
英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-26 08:40:14939瀏覽
開放LLM 社群正是百花齊放、競相爭鳴的時代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 等許多表現優良的模型。但是,相較於以 GPT-4-Turbo 為代表的專有大模型,開放模型在許多領域仍有明顯差距。
在通用模型之外,也有一些專精關鍵領域的開放模型已被開發出來,例如用於程式設計和數學的DeepSeek-Coder-V2、用於視覺- 語言任務的InternVL 1.5(其在某些領域可比肩GPT-4-Turbo-2024-04-09)。
作為「AI 淘金時代的賣鏟王」,英偉達本身也在為開放模型領域做出貢獻,例如其開發的ChatQA 系列模型,請參閱本站報道《英偉達新對話QA 模型準確度超GPT-4,卻遭吐槽:無權重代碼意義不大》。今年初,ChatQA 1.5 發布,其整合了檢索增強式生成(RAG)技術,在對話問答方面的表現超過了 GPT-4。
現在,ChatQA 已經進化到 2.0 版,這次改進的主要方向是擴展上下文視窗。

論文標題:ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
-
論文地址:https://arxiv.org/pdf/M ,擴展LLM 的上下文視窗長度是一大研究和開發熱點,例如本站曾報道過的
《直接擴展到無限長,谷歌Infini-Transformer 終結上下文長度之爭》 。
所有領先的專有 LLM 都支援非常大的上下文視窗 —— 你可以在單一 prompt 中向其灌輸數百頁文字。例如 GPT-4 Turbo 和 Claude 3.5 Sonnet 的上下文視窗大小分別為 128K 和 200K。而 Gemini 1.5 Pro 可支援 10M 長度的上下文,讓人嘆為觀止。 不過開源大模型也在加緊追趕。例如 QWen2-72B-Instruct 和 Yi-34B 各自支援 128K 和 200K 的上下文視窗。但是,這些模型的訓練資料和技術細節並未公開,因此很難去復現它們。此外,這些模型的評估大都基於合成任務,無法準確地代表在真實下游任務上的表現。例如,有多項研究顯示開放 LLM 和領先的專有模型在真實世界長上下文理解任務上依然差距明顯。
而英偉達的這個團隊成功讓開放的 Llama-3 在真實世界長上下文理解任務上的性能趕上了專有的 GPT-4 Turbo。
在 LLM 社群中,長上下文能力有時被認為是一種能與 RAG 競爭的技術。但實事求是地說,這些技術是可以互相增益的。
對於具有長上下文視窗的 LLM 來說,根據下游任務以及準確度和效率之間的權衡,可以考慮在 prompt 附帶大量文本,也可以使用檢索方法從大量文本中高效地提取出相關資訊。 RAG 具有明顯的效率優勢,可為基於查詢的任務輕鬆地從數十億 token 中檢索出相關資訊。這是長上下文模型無法具備的優勢。另一方面,長上下文模型卻非常擅長文件總結等 RAG 可能不擅長的任務。
因此,對於一個先進的 LLM 來說,這兩種能力都需要,如此才能根據下游任務以及準確度和效率需求來考慮使用哪一種。
此前,英偉達開源的 ChatQA 1.5 模型已經能在 RAG 任務上勝過 GPT-4-Turbo 了。但他們沒有止步於此,如今又開源了 ChatQA 2,將足以比肩 GPT-4-Turbo 的長上下文理解能力也整合了進來!
