伴隨大模型迭代速度越來越快,訓練集群規模越來越大,高頻率的軟硬體故障已成為阻礙訓練效率進一步提高的痛點,檢查點(Checkpoint)系統在訓練過程中負責狀態的儲存和恢復,已成為克服訓練故障、保障訓練進度和提高訓練效率的關鍵。
近日,位元組跳動豆包大模型團隊與香港大學聯合提出了 ByteCheckpoint。這是一個 PyTorch 原生,相容於多個訓練框架,支援 Checkpoint 的高效讀寫和自動重新切分的大模型 Checkpointing 系統,相比現有方法有顯著效能提升和易用性優勢。本文介紹了大模型訓練提效中 Checkpoint 方向面臨的挑戰,總結 ByteCheckpoint 的解決思路、系統設計、I/O 效能最佳化技術,以及在儲存效能和讀取效能測試的實驗結果。
Meta 官方最近披露了在16384 塊H100 80GB 訓練集群上進行Llama3 405B 訓練的故障率—— 短短54 天,發生419 次中斷,平均每三小時崩潰一次,引來不少從業者。
正如業界一句常言,大型訓練系統唯一確定的,便是軟硬體故障。隨著訓練規模與模型大小的日益增長,克服軟硬體故障,提高訓練效率成為大模型迭代的重要影響要素。
Checkpoint 已成為訓練提效關鍵。在 Llama 訓練報告中,技術團隊提到,為了對抗高故障率,需要在訓練過程中頻繁地進行 Checkpoint ,保存訓練中的模型、優化器、資料讀取器狀態,減少訓練進度損失。
字節跳動豆包大模型團隊與港大近期公開了成果 —— ByteCheckpoint ,一個 PyTorch 原生,兼容多個訓練框架,支援 Checkpoint 的高效讀寫和自動重新切分的大模型 Checkpointing 系統。
與基準方法相比,ByteCheckpoint 在 Checkpoint 保存上效能提升高達 529.22 倍,在載入上,效能提升高達 3.51 倍。 極簡的使用者介面和 Checkpoint 自動重新切分功能,顯著降低了使用者上手和使用成本,提高了系統的易用性。

- ByteCheckpoint: A Unified Checkpointing System for LLM Development
- 論文連結:https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-foropmentm-de =research
Checkpoint 技術在大模型訓練中的技術挑戰 當前Checkpoint 相關技術在支持大方模型方面面臨四個挑戰現有系統設計有缺陷,顯著增加訓練額外I/O 開銷
在訓練工業級的大語言模型(LLM) 的過程中,訓練點( Checkpointing ) 進行保存和持久化。通常情況下,一個 Checkpoint 包含 5 個部分 (模型,優化器,資料讀取器,隨機數和使用者自訂配置)。這個過程往往會為訓練帶來分鐘等級的阻塞,嚴重影響訓練效率。
在使用遠端持久化儲存系統的大規模訓練場景下,現有的Checkpointing 系統沒有充分利用Checkpoint 保存過程中GPU 到CPU 記憶體拷貝( D2H 複製),序列化,本地記憶體,上傳到儲存系統各階段的執行獨立性。
此外,不同訓練流程共同分擔 Checkpoint 存取任務的平行處理潛力也沒有被充分發掘。這些系統設計上的不足增加了 Checkpoint 訓練帶來的額外 I/O 開銷。
Checkpoint 重新切分困難,手動切分腳本開發維護開銷過高
) 以及在不同階段以及從不同階段訓練任務拉取不同階段的Checkpoint 進行執行自動評估) 之間進行Checkpoint 遷移時,通常需要對保存在持久化儲存系統中的Checkpoint 進行重新切分( Checkpoint Resharding ) ,以適應下游任務的新並行度配置以及可用GPU 資源的配額。
現有 Checkpointing 系統 [1, 2, 3, 4] 都假設儲存和載入時,並行度配置和 GPU 資源保持不變,無法處理 Checkpoint 重新切分的需求。工業界目前常見的解決方案是 —— 為不同模型自訂 Checkpoint 合併或重新切分腳本。這種方法帶來了大量開發與維護開銷,可擴展性較差。
不同的訓練框架Checkpoint 模組割裂,為Checkpoint 統一管理與效能最佳化帶來挑戰
,選擇合適框架(Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) 進行訓練,並將Checkpoint 保存到儲存系統。然而,這些不同的訓練框架都具有自己獨立的 Checkpoint 格式以及讀寫模組。不同訓練框架的 Checkpoint 模組設計不盡相同,為底層系統進行統一的 Checkpoint 管理以及效能最佳化帶來了挑戰。
1)如何有效率地儲存Checkpoint ,在不影響訓練效率的情況下保存Checkpoint。
2)如何重新切分 Checkpoint ,對於在一個平行度下儲存的 Checkpoint ,根據新的並行度正確讀入。 3)如何把訓練得到的產物上傳到雲端儲存系統( HDFS,S3 等),手動管理多個儲存系統,對使用者來說學習和使用成本較高。
