
字節大模型同傳智能體,一出手就是媲美人類的同聲傳譯水平

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-25 17:53:431088瀏覽
無論是語速超快、發音複雜的繞口令,還是精妙絕倫的文言文,又或是充滿即興和靈感的隨意聊天,模型都能流暢自然地給出準確而地道的翻譯結果。
近年來,人工智慧(Aritificial Intelligence, AI),尤其是以大語言模型(Large Language Models, LLMs)為代表的AI 正以驚人的速度發展,這些模型在多種自然語言處理任務中展現了卓越的能力。然而,儘管在許多領域取得了突破,代表著人類頂尖語言層次的同聲傳譯(Simultaneous Interpretation, SI)依然是一個未被完全攻克的難題。
市面上傳統的同聲傳譯軟體通常採用級聯模型(cascaded model)的方法,即先進行自動語音辨識(Automatic Speech Recognition, ASR),然後再進行機器翻譯(Machine Translation, MT)。這種方法有一個顯著的問題 —— 錯誤傳播。 ASR 過程中的錯誤會直接影響後續的翻譯質量,導致嚴重的誤差累積。此外,傳統的同聲傳譯系統由於受限於低延時的要求,通常只使用了性能較差的小模型,這在應對複雜多變的實際應用場景時存在瓶頸。
