AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文第一作者是史丹佛大學研究生蔡驒他以績點第一名的成績在東南大學取得學士學位。他的研究興趣為多模態大模型、具身智能。此工作為其在上海交通大學訪問和北京智源人工智慧研究院實習期間完成,導師為本文通訊作者趙波教授。 先前,李飛飛老師提出了空間智能(Spatial Intelligence) 這個概念,作為回應,來自上交、史丹佛、智源、北大、牛津、東大的研究者提出了空間大模型SpatialBot,並提出了訓練資料SpatialQA 和測試清單SpatialBench, 嘗試讓多模態大模型在通用場景和具身場景下理解深度、理解空間。 
- 論文標題: SpatialBot: Precise Depth Understanding with Vision Language Models
- 論文連結//arxiv.org/abs/2406.13642
- 專案首頁: https://github.com/BAAI-DCAI/SpatialBot
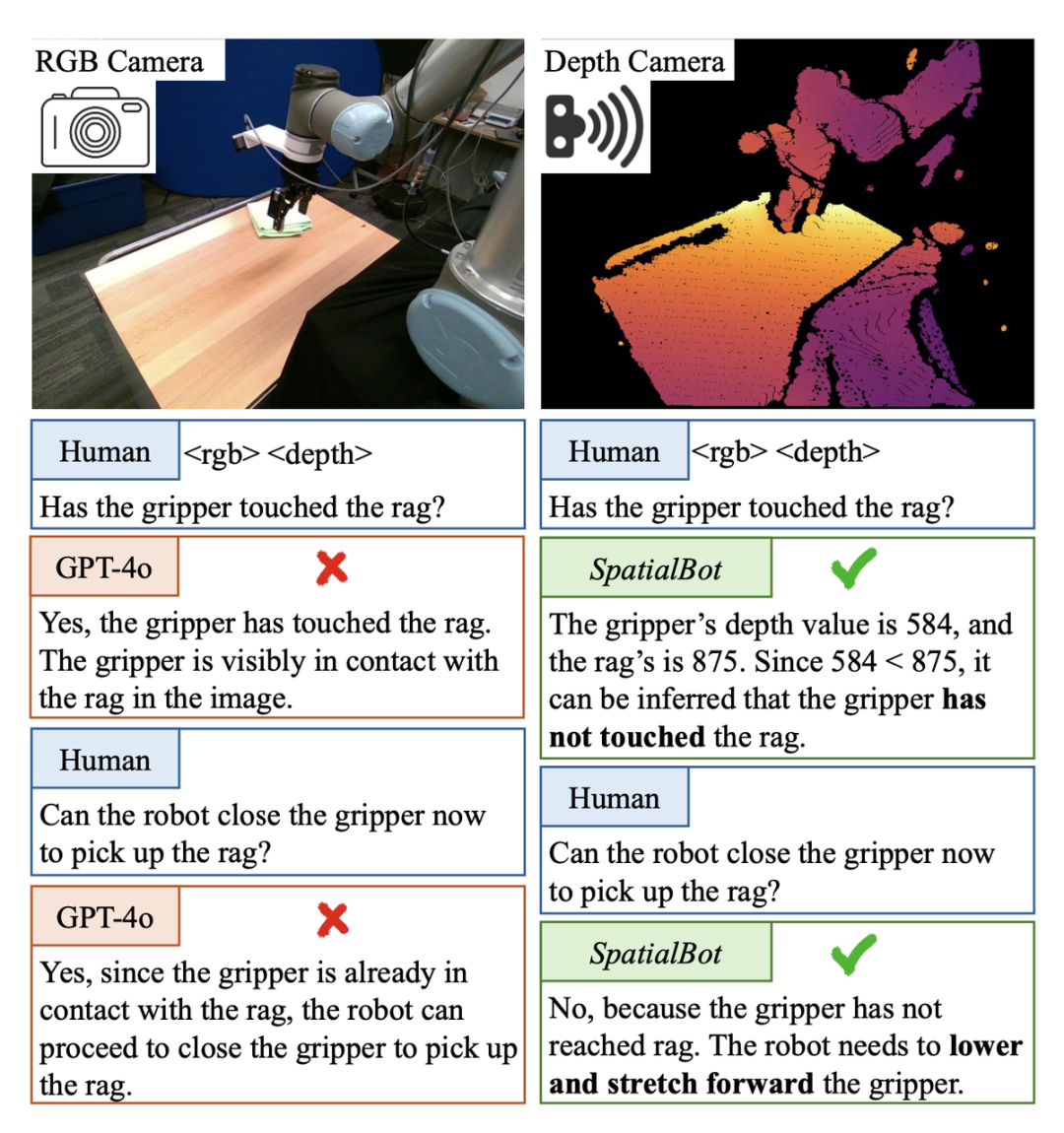
在具身智能的pick and place 任務中,需要判斷機械爪是否碰到了目標物體。如果碰到,則可以合上爪子抓取。然而,在這個Berkerly UR5 Demonstration Dataset 場景中,即使是GPT-4o 或人類,都無法從單張RGB 影像中判斷機械爪是否碰到了目標物體,例如借助深度訊息,將深度圖直接給GPT-4o 看的話,也無法判斷,因為它無法理解深度圖。
SpatialBot 透過對 RGB-Depth 的理解,可以準確獲得機械爪和目標物體的深度值,從而產生對空間概念的理解。
1.的視角,抓取右邊的茶杯
作為走向具身智能的必要路徑,如何讓大模型理解空間? 點雲比較貴,雙眼相機在使用上需要經常校準。相比之下,深度相機價格可以接受、使用範圍廣。在通用場景中,即使沒有這樣的硬體設備,大規模無監督訓練過的深度估計模型已經可以提供較為準確的深度資訊。因此,作者提出,使用 RGBD 作為空間大模型的輸入。