🎜🎜針對上述問題,位元組跳動豆包大模型團隊和香港大學吳川教授實驗室聯合推出了 ByteCheckpoint 。 🎜🎜🎜🎜🎜🎜ByteCheckpoint 是一個多訓練框架統一,支援多重儲存後端,具備自動 Checkpoint 重新切分能力的高效能分散式 Checkpointing 系統。 ByteCheckpoint 提供了簡單易用的使用者介面 ,實現了大量 I/O 效能最佳化技術提高了儲存和讀取 Checkpoint 效能,並支援 Checkpoint 在不同並行度配置的任務中的靈活遷移。 🎜🎜🎜🎜🎜🎜系統設計🎜🎜🎜🎜🎜🎜🎜存儲架構🎜🎜🎜🎜🎜的框架。不同訓練框架中的模型以及優化器的張量切片 ( Tensor Shard) 儲存在 storage 檔案中,元資訊 (TensorMeta, ShardMeta, ByteMeta) 儲存到全域唯一的 metadata 檔案中。 
當使用不同的平行度配置讀取Checkpoint 時,如下圖所示,每個訓練進程只需要根據當前的並行度設置查詢元信息,便能夠獲取進程所需張量的存儲位置,再根據位置直接讀取,實作自動Checkpoint 重新切分。 
ten
不同訓練框架在運行時,往往會把模型或優化器中張量的形狀攤平( Flat ) 成一維,從而提高集合通信性能。這種攤平操作為 Checkpoint 儲存帶來了不規則張量切分 (Irregular Tensor Sharding) 的挑戰。 如下圖所示,在Megatron-LM (由NVIDIA 研發的分佈式大模型訓練框架) 和veScale (由位元組跳動研發的PyTorch 原生分佈式大模型訓練框架) 中,模型參數的對應優化器狀態會被展平為一維後合併,再根據資料並行度切分。這導致張量被不規則地切分到不同進程之中,張量切片的元資訊無法使用偏移量和長度元組來表示,給儲存和讀取帶來困難。 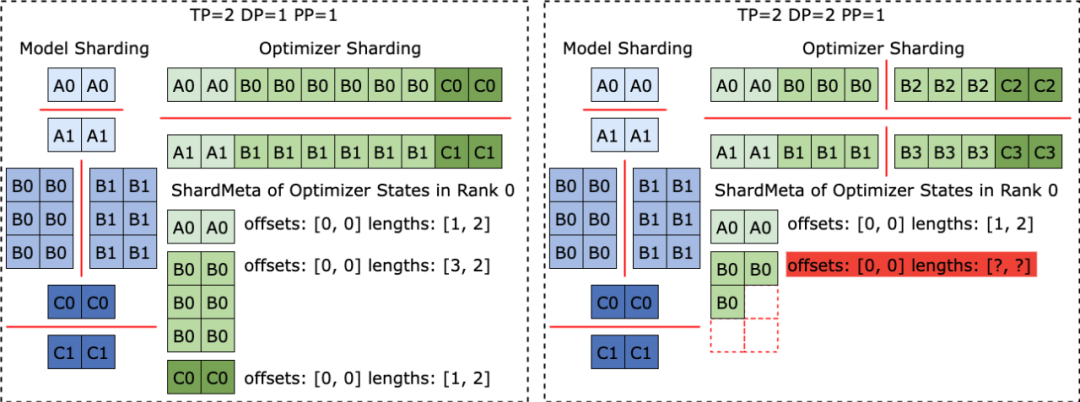
不規則張量切分的問題在 FSDP 框架中也同樣存在。 為消除不規則切分的張量切片,FSDP 框架在儲存Checkpoint 之前會在所有進程上對一維張量切片進行all-gather 集合通訊以及D2H 複製操作,以取得完整不規則切分的張量。這種方案帶來了極大的通訊和頻繁的 GPU-CPU 同步開銷,嚴重影響了 Checkpoint 儲存的效能。 針對這個問題,ByteCheckpoint 提出了非同步張量合併 (Asynchronous Tensor Merging) 技術。 ByteCheckpoint 首先找出不同進程中被不規則切分的張量,之後採用異步的 P2P 通信,把這些不規則的張量分配到不同進程上進行合併。所有針對這些不規則張量的P2P 通訊等待(Wait) 以及張量D2H 複製作業被推遲到他們即將進入序列化階段的時候,從而消除了頻繁的同步開銷,也增加了通訊與其他Checkpoint 儲存流程的執行重疊度。 下圖展示了ByteCheckpoint 的系統架構:
Planner 層會根據存取物件為不同訓練流程產生存取方案,交由 Execution 層執行實際的 I/O 任務。
Execution 層執行 I/O 任務並與 Storage 層進行交互,利用各種 I/O 優化技術進行高效能的 Checkpoint 存取。
Storage 層管理不同的儲存後端,並在 I/O 任務過程中根據不同儲存後端進行相應的最佳化。
分層設計增強了系統的可擴展性,以便未來支援更多的訓練框架和儲存後端。 
API 用例
ByteCheckpoint 的 API 使用例如下:ByteCheckpoint provides a minimalist API, reducing the user’s cost of getting started. When storing and reading Checkpoints, users only need to call the storage and loading functions, passing in the content to be stored and read, the file system path and various performance optimization options. I/O performance optimization technologyCheckpoint storage optimizationAs shown in the figure below, ByteCheckpoint Designed a fully asynchronous storage pipeline (Save Pipeline), splits the different stages of Checkpoint storage (P2P tensor transfer, D2H replication, serialization, saving local and uploading file systems) to achieve efficient pipeline execution.

