
可解釋性終極追問,什麼才是第一性解釋? 20篇CCF-A+ICLR論文給你答案

- 王林原創
- 2024-08-05 15:55:55965瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
請參考1:https://zhuanlan.zhihu.com/p/369883667 - 參見🎜>參見2:https://zhuanlan.zhihu.com/p/361686461
- 參考3:https://zhuanlan.zhihu.com/p/704760363
- 請參閱4:https://zhuanlan.zhihu.com/p/468569001
請參考1:https://zhuanlan.zhihu.com/p/610774894 - 參見2:https://zhuanlan.zhihu.com/p/546433296
- 1.Junpeng Zhang, Qing Li, Liang Lin, Quanshi Zhang,「Two-Phase Dynamics of Interactions Explains the Starting Point of a DNN Learning Over-Fitted Features”,in arXiv: 2405.10262
- 2.Qihan Ren, Yang Xu, Junpeng Zhang, Yue Xin, Dongrui Liu, Quanshi, Yang Xu, Junpeng Zhang, Yue Xin, Dongrui Liu, Quanshi Zhang Symbolic Interactions」 in arXiv:2407.19198


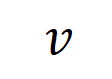
 和一個輸入樣本
和一個輸入樣本 ,它包含
,它包含 個輸入變量,我們用集合
個輸入變量,我們用集合 表示這些輸入變數的全集。令
表示這些輸入變數的全集。令 表示 DNN 在樣本
表示 DNN 在樣本 上的一個標量輸出。對於一個面向分類任務的神經網絡,我們可以從不同角度來定義其標量輸出。例如,對於多類別分類問題,
上的一個標量輸出。對於一個面向分類任務的神經網絡,我們可以從不同角度來定義其標量輸出。例如,對於多類別分類問題, 可以定義為
可以定義為 ,也可以定義為 softmax 層之前該樣本真實標籤所對應的標量輸出。這裡,
,也可以定義為 softmax 層之前該樣本真實標籤所對應的標量輸出。這裡, 表示真實標籤的分類機率。這樣,針對每個子集
表示真實標籤的分類機率。這樣,針對每個子集中所有輸入變數之間 “等效與交互” 和 “等效或交互”。 