具體來說,他們基於 Llama-3 模型,將其上下文視窗擴展到了 128K(與 GPT-4-Turbo 同等水平),同時還為其配備了當前最佳的長上下文檢索器。
將上下文視窗擴展至 128K那麼,英偉達如何把 Llama-3 的上下文視窗從 8K 提升到了 128K?首先,他們基於 Slimpajama 準備了一個長上下文預訓練語料庫,使用的方法則來自 Fu et al. (2024) 的論文《Data engineering for scaling language models to 128k context》。 訓練過程中他們也得到了一個有趣發現:相比於使用原有的起始和結束 token
和,使用
這樣的特殊字符來分隔不同文檔的效果會更好。他們猜測,原因是 Llama-3 中的 和
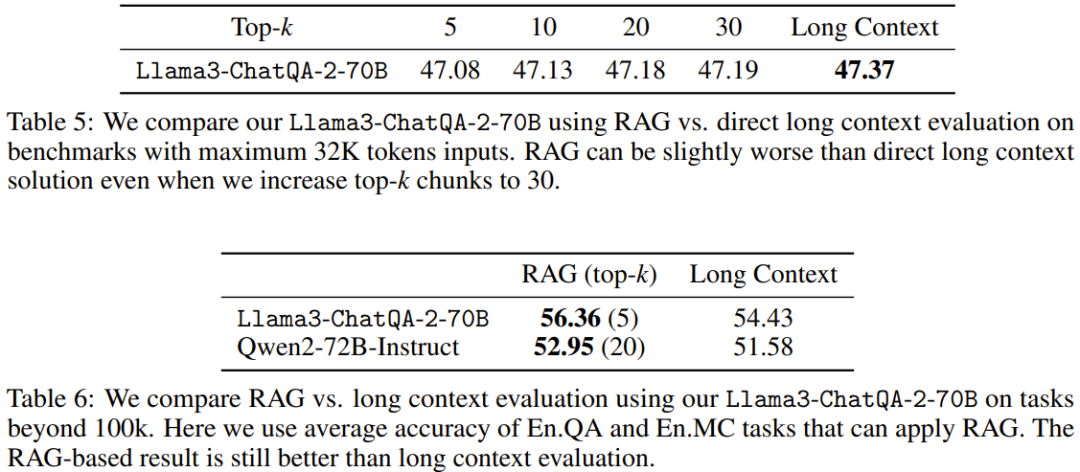
該團隊還設計了一種可同時提升模型的長上下文理解能力和 RAG 性能的指令微調方法。 具體來說,這種指令微調方法分為三個階段。前兩個階段與 ChatQA 1.5 一樣,即首先在 128K 高品質指令遵從資料集訓練模型,然後使用對話問答資料和所提供的上下文組成的混合資料進行訓練。但是,這兩個階段涉及的上下文都比較短 —— 序列長度最大也不過 4K token。為了將模型的上下文視窗大小提升到 128K token,團隊收集了一個長監督式微調(SFT)資料集。 其採用了兩種收集方式: 1. 對於短於 32k 的 SFT 資料序列:利用現有的基於 LongAlpaca12k 的長上下文資料集、來自 Open Orca 的 GPT-4 樣本、Long Data Collections。 2. 對於序列長度在 32k 到 128k 之間的資料:由於收集此類 SFT 樣本的難度很大,因此他們選擇了合成資料集。他們使用了 NarrativeQA,既包含真實的總結(ground truth),也包含語義相關的段落。他們將所有相關段落組裝到了一起,並隨機插入真實總結以模擬用於問答對的真實長文件。 然後,將前兩個階段得到的全長的 SFT 資料集和短 SFT 資料集組合在一起,再進行訓練。這裡學習率設定為 3e-5,批量大小為 32。 長上下文檢索器遇上長上下文 LLM 當前 LLM 使用的 RAG 流程存在一些問題: 1. 為了產生準確答案,top-k 逐塊檢索會引入不可忽略的上下文碎片。舉個例子,之前最佳的基於密集嵌入的檢索器僅支援 512 token。 2. 小top-k(例如5 或10)會導致召回率相對較低,而大top-k(例如100)則會導致產生結果變差,因為之前的LLM 無法很好地使用太多已分塊的上下文。 為了解決這個問題,該團隊提出使用最近期的長上下文檢索器,其支援成千上萬 token。