


去年 12 月,新架構 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 發起了挑戰。如今,Google DeepMind“Hawk ”和“Griffin ”的推出為 AI 圈提供了新的選擇。

論文標題:Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models - 連結:https://arxiv.org/pdf/2402.19427.pdf
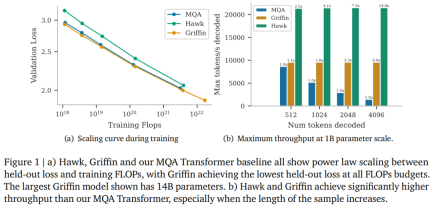
 . 🎜>
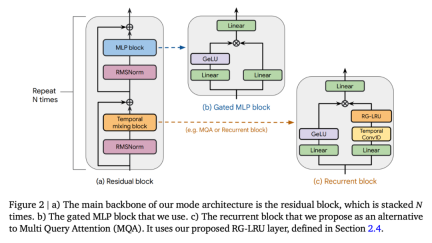
. 🎜>
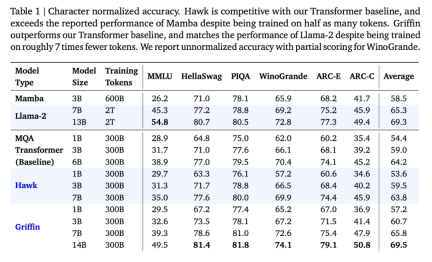
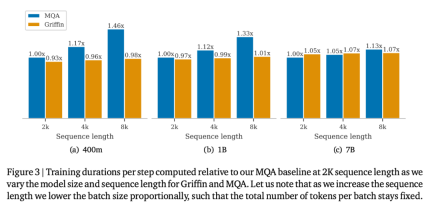