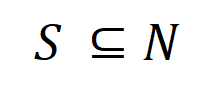 內輸入變數之間的 「與關係」。例如,給定一個輸入句子
內輸入變數之間的 「與關係」。例如,給定一個輸入句子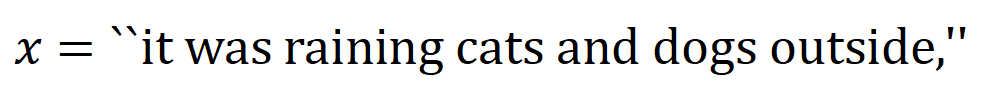 ,神經網路可能會在
,神經網路可能會在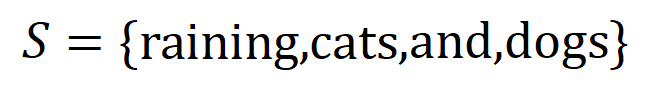 之間建模一個交互,使得
之間建模一個交互,使得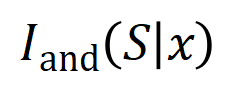 產生一個推動神經網路輸出 「傾盆大雨」 的數值效用。如果
產生一個推動神經網路輸出 「傾盆大雨」 的數值效用。如果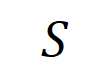 中的任何輸入變數被遮擋,則該數值效用將從神經網路的輸出中移除。類似地,等效或交互作用
中的任何輸入變數被遮擋,則該數值效用將從神經網路的輸出中移除。類似地,等效或交互作用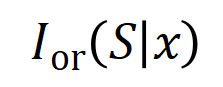 表示神經網路所建模的
表示神經網路所建模的 內輸入變數之間的 「或關係」。例如,給定一個輸入句子
內輸入變數之間的 「或關係」。例如,給定一個輸入句子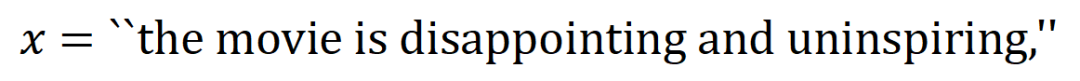 ,只要
,只要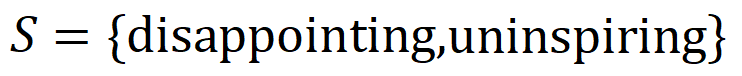 中的任一個字出現,就會推動神經網路的輸出負面情緒分類。
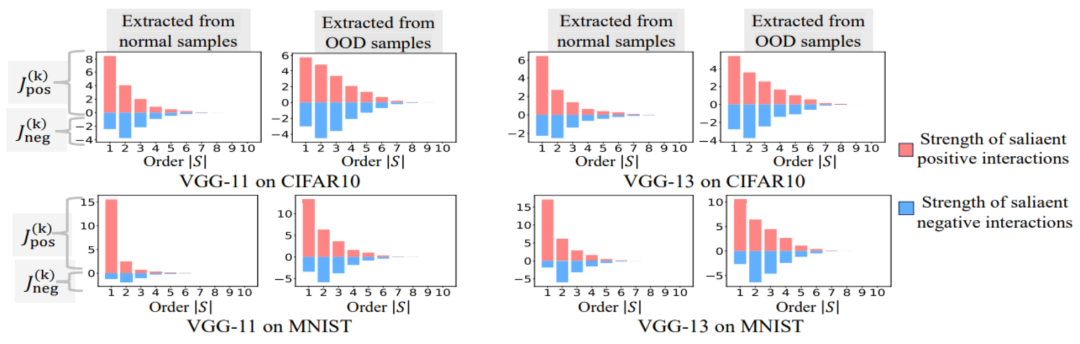
中的任一個字出現,就會推動神經網路的輸出負面情緒分類。 無限擬合性:如圖4,5 所示,對於任意遮蔽樣本,神經網路在樣本上的輸出可以用不同交互概念的效用總和來擬合。即,我們可以建構出一個基於交互作用的 logical model,無論我們如何遮擋輸入樣本,這個 logical model 依然可精確擬合模型在此輸入樣本在任意遮擋狀態下的輸出值。 稀疏性:分類任務導向的神經網路往往只建模少量的顯著交互作用概念,而大部分互動概念都是數值效用都接近0的噪音。 樣本間遷移性:交互在不同樣本間是可遷移的,即神經網路在(同一類別的)不同樣本上建模的顯著交互概念往往有很大的重合。
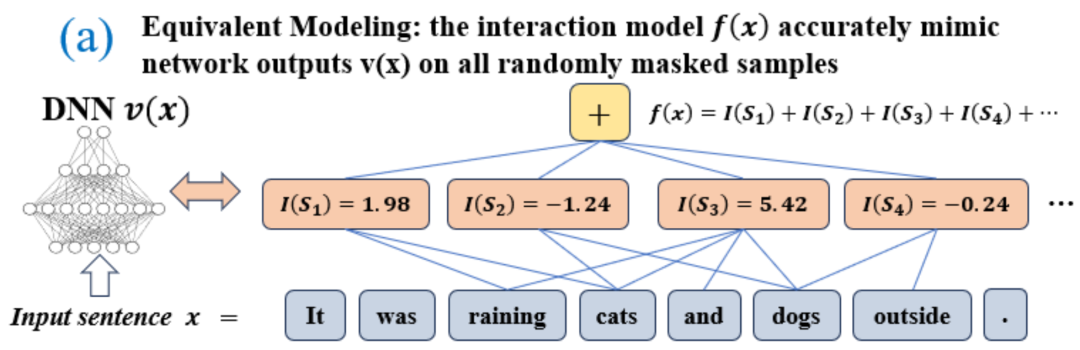
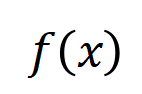 準確擬合。每個交互作用都是衡量神經網路建模特定輸入變數集合
準確擬合。每個交互作用都是衡量神經網路建模特定輸入變數集合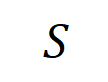 之間非線性關係的測量指標。當且僅當集合中變數同時出現時才會觸發與交互,並為輸出貢獻數值分數