具體來說,他們選擇使用 E5-mistral 嵌入模型作為檢索器。 表 1 比較了 top-k 檢索的不同區塊大小和上下文視窗中的 token 總數。 比較 token 數從 3000 到 12000 的變化情況,團隊發現 token 越多,結果越好,這就確認了新模型的長上下文能力確實不錯。他們還發現,如果總 token 數為 6000,則成本和效能之間會有比較好的權衡。當將總 token 數設定為 6000 後,他們又發現文字區塊越大,結果越好。因此,在實驗中,他們選擇的預設設定是區塊大小為 1200 以及 top-5 的文字區塊。 實驗 評估基準 為了進行全面的評估,分析不同的上下文長度,該團隊使用了三類評估基準: 1. 長上下文基準,超過100K token;中等長上下文基準,低於32K token; 3. 短上下文基準,低於4K token。 如果下游任務可以使用 RAG,就會使用 RAG。 該團隊首先進行了基於合成數據的 Needle in a Haystack(大海撈針)測試,然後測試了模型的真實世界長上下文理解和 RAG 能力。 1. 大海撈針測試 Llama3-ChatQA-2-70B 能否在文本之海中找到目標針?這是一個常用於測試 LLM 長上下文能力的合成任務,可看作是在評估 LLM 的閾值水準。圖 1 展示了新模型在 128K token 中的表現,可以看到新模型的準確度達到了 100%。此測試證實新模型具有堪稱完美的長上下文檢索能力。 在來自 InfiniteBench 的真實世界任務上,該團隊評估了模型在上下文長度超過 100K token 時的性能表現。結果見表 2。 3. token 數在 32K 以內的中等長上下文評估 表 3 給出了上下文的 token 數在 32K 以內時各模型的性能表現。 可以看到,GPT-4-Turbo-2024-04-09 的分數最高,為 51.93。新模型的分數為 47.37,比 Llama-3-70B-Instruct-Gradient-262k 高,但低於 Qwen2-72B-Instruct。原因可能是 Qwen2-72B-Instruct 的預訓練大量使用了 32K token,而團隊使用的持續預訓練語料庫小得多。此外,他們還發現所有 RAG 解決方案的表現都遜於長上下文解決方案,這表明所有這些當前最佳的長上下文 LLM 都可以在其上下文視窗內處理 32K token。 4. ChatRAG Bench:token 數低於 4K 的短上下文評估 在 ChatRAG Bench 上,該團隊評估了模型在上下文長度少於 4K token 時的性能表現,見表 4。 新模型的平均分數為 54.81。