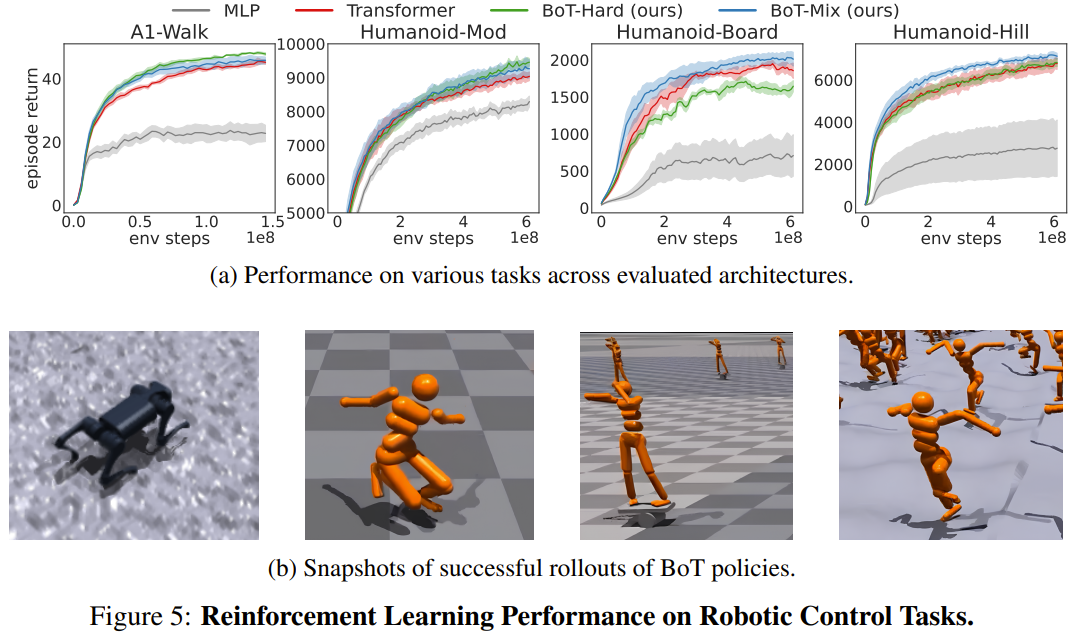

結果表明,BoT-Mix 的性能在樣本效率和漸近性能方面始終優於 MLP 和原始 Transformer 基線。這說明將來自機器人機體的偏壓整合進策略網路架構是有用的。
同時,BoT-Hard 在較簡單的任務(A1-Walk 和Humanoid-Mod)上的表現優於原始Transformer,但在更困難的探索任務(Humanoid-Board 和Humanoid-Hill)上表現卻更差。考慮到遮罩式註意力會妨礙來自遠處身體部分的資訊傳播,BoT-Hard 在資訊通訊方面的強大限制可能會妨礙強化學習探索的效率。
真實世界實驗
Isaac Gym 模擬的運動環境常被用於將強化學習策略從虛擬遷移到真實環境,並且還不需要在真實世界中進行調整。為了驗證新提出的架構是否適用於真實世界應用,該團隊將上述訓練所獲得的一個 BoT 策略部署到了一台 Unitree A1 機器人中。從如下影片可以看出,新架構可以可靠地用於真實世界部署。

運算分析
團隊也分析了新架構的運算成本,如圖 6 所示。這裡給出了新提出的遮罩式註意力與常規注意力在不同序列長度(節點數)上的規模擴展結果。
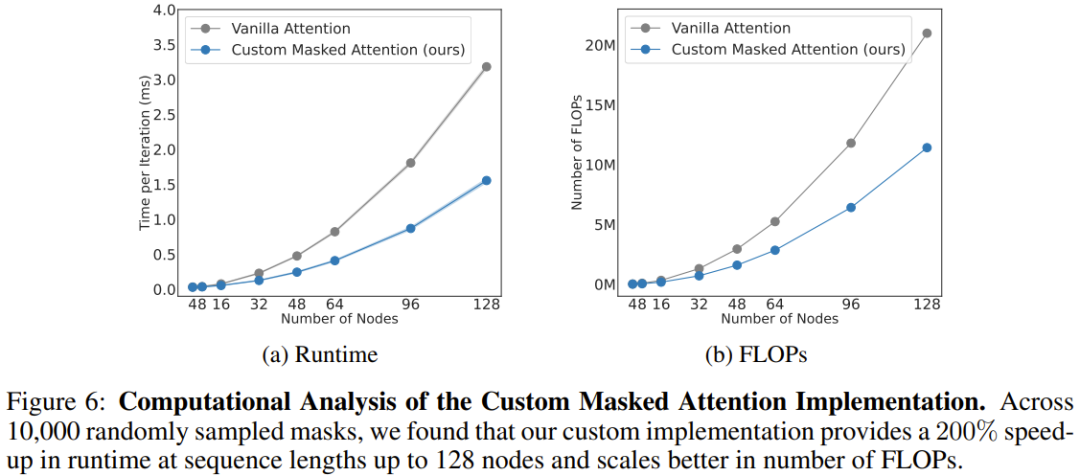
可以看到,當有 128 個節點時(相當於擁有靈巧雙臂的類人機器人),新註意力能將速度提升 206%。
整體而言,這表明 BoT 架構中的源自機體的偏置不僅能提高物理智能體的整體性能,而且還可受益於架構那自然稀疏的掩碼。此方法可透過充分的並行化來大幅減少學習演算法的訓練時間。
以上是機器人策略學習的Game Changer?柏克萊提出Body Transformer的詳細內容。更多資訊請關注PHP中文網其他相關文章!