之間非線性關係的測量指標。當且僅當集合中變數同時出現時才會觸發與交互,並為輸出貢獻數值分數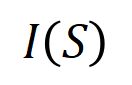 ,集合
,集合 中任意變數出現時會觸發或交互。
中任意變數出現時會觸發或交互。 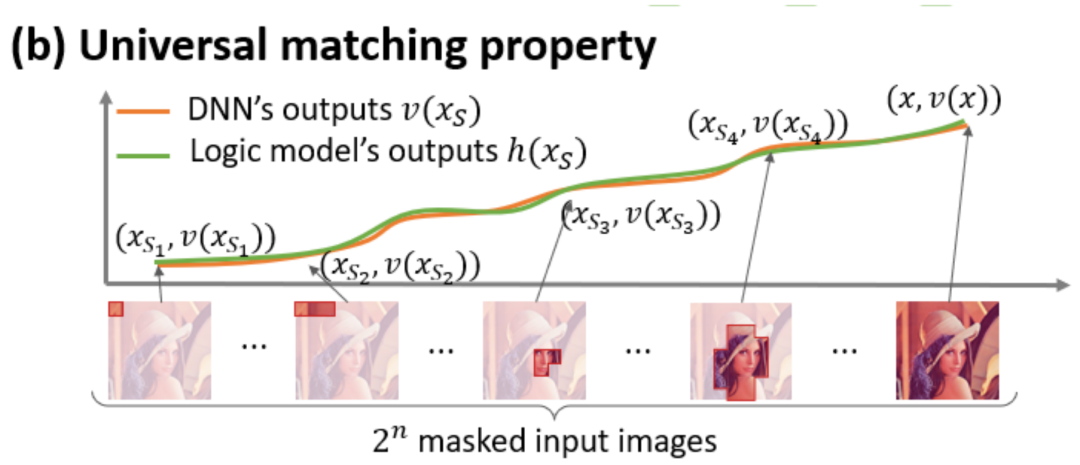
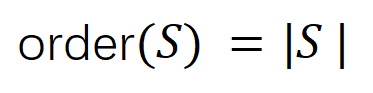
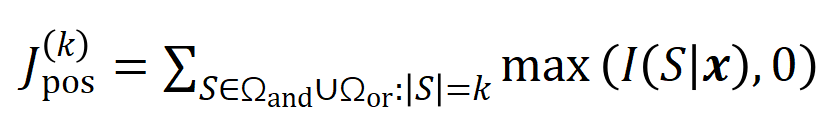
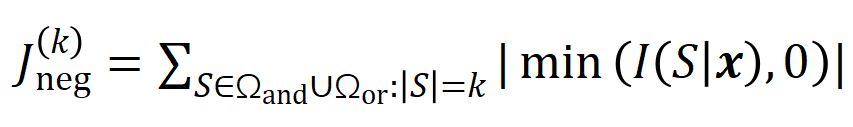
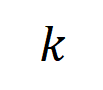
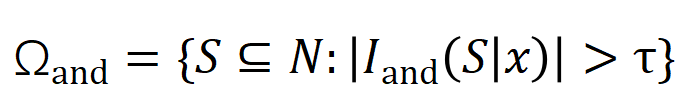
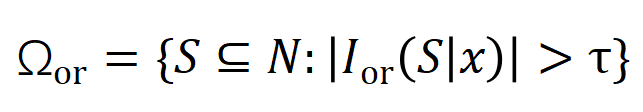 因此,本篇研究的第一步是去
因此,本篇研究的第一步是去 預測出神經網路在訓練過程中不同時間點所建模的不同階「與或交互」 的複雜度的一個解析解,即我們可以透過神經網路在不同時間點所建模的不同階「與或交互」 的分佈去解釋神經網路在不同階段的泛化能力
預測出神經網路在訓練過程中不同時間點所建模的不同階「與或交互」 的複雜度的一個解析解,即我們可以透過神經網路在不同時間點所建模的不同階「與或交互」 的分佈去解釋神經網路在不同階段的泛化能力
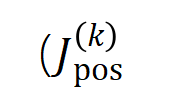 和
和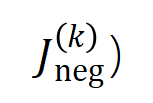 。在不同資料集上、不同任務上訓練的不同的神經網路的訓練過程都存在兩階段現象。前兩個選定時間點屬於第一階段,而後兩個時間點屬於第二階段。恰恰在進入神經網路訓練過程的第二階段不久,神經網路的測試損失和訓練損失之間的 loss gap 開始顯著上升(見最後一列)。這顯示神經網路訓練的兩階段現象與模型 loss gap 的變化在時間上是 “對齊” 的。更多實驗結果請參考論文。
。在不同資料集上、不同任務上訓練的不同的神經網路的訓練過程都存在兩階段現象。前兩個選定時間點屬於第一階段,而後兩個時間點屬於第二階段。恰恰在進入神經網路訓練過程的第二階段不久,神經網路的測試損失和訓練損失之間的 loss gap 開始顯著上升(見最後一列)。這顯示神經網路訓練的兩階段現象與模型 loss gap 的變化在時間上是 “對齊” 的。更多實驗結果請參考論文。 在神經訓練訓練之前,初始化的神經網路主要編碼中階交互,很少編碼高階和低階交互,並且不同階交互的分佈看起來呈現「紡錘形」。