
了解您的數據:探索性數據分析的要點

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-08-10 07:03:02653瀏覽
探索性資料分析是一種流行的分析資料集並直觀地呈現您的發現的方法。它有助於最大限度地洞察數據集和結構。這將探索性資料分析視為一種理解資料各個面向的技術。
為了更好地理解數據,必須確保數據乾淨,沒有冗餘,沒有缺失值,甚至沒有 NULL 值。
探索性資料分析的類型
主要分為三種:
單變數:這是您在任何單一時間查看一個變數(列)的地方。它有助於人們更多地了解變數的性質,被稱為最簡單的 EDA 類型。
雙變數:這是一起查看兩個變數的地方。它有助於人們理解變數 A 和 B 之間的關係,無論它們是獨立的還是相關的。
多變數:這涉及一次查看三個或更多變數。它被識別為“高級”二元變數。
方法
圖形:這涉及透過圖形和圖表等視覺表示來探索數據。常見的視覺化包括箱線圖、長條圖、散點圖和熱圖。
非圖形:這是透過統計技術完成的。使用的指標包括平均值、中位數、眾數、標準差和百分位數。
探索性資料分析工具
一些最常用的 EDA 工具包括
Python:一種物件導向的程式語言,用於連接現有元件並識別缺失值
R:一種用於統計計算的開源程式語言
步驟
- 了解資料 - 查看您正在使用的資料類型;列數、行數和資料類型。
- 清理資料 – 這涉及處理缺失值、缺失行和 NULL 值等不規則行為。
- 分析 – 分析變數之間的關係。
使用 Python 的 EDA 範例
本範例使用的資料集是 Iris 資料集 - 此處提供
- 使用 pandas 函式庫載入資料。
df = pd.read_csv(io.BytesIO(uploaded['Iris.csv'])) df.head()

- 辨識資料類型 df.info()
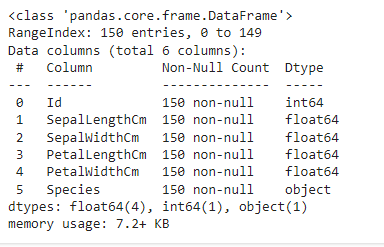
- 乾淨的數據,例如檢查 NULL 值 df.isnull().sum()

- 資料的非圖形分析以提供變數信息 df.describe()

- 圖形分析顯示變數相關性或獨立性
df.plot(kind='scatter', x='SepalLengthCm', y='SepalWidthCm') ; plt.show()

以上是了解您的數據:探索性數據分析的要點的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn
上一篇:PyTorch 頻譜下一篇:PyTorch 頻譜