- 現有模型無法直接理解深度圖輸入。例如,影像編碼器 CLIP/SigLIP 在 RGB 影像上訓練,沒有看過深度圖。
- 現有大模型資料集,且多僅用 RGB 就可以分析、回答。因此,如果僅僅簡單的將現有資料改為 RGBD 輸入,模型不會主動到深度圖中索引知識。需要專門設計任務和 QA,引導模型理解深度圖、使用深度資訊。
三個層級中的SpatialQA,逐步引導模型來理解深度圖、使用深度為資訊圖如何引導模型理解和使用深度訊息,理解空間? 作者提出具有三個層次的 SpatialQA 資料集。 在low level 引導模型理解深度圖,引導從深度圖直接取得資訊;
- 在middle level 讓模型將depth 與RGB 對齊;
- 在high level 設計多個深度相關任務,標註了50k 的數據,讓模型在理解深度圖的基礎上,使用深度資訊完成任務。任務包括:空間位置關係,物體大小,物體接觸與否,機器人場景理解等。
>
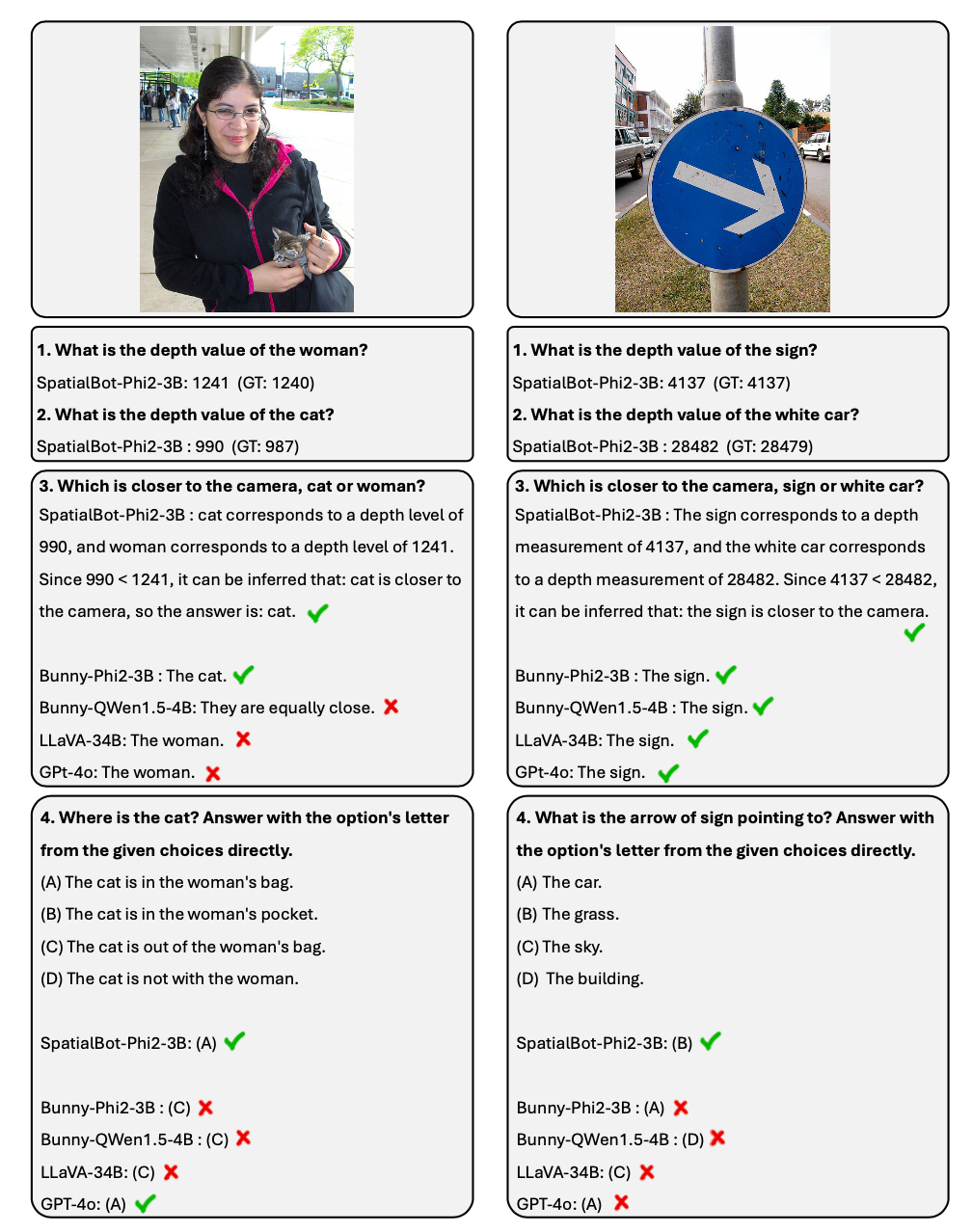
1. 借鑒 agent 中的思想,SpatialBot 在需要時,可以透過 API 取得準確的深度資訊。在深度資訊擷取、遠近關係比較的任務上,可以達到 99%+ 的準確率。 2. 針對空間理解任務,作者公佈了 SpatialBench 名單。透過精心設計和標註 QA,測試模型深度理解能力。 SpatialBot 在名單上展示了和 GPT-4o 接近的能力。
1. 輸入模型的深度圖:為了兼顧室內室外任務,需要統一的深度圖編碼方式。室內的抓取、導航任務可能需要毫米的精確度,室外的場景不需要這麼精準,卻可能需要 100 公尺以上的深度值範圍。傳統視覺任務中會用 Ordinal Encoding 來編碼,但 ordinal 的值無法進行加減運算。為了盡可能保留所有深度訊息,SpatialBot 直接使用以毫米為單位的 metric depth,範圍為 1mm~131m,使用 uint24 或三通道的 uint8 來保留這些值。 