假設具有隨機初始化參數的神經網路建模的是純噪聲,我們在“5.4 理論證明兩階段現象” 章節證明了具有隨機初始化參數的神經網路建模的不同階的交互的分佈呈現“紡錘形”,即僅建模少量的低階和高階交互,大量建模中階交互。 在神經網路訓練的第一階段,神經網路編碼的高階和中階交互作用的強度逐漸減弱,而低階交互作用的強度逐漸增強。最終,高階和中階交互作用逐漸被消除,神經網路只編碼低階交互作用。 在神經網路訓練的第二階段,神經網路在訓練過程中編碼的交互階數(複雜度)逐漸增加。在逐漸學習更高複雜度的交互作用的過程中,神經網路過度擬合的風險也逐漸提高。
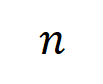 個輸入變數的輸入樣本
個輸入變數的輸入樣本 ,我們將從輸入樣本
,我們將從輸入樣本 提取到的
提取到的 階交互向量化
階交互向量化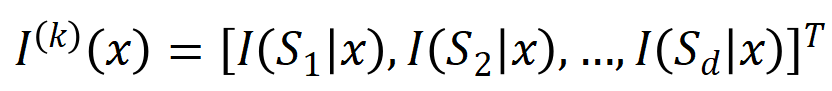 ,其中
,其中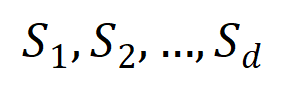 表示
表示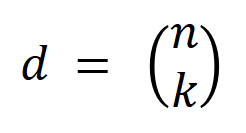 個
個 階交互。然後,我們計算分類任務中所有類別為
階交互。然後,我們計算分類任務中所有類別為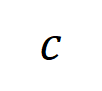 的樣本中提取到的階的平均交互作用向量,表示為
的樣本中提取到的階的平均交互作用向量,表示為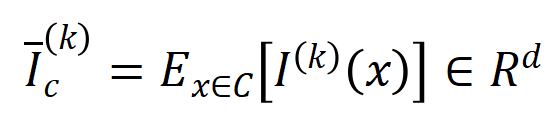 ,其中
,其中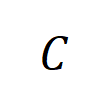 表示類別為
表示類別為 的樣本的集合。接下來,我們計算從訓練樣本中提取的階的平均交互向量
的樣本的集合。接下來,我們計算從訓練樣本中提取的階的平均交互向量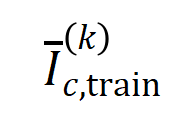 與從測試樣本中提取的階的平均交互向量
與從測試樣本中提取的階的平均交互向量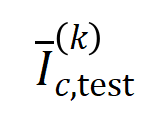 之間的Jaccard 相似性,以衡量分類任務中類別為的樣本的階交互的泛化能力,即:
之間的Jaccard 相似性,以衡量分類任務中類別為的樣本的階交互的泛化能力,即: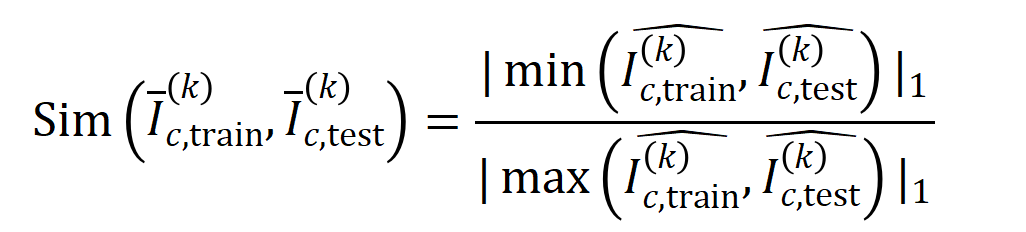
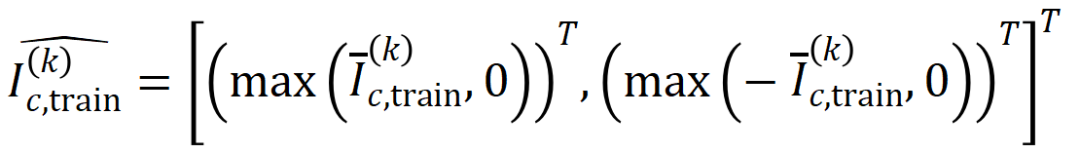 和
和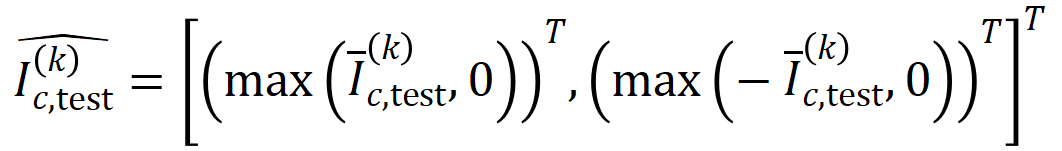 將兩個
將兩個 維交互向量投影到兩個