Avoid repeated memory allocationIn the D2H copy process, ByteCheckpoint uses a pinned memory pool (Pinned Memory Pool), which reduces the time overhead of repeated memory allocation. In addition, in order to reduce the additional time overhead caused by synchronously waiting for fixed memory pool recycling in high-frequency storage scenarios, ByteCheckpoint adds a Ping-Pong buffering mechanism based on the fixed memory pool. Two independent memory pools alternately play the role of read and write buffers, interacting with the GPU and I/O workers that perform subsequent I/O operations, further improving storage efficiency. 
In data-parallel (Data-Parallel or DP) training, the model is redundant between different data-parallel process groups (DP Group). ByteCheckpoint adopts a load balancing algorithm Evenly distribute redundant model tensors to different process groups for storage, effectively improving Checkpoint storage efficiency. Checkpoint read optimizationAs shown in the figure, when changing the parallelism to read Checkpoint, the new training process may only need to start from the original Read part of it from a tensor slice. ByteCheckpoint uses on-demand partial file reading (Partial File Reading) technology to directly read the required file fragments from remote storage to avoid downloading and reading unnecessary data. 
In data-parallel (Data-Parallel or DP) training, the model is redundant between different data parallel process groups (DP Group), and different process groups will repeatedly read the same tensor slice. In large-scale training scenarios, different process groups send a large number of requests to remote persistent storage systems (such as HDFS) at the same time, which will put huge pressure on the storage system. In order to eliminate repeated data reading, reduce the requests sent to HDFS by the training process, and optimize loading performance, ByteCheckpoint evenly distributes the same tensor slice reading tasks to different processes, and reads the remote files. While fetching, the idle bandwidth between GPUs is used for tensor slice transmission. 