2. 為了精準的獲取深度信息,借鑒 agents 中的思想,SpatialBot 在認為有必要的時候,會以點的形式調用 DepthAPI,獲取準確的深度值。若想取得物體的深度,SpatialBot 會先思考物體的 bounding box 是什麼,然後再用 bounding box 的中心點呼叫 API。
3. SpatialBot 使用物體的中心點、深度平均、最大和最小四個值來描述深度。 >
SpatialBot在通用場景和具身場景效果如何? 1. SpatialBot 以 3B 到 8B 的多個 base LLM 為基礎。透過在 SpatialQA 中學習空間知識,SpatialBot 在常用 MLLM 資料集 (MME、MMBench 等) 上同樣展示了顯著的效果提升。
2. 在 Open X-Embodiment、作者收集的機器人抓取資料等具身任務上,SpatialBot 也展現了驚人效果。
精心設計了關於空間理解的問題,例如深度、遠近關係、上下左右前後位置關係、大小關係,並且包含了具身中的重要問題,例如兩個物體是否接觸。
在測驗集 SpatialBench 中,首先人工思考問題、選項和答案。為了擴大測試集大小,也使用 GPT 以相同的流程標註。
直接理解深度圖,讓模型看深度圖,分析深度的分佈,猜測其中可能包含的物體;
- 機器人場景理解:描述Open X-Embodiment 和本文收集的機器人資料中的場景、包含的物體、可能的任務,並人工標註物體、機器人的bounding box。
-
🎜>
Open X-Embodiment 中🎜>深度圖理解。在使用 GPT 標註這部分資料時,GPT 會先看到深度圖,描述深度圖、推理其中可能包含的場景和物體,然後看到 RGB 圖,篩選出正確的描述和推理。 以上是李飛飛「空間智能」之後,上交、智源、北大等提出空間大模型SpatialBot的詳細內容。更多資訊請關注PHP中文網其他相關文章!




 2. 抓取最中間的茶杯
2. 抓取最中間的茶杯 

 >
>