儘管這個成績不如 Llama3-ChatQA-1.5-70B,但依然優於 GPT-4-Turbo-2024-04-09 和 Qwen2-72B-Instruct。這證明了一點:將短上下文模型擴展成長上下文模型是有代價的。這也引出了一個值得探索的研究方向:如何進一步擴展上下文視窗同時又不影響其在短上下文任務上的表現? 5. 對比 RAG 與長上下文 表 5 和表 6 比較了使用不同的上下文長度時,RAG 與長上下文解決方案的表現。當序列長度超過 100K 時,僅報告了 En.QA 和 En.MC 的平均分數,因為 RAG 設定無法直接用於 En.Sum 和 En.Dia。 可以看到,當下游任務的序列長度低於 32K 時,新提出的長上下文解決方案優於 RAG。這意味著使用 RAG 可以節省成本,但準確度會下降。 另一方面,當上下文長度超過 100K 時,RAG(Llama3-ChatQA-2-70B 使用 top-5,Qwen2-72B-Instruct 使用 top-20)優於長上下文解決方案。這意味著當 token 數超過 128K 時,即使當前最佳的長上下文 LLM,也可能難以實現有效的理解和推理。團隊建議在這種情況下,能使用 RAG 就盡量使用 RAG,因為其能帶來更高的準確度和更低的推理成本。 
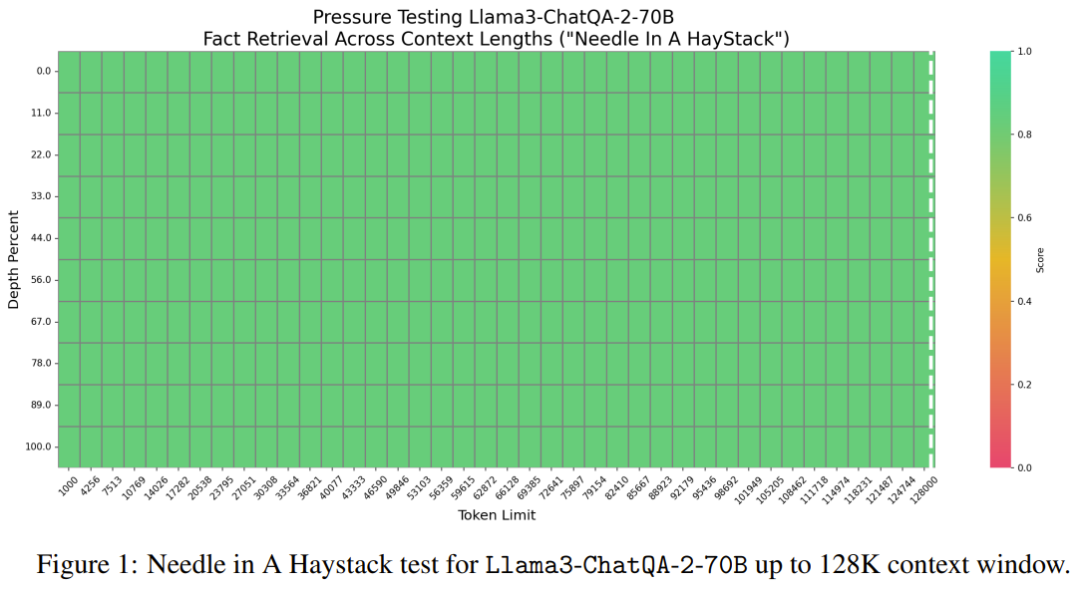 2. 超過 100K token 的長上下文評估
2. 超過 100K token 的長上下文評估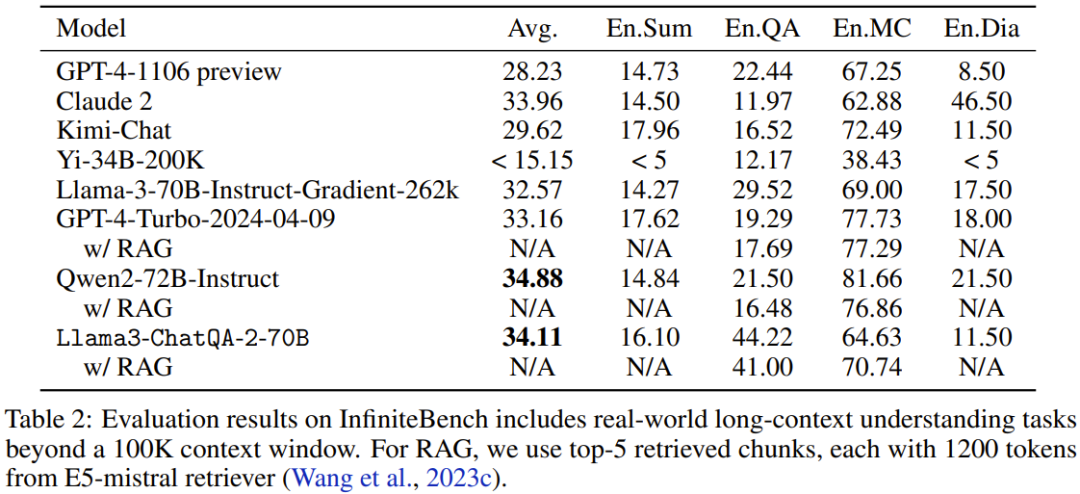 可以看到,新模型的表現優於許多當前最佳模型,例如GPT4-Turbo-2024-04-09 (33.16)、GPT4-1106 preview (28.23)、Llama-3-70B-Instruct -Gradient-262k (32.57) 和Claude 2 (33.96)。此外,新模型的成績也已經非常接近 Qwen2-72B-Instruct 得到的最高分數 34.88。整體來看,英偉達的這個新模型頗具競爭力。
可以看到,新模型的表現優於許多當前最佳模型,例如GPT4-Turbo-2024-04-09 (33.16)、GPT4-1106 preview (28.23)、Llama-3-70B-Instruct -Gradient-262k (32.57) 和Claude 2 (33.96)。此外,新模型的成績也已經非常接近 Qwen2-72B-Instruct 得到的最高分數 34.88。整體來看,英偉達的這個新模型頗具競爭力。 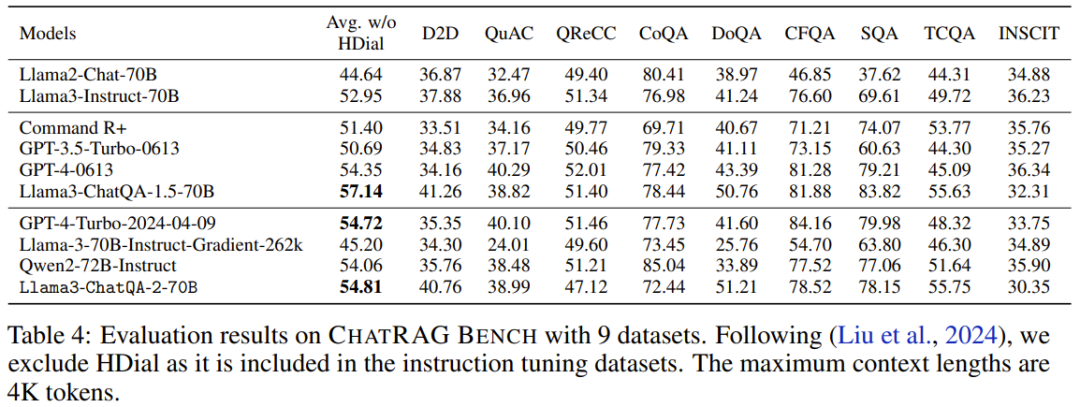
以上是英偉達對話模式ChatQA進化到2.0版本,上下文長度提到128K的詳細內容。更多資訊請關注PHP中文網其他相關文章!