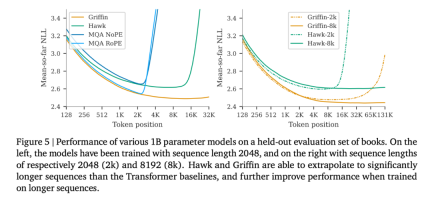
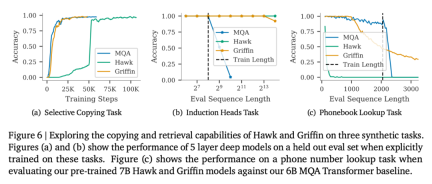
以上是RNN效率媲美Transformer,Google新架構兩連發:同等規模強於Mamba的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 易於理解的解釋如何保存對話歷史記錄(對話日誌)!May 16, 2025 am 05:41 AM
易於理解的解釋如何保存對話歷史記錄(對話日誌)!May 16, 2025 am 05:41 AM高效保存ChatGPT對話記錄的多種方法 您是否曾想過保存ChatGPT生成的對話記錄?本文將詳細介紹多種保存方法,包括官方功能、Chrome擴展程序和截圖等,助您充分利用ChatGPT對話記錄。 了解各種方法的特點和步驟,選擇最適合您的方式。 [OpenAI最新發布的AI代理“OpenAI Operator”介紹](此處應插入OpenAI Operator的鏈接) 目錄 使用ChatGPT導出功能保存對話記錄 官方導出功能的使用步驟 使用Chrome擴展程序保存ChatGPT日誌 ChatGP
 使用Chatgpt創建時間表!解釋可用於創建和調整表的提示May 16, 2025 am 05:40 AM
使用Chatgpt創建時間表!解釋可用於創建和調整表的提示May 16, 2025 am 05:40 AM现代社会节奏紧凑,高效的日程管理至关重要。工作、生活、学习等任务交织在一起,优先级排序和日程安排常常让人头疼不已。 因此,利用AI技术的智能日程管理方法备受关注。特别是利用ChatGPT强大的自然语言处理能力,可以自动化繁琐的日程安排和任务管理,显著提高生产力。 本文将深入讲解如何利用ChatGPT进行日程管理。我们将结合具体的案例和步骤,展示AI如何提升日常生活和工作效率。 此外,我们还会讨论使用ChatGPT时需要注意的事项,确保安全有效地利用这项技术。 立即体验ChatGPT,让您的日程
 如何將chatgpt與電子表格連接!對您可以做什麼的詳盡解釋May 16, 2025 am 05:39 AM
如何將chatgpt與電子表格連接!對您可以做什麼的詳盡解釋May 16, 2025 am 05:39 AM我們將解釋如何將Google表和Chatgpt聯繫起來,以提高業務效率。在本文中,我們將詳細解釋如何使用易於使用的“床單和文檔的GPT”附加組件。無需編程知識。 通過CHATGPT和電子表格集成提高業務效率 本文將重點介紹如何使用附加組件將Chatgpt與電子表格連接。附加組件使您可以輕鬆地將ChatGpt功能集成到電子表格中。 gpt for shee
 6個投資者對AI的預測於2025年May 16, 2025 am 05:37 AM
6個投資者對AI的預測於2025年May 16, 2025 am 05:37 AM專家們預測AI革命的未來幾年,專家們預測專家們都在強調了總體趨勢和模式。例如,對數據的需求很大,我們將在後面討論。此外,對能量的需求是D
 使用chatgpt進行寫作!提示的提示和示例的詳盡說明!May 16, 2025 am 05:36 AM
使用chatgpt進行寫作!提示的提示和示例的詳盡說明!May 16, 2025 am 05:36 AMChatgpt不僅是文本生成工具,而且是一個真正的合作夥伴,可顯著提高作家的創造力。通過在整個寫作過程中使用chatgpt,例如初始手稿創建,構思想法和風格變化,您可以同時節省時間並提高質量。本文將詳細說明在每個階段使用Chatgpt的特定方法,以及最大化生產力和創造力的技巧。此外,我們將研究將Chatgpt與語法檢查工具和SEO優化工具相結合的協同作用。通過與AI的合作,作家可以通過免費想法創造獨創性
 如何在chatgpt中創建圖形!無需插件,因此也可以用於Excel!May 16, 2025 am 05:35 AM
如何在chatgpt中創建圖形!無需插件,因此也可以用於Excel!May 16, 2025 am 05:35 AM使用chatgpt的數據可視化:從圖創建到數據分析 數據可視化以易於理解的方式傳達複雜信息,在現代社會中至關重要。近年來,由於AI技術的進步,使用Chatgpt的圖形創建引起了人們的關注。在本文中,我們將解釋如何以易於理解的方式使用Chatgpt創建圖形,甚至對於初學者。我們將介紹免費版本和付費版本(Chatgpt Plus),特定創建步驟以及如何顯示日語標籤以及實際示例之間的差異。 使用chatgpt創建圖形:從基礎到高級使用 chatg
 用餐盤推動現代LLM的極限?May 16, 2025 am 05:34 AM
用餐盤推動現代LLM的極限?May 16, 2025 am 05:34 AM通常,我們知道AI很大,而且越來越大。快速,越來越快。 但是,具體來說,並不是每個人都熟悉行業中一些最新的硬件和軟件方法,以及它們如何促進更好的結果。人民
 歸檔您的Chatgpt對話歷史!解釋保存的步驟以及如何還原May 16, 2025 am 05:33 AM
歸檔您的Chatgpt對話歷史!解釋保存的步驟以及如何還原May 16, 2025 am 05:33 AMChatGPT對話記錄管理指南:高效整理,充分利用你的知識寶庫! ChatGPT對話記錄是創意和知識的源泉,但不斷增長的記錄如何有效管理呢? 查找重要信息耗時費力?別擔心!本文將詳細講解如何有效“歸檔”(保存和管理)你的ChatGPT對話記錄。我們將涵蓋官方歸檔功能、數據導出、共享鏈接以及數據利用和注意事項。 目錄 ChatGPT的“歸檔”功能詳解 ChatGPT歸檔功能使用方法 ChatGPT歸檔記錄的保存位置和查看方法 ChatGPT歸檔記錄的取消和刪除方法 取消歸檔 刪除歸檔 總結 Ch


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

WebStorm Mac版
好用的JavaScript開發工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3漢化版
中文版,非常好用

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