維交互向量投影到兩個 維的非負向量上,以便計算Jaccard 相似性。對於某一階的交互,如果此階交互普遍展現出較大的 Jaccard 相似性,則表示這一階交互具有較強的泛化能力。
維的非負向量上,以便計算Jaccard 相似性。對於某一階的交互,如果此階交互普遍展現出較大的 Jaccard 相似性,則表示這一階交互具有較強的泛化能力。 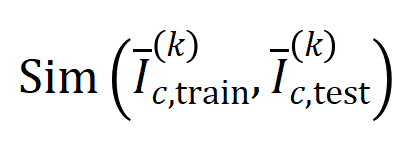 。我們測試了在 MNIST 資料集上訓練的 LeNet、在 CIFAR-10 資料集上訓練的 VGG-11、在 CUB200-2011 資料集上訓練的 VGG-13,以及在 Tiny-ImageNet 資料集上訓練的 AlexNet。為了減少計算成本,我們僅計算了前 10 個類別的 Jaccard 相似性的平均值
。我們測試了在 MNIST 資料集上訓練的 LeNet、在 CIFAR-10 資料集上訓練的 VGG-11、在 CUB200-2011 資料集上訓練的 VGG-13,以及在 Tiny-ImageNet 資料集上訓練的 AlexNet。為了減少計算成本,我們僅計算了前 10 個類別的 Jaccard 相似性的平均值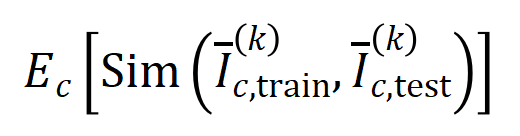 。如圖 7 所示,隨著交互階數的增加,交互作用的 Jaccard 相似性不斷下降。因此,這驗證了高階交互作用比低階交互作用具有更差的泛化能力。
。如圖 7 所示,隨著交互階數的增加,交互作用的 Jaccard 相似性不斷下降。因此,這驗證了高階交互作用比低階交互作用具有更差的泛化能力。  中使用低階交互具有相對較高 Jaccard 相似性表明低階交互具有較強的泛化能力。
中使用低階交互具有相對較高 Jaccard 相似性表明低階交互具有較強的泛化能力。
 ,變異數為
,變異數為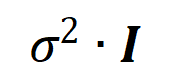 的常態分佈。在上述假設下,我們能夠證明初始化的神經網路建模的交互的強度和的分佈呈現 “紡錘形”,即很少建模高階和低階交互,主要建模中階交互。
的常態分佈。在上述假設下,我們能夠證明初始化的神經網路建模的交互的強度和的分佈呈現 “紡錘形”,即很少建模高階和低階交互,主要建模中階交互。 
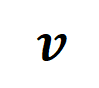 在特定樣本上的inference 改寫為不同交互作用觸發函數的加權和:
在特定樣本上的inference 改寫為不同交互作用觸發函數的加權和: 其中,
其中, 為標量權重,滿足
為標量權重,滿足 。而函數
。而函數 為交互觸發函數,在任一遮擋樣本
為交互觸發函數,在任一遮擋樣本 上都滿足