Experimental configurationThe team uses DenseGPT and SparseGPT models (implemented based on GPT-3 [10] structure), with different model parameter amounts and different training frameworks The Checkpoint access correctness, storage performance and read performance of ByteCheckpoint were evaluated in training tasks of different sizes. For more details on experimental configuration and correctness testing, please refer to the complete paper. 
In the storage performance test, the team compared different model sizes and training frameworks. During the training process, Checkpoint, Bytecheckpoint and Baseline methods were saved every 50 or 100 steps. The total blocking time (Checkpoint stalls) caused by training. Thanks to the in-depth optimization of writing performance, ByteCheckpoint has achieved high performance in various experimental scenarios. In the 576-card SparseGPT 110B - Megatron-LM training task, ByteCheckpoint has achieved 10% higher performance than the baseline storage method. The performance improvement is 66.65~74.55 times, and it can even reach a performance improvement of 529.22 times in the 256-card DenseGPT 10B-FSDP training task. 
In the read performance test, the team compared the loading time of different methods to read checkpoints based on the parallelism of downstream tasks. ByteCheckpoint achieves a performance improvement of 1.55 to 3.37 times compared to the baseline method. The team observed that the performance improvement of ByteCheckpoint is more significant compared to the Megatron-LM baseline method. This is because Megatron-LM needs to run an offline script to re-shard the distributed checkpoint before reading the checkpoint to the new parallelism configuration. In contrast, ByteCheckpoint can directly perform automatic checkpoint re-segmentation without running offline scripts and complete reading efficiently. 
Finally, regarding the future planning of ByteCheckpoint, the team hopes to start from two aspects: First, achieve the long-term goal of supporting efficient checkpointing for ultra-large-scale GPU cluster training tasks. Second, realize checkpoint management of the entire life cycle of large model training, supporting checkpoints in all scenarios, from pre-training (Pre-Training), to supervised fine-tuning (SFT), to reinforcement learning (RLHF) and evaluation (Evaluation) and other scenarios. ByteDance Beanbao Big Model Team was established in 2023 and is committed to developing the most advanced AI big model technology in the industry and becoming a world-class research team for the development of technology and society. Make a contribution. Currently, the team is continuing to attract outstanding talents to join. Hard-core, open and full of innovative spirit are the key words of the team atmosphere. The team is committed to creating a positive working environment, encouraging team members to continue to learn and grow, and not to be afraid of challenges. Challenge and pursue excellence. Hope to work with technical talents with innovative spirit and sense of responsibility to promote the efficiency improvement of large model training and achieve more progress and results. [1] Mohan, Jayashree, Amar Phanishayee, and Vijay Chidambaram. "{CheckFreq}: Frequent,{Fine-Grained}{DNN} Checkpointing." 19th USENIX Conference on File and Storage Technologies (FAST 21). 2021.[2] Eisenman, Assaf, et al. "{Check-N-Run}: A Checkpointing system for training deep learning recommendation models." 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). 2022.[3] Wang, Zhuang, et al. "Gemini: Fast failure recovery in distributed training with in-memory Checkpoints." Proceedings of the 29th Symposium on Operating Systems Principles. 2023.[4] Gupta, Tanmaey, et al. "Just-In-Time Checkpointing: Low Cost Error Recovery from Deep Learning Training Failures." Proceedings of the Nineteenth European Conference on Computer Systems. 2024.[5] Shoeybi, Mohammad, et al. "Megatron-lm: Training multi-billion parameter language models using model parallelism." arXiv preprint arXiv:1909.08053 (2019). [6] Zhao, Yanli, et al. "Pytorch fsdp: experiences on scaling fully sharded data parallel." arXiv preprint arXiv:2304.11277 (2023).[7] Rasley, Jeff, et al. "Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.[8] Jiang, Ziheng, et al. "{MegaScale}: Scaling large language model training to more than 10,000 {GPUs}." 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024.[9] veScale: A PyTorch Native LLM Training Framework https://github.com/volcengine/veScale[10] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020) ): 1877-1901.以上是Llama3訓練每3小時崩崩一次?豆包大模型、港大團隊為脆皮萬卡訓練提效的詳細內容。更多資訊請關注PHP中文網其他相關文章!