上都滿足 。函數
。函數 的具體形式可以由泰勒展開推導得到,可參考論文,這裡不做贅述。
的具體形式可以由泰勒展開推導得到,可參考論文,這裡不做贅述。
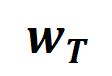 的學習。進一步地,實驗室的前期工作[3] 發現在同一任務上充分訓練的不同的神經網路往往會建模相似的交互,所以我們可以將神經網路的學習看成是對一系列潛在的ground truth 交互的擬合。由此,神經網路在訓練到收斂時建模的交互作用可以看成是最小化下面的目標函數時得到的解:
的學習。進一步地,實驗室的前期工作[3] 發現在同一任務上充分訓練的不同的神經網路往往會建模相似的交互,所以我們可以將神經網路的學習看成是對一系列潛在的ground truth 交互的擬合。由此,神經網路在訓練到收斂時建模的交互作用可以看成是最小化下面的目標函數時得到的解: 其中
其中 表示神經網路需要擬合的一系列潛在的ground truth 互動。
表示神經網路需要擬合的一系列潛在的ground truth 互動。  和
和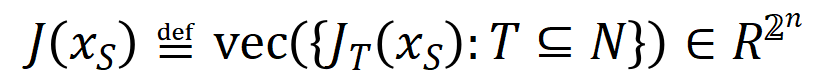 則分別表示將所有權重拼起來得到的向量和將所有交互觸發函數的值拼起來得到的向量。
則分別表示將所有權重拼起來得到的向量和將所有交互觸發函數的值拼起來得到的向量。
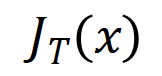 上的噪聲,且該噪聲隨著交互階數指數級增長 (在 [5] 中已有實驗上的觀察和驗證) 。我們將有雜訊下的神經網路的學習建模如下:
上的噪聲,且該噪聲隨著交互階數指數級增長 (在 [5] 中已有實驗上的觀察和驗證) 。我們將有雜訊下的神經網路的學習建模如下:
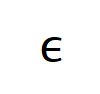 滿足
滿足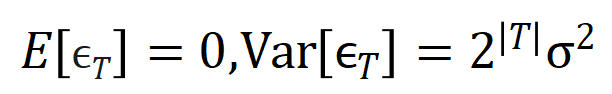 。且隨著訓練進行,噪音的變異數
。且隨著訓練進行,噪音的變異數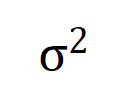 逐漸變小。
逐漸變小。  的情況下最小化上述損失函數,可得到最優交互權重
的情況下最小化上述損失函數,可得到最優交互權重 的解析解,如下圖的定理所示。
的解析解,如下圖的定理所示。 
變小),中低階交互強度和高階交互強度的比值逐漸減少(如下面的定理)。這解釋了訓練的第二階段中神經網路逐漸學到更高階的互動的現象。 
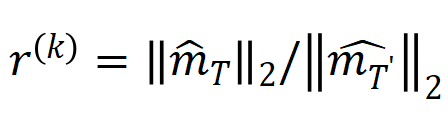 ,其中
,其中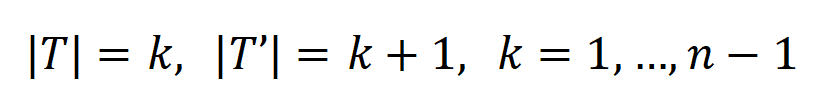 , 可以用來近似測量第 k 階交互作用和第 k+1 階交互強度的比值。在下圖中,我們可以發現,在不同的輸入單元個數 n 和不同的階數 k 下,該比值都會隨著的減少而逐漸減少。
, 可以用來近似測量第 k 階交互作用和第 k+1 階交互強度的比值。在下圖中,我們可以發現,在不同的輸入單元個數 n 和不同的階數 k 下,該比值都會隨著的減少而逐漸減少。 
的減少而逐漸減少。這說明隨著訓練進行(即逐漸變小),低階交互強度與高階交互強度的比值逐漸變小,神經網路逐漸學到更高階的交互作用。 下的理論交互值 在各階數上的分佈
在各階數上的分佈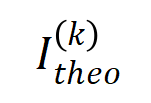 和實際訓練過程中各階交互的分佈
和實際訓練過程中各階交互的分佈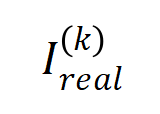 ,發現理論交互分佈可以很好地預測實際訓練中各時間點的交互強度分佈。
,發現理論交互分佈可以很好地預測實際訓練中各時間點的交互強度分佈。 
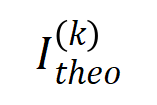 (藍色直方圖)與實際互動分佈
(藍色直方圖)與實際互動分佈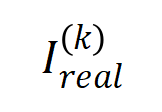 (橘色直方圖)。在訓練第二階段的不同時間點,理論交互分佈都可以很好地預測和匹配實際交互作用的分佈。更多結果請參見論文。
(橘色直方圖)。在訓練第二階段的不同時間點,理論交互分佈都可以很好地預測和匹配實際交互作用的分佈。更多結果請參見論文。  的最優解在噪音逐漸減小時的變化,那麼第一階段就可認為是交互從初始化的隨機交互逐漸收斂到最優解的過程。
的最優解在噪音逐漸減小時的變化,那麼第一階段就可認為是交互從初始化的隨機交互逐漸收斂到最優解的過程。 [1] Huiqi Deng, Na Zou, Mengnan Du, Weifu Chen, Guocan Feng, Ziwei Yang, Zheyang Li, and Quanshi Zhang. Unifying Fourteen Post-Hoc Attribution Methods With Taylor Interactions. IEEE Transactions on Patterng Analysis and Machinelibution Method T-PAMI), 2024.
[2] Xu Cheng, Lei Cheng, Zhaoran Peng, Yang Xu, Tian Han, and Quanshi Zhang. Layerwise Change of Knowledge in Neural Networks. ICML , 2024.
[3] Qihan Ren, Jiayang Gao, Wen Shen, and Quanshi Zhang. Where We Have Arrived in Proving the Emergence of Sparse Interaction Primitives in AI Models4LR, 2024LR .
[4] Lu Chen, Siyu Lou, Benhao Huang, and Quanshi Zhang. Defining and Extracting Generalizable Interaction Primitives from DNNs. ICLR, 2024.
[5] Huilin Zhou, Hao Zhang, Huiqi Deng, Dongrui Liu, Wen Shen, Shih-Han Chan, and Quanshi Zhang. Explaining Generalization Power of a DNN Using Interactive Concepts. AAAI, 2024.
[6] Dongrui Liu, Huiqi Deng, Xu Cheng, Qihan Ren, Kangrui Wang, and Quanshi Zhang. Towards the Difficulty for a Deep Neural Network to Learn Concepts of Different Complexities. NeurIPS, 2023.
[7] Quanshi Zhang, Jie Ren, Ge Huang, Ruiming Cao, Ying Nian Wu, and Song-Chun Zhu. Mining Interpretable AOG Representations from Convolutional Networks via Active Question Answering. IEEE Transactions on Machine Patternsis and Intelligence (IEEE T-PAMI), 2020.
[8] Xin Wang, Jie Ren, Shuyun Lin, Xiangming Zhu, Yisen Wang, and Quanshi Zhang. A Unified Approach to Interpreting and Boosting Adversarial Transferability. ICLR, 2021.
[9] Hao Zhang, Sen Li, Yinchao Ma, Mingjie Li, Yichen Xie, and Quanshi Zhang. Interpreting and Boosting Dropout a from Game- Theoretic View. ICLR, 2021.
[10] Mingjie Li, and Quanshi Zhang. Does a Neural Network Really Encode Symbolic Concept? ICML, 2023.
>[11] Lu Chen, Siyu Lou, Keyan Zhang, Jin Huang, and Quanshi Zhang. HarsanyiNet: Computing Accurate Shapley Values in a Single Forward Propagation. ICML, 2023.
[12] Qihan Ren, Huiqi Deng, Yunuo Chen, Siyu Lou, and Quanshi Zhang. Bayesian Neural Networks Avoid Encoding Perturbation-Sensitive and Complex Concepts. ICML, 2023.
[15] Jie, Die 🎜>[15] Jie, Die Yisen Wang, Lu Chen, Zhanpeng Zhou, Yiting Chen, Xu Cheng, Xin Wang, Meng Zhou, Jie Shi, and Quanshi Zhang. A Unified Game-Theoretic Interpretation of Adversarial Robustness. NeurIPS, 2021.
[16] Wen Shen, Qihan Ren, Dongrui Liu, and Quanshi Zhang. Interpreting Representation Quality of DNNs for 3D Point Cloud Processing. NeurIPS, 2021.
[ Xin Wang, Shuyun Lin, Hao Zhang, Yufei Zhu, and Quanshi Zhang. Interpreting Attributions and Interactions of Adversarial Attacks. ICCV, 2021.
[18] Wen S, Shihihu Huang, Binbin Zhang, Panyue Chen, Ping Zhao, and Quanshi Zhang. Verifiability and Predictability: Interpreting Utilities of Network Architectures for 3D Point Cloud Processing. CVPR, 2021. Zhang, Yichen Xie, Longjie Zheng, Die Zhang, and Quanshi Zhang. Interpreting Multivariate Shapley Interactions in DNNs. AAAI, 2021.[20] Zhang Zhang, Hu Xiaoyi Bao, Da Huo, Ruizhao Chen, Xu Cheng, Mengyue Wu, and Quanshi Zhang. Building Interpretable Interaction Trees for Deep NLP Models. AAAI, 2021.以上是可解釋性終極追問,什麼才是第一性解釋? 20篇CCF-A+ICLR論文給你答案的詳細內容。更多資訊請關注PHP中文網其他相關文章!