來自字節跳動ByteDance Research 團隊的研究人員推出了端到端同聲傳譯智能體:Cross Language Agent - Simultaneous Interpretation, CLASI,其效果已接近專業人工水平的同聲傳譯,展示了巨大的潛力和先進的技術能力。 CLASI 採用了端對端的架構,規避了級聯模型中錯誤傳播的問題,依託於豆包基座大模型和豆包大模型語音組的語音理解能力,同時具備了從外部獲取知識的能力,最終形成了足以媲美人類層面的同聲傳譯系統。

論文地址:https://byteresearchcla.github.io/clasi/technical_report.pdf 展示頁:https://byteresearchclaasi.展示
視訊Demo:首先用幾則即興視訊來感受一下CLASI 的效果,所有字幕均為即時錄影輸出。我們可以看到,無論是語速超快、發音複雜的繞口令,還是精妙絕倫的文言文,又或是充滿即興和靈感的隨意聊天,模型都能流暢自然地給出準確而地道的翻譯結果。更不用說,CLASI 在其老本行 —— 會議場景翻譯中表現得尤為出色。
即興對話-星座
朗讀  繞口令 更多影片點選「閱讀原文」檢視
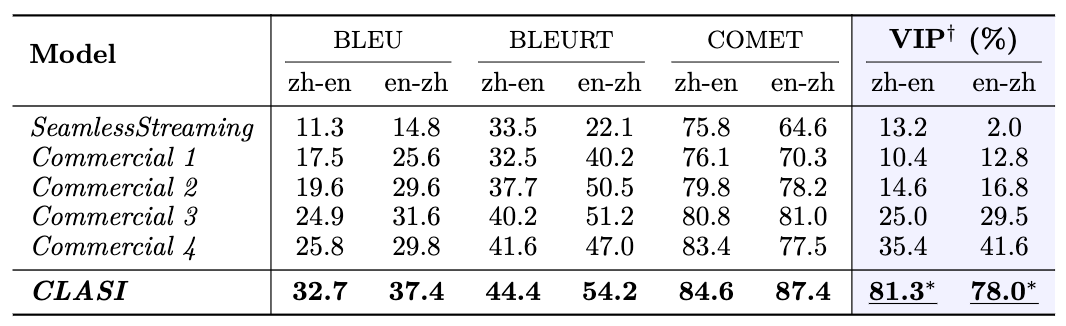
繞口令 更多影片點選「閱讀原文」檢視 定量比較:研究人員分別在中英、英中翻譯語向上,針對4 個不同領域邀請專業的同傳譯員進行了人工評測,使用了與人工同傳一致的評價指標:有效資訊佔比(百分制)。圖中可以看到,CLASI 系統大幅領先所有商業系統和開源 SOTA 系統,並且在某些測試集上甚至達到或超過了人類同傳水平(一般認為人類同傳平均水平大概在 80%)。
定量比較:研究人員分別在中英、英中翻譯語向上,針對4 個不同領域邀請專業的同傳譯員進行了人工評測,使用了與人工同傳一致的評價指標:有效資訊佔比(百分制)。圖中可以看到,CLASI 系統大幅領先所有商業系統和開源 SOTA 系統,並且在某些測試集上甚至達到或超過了人類同傳水平(一般認為人類同傳平均水平大概在 80%)。 
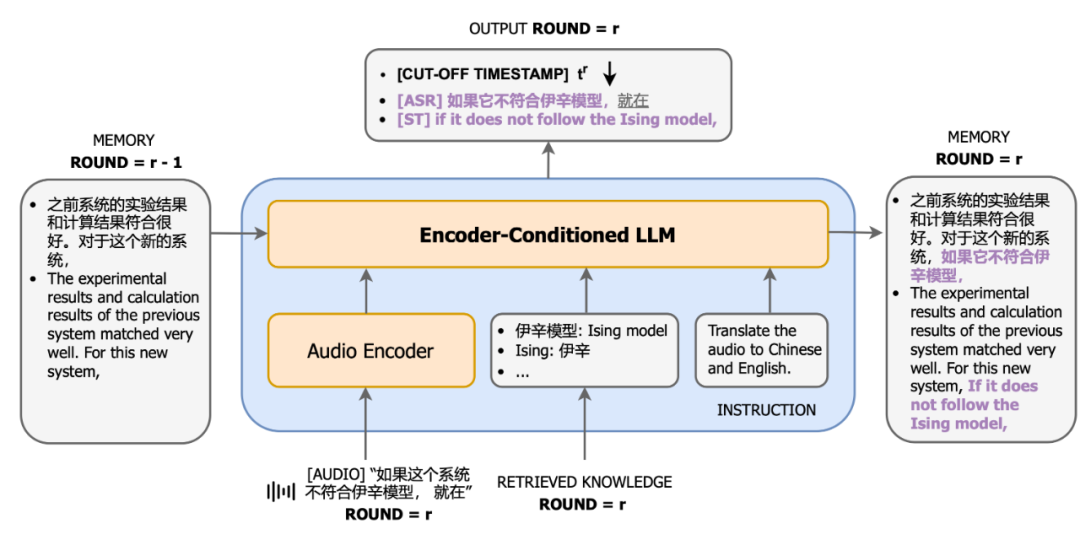
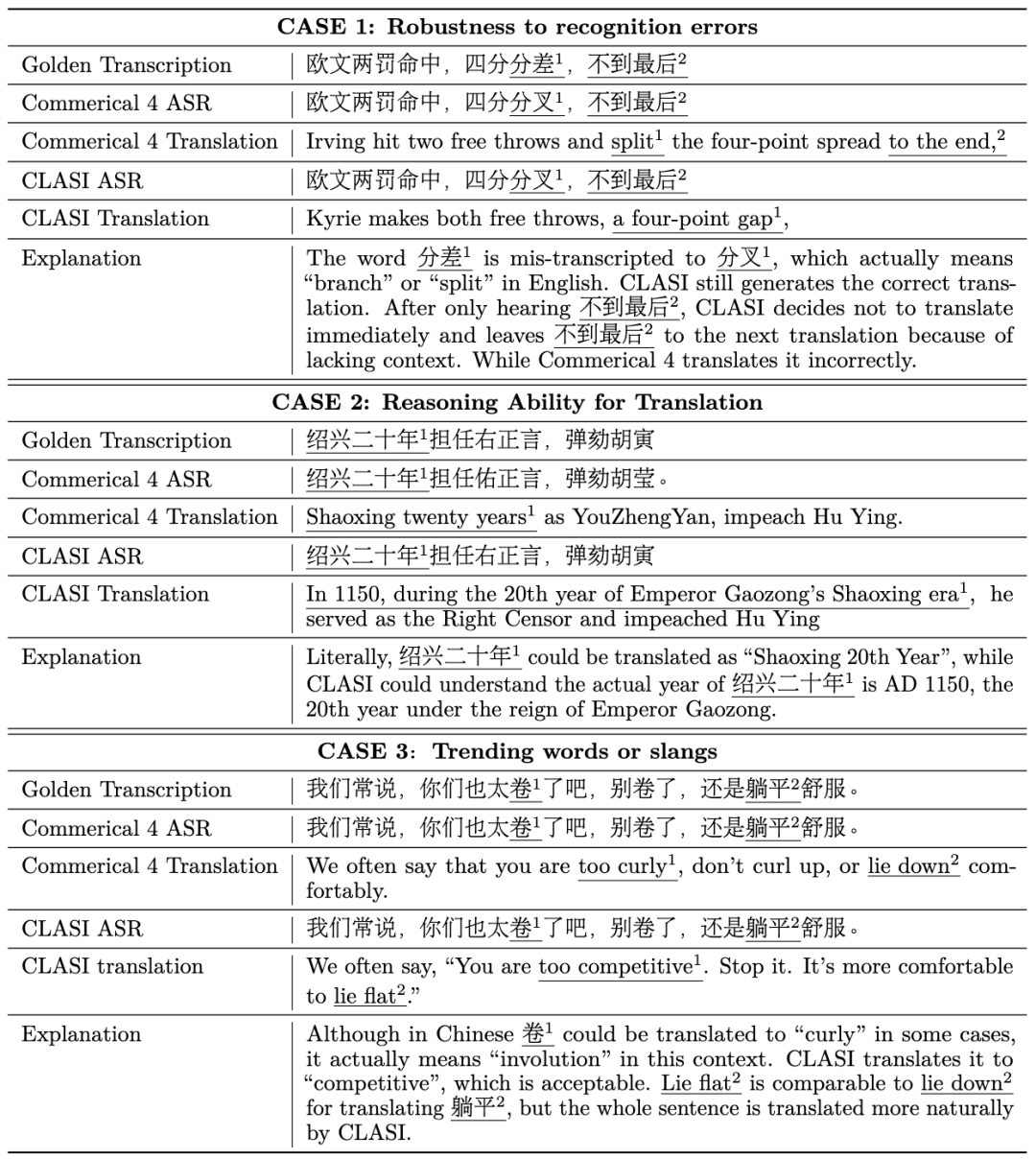
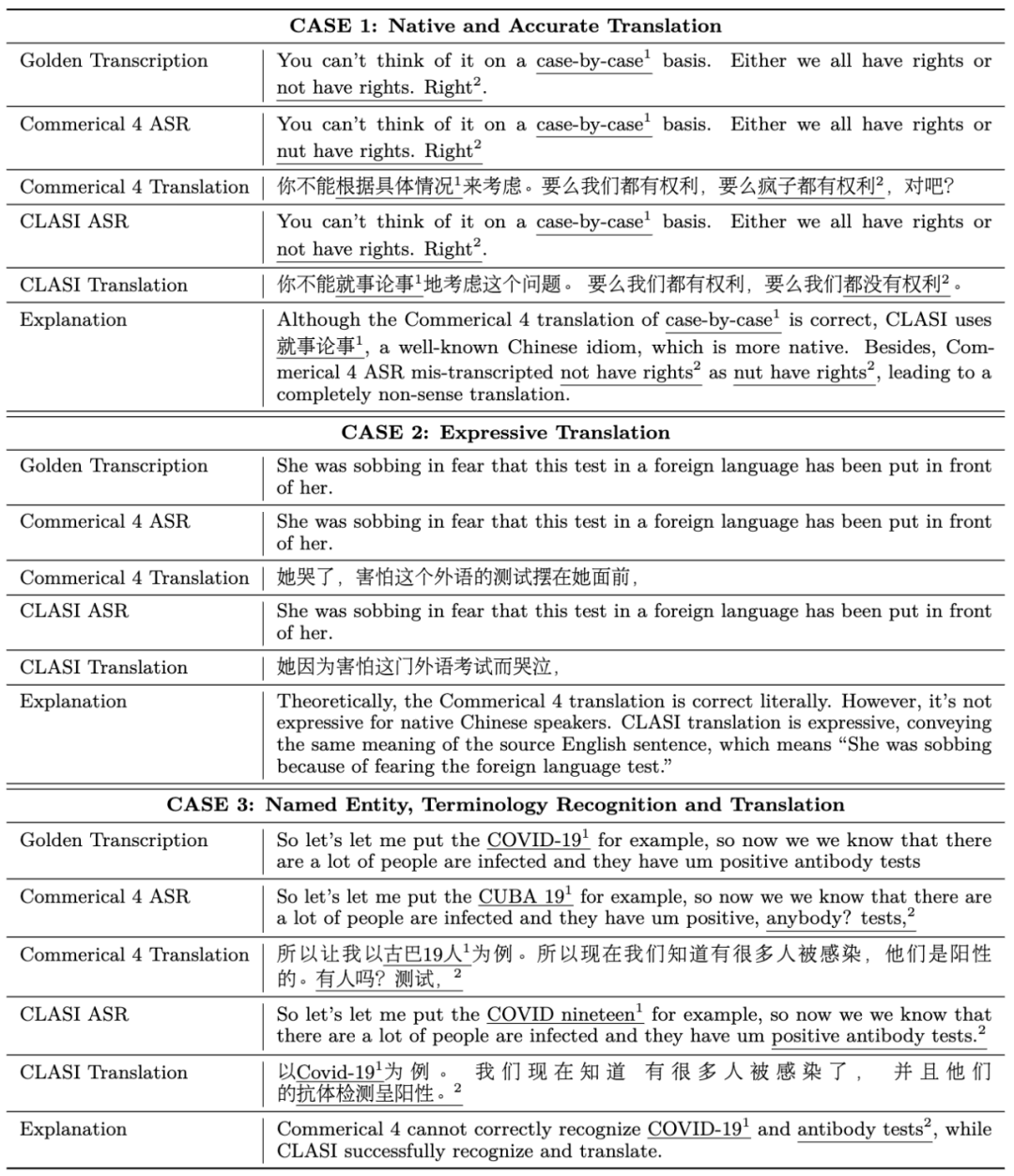
系統架構 系統架構上,CLASI 採用了基於LLM 智能體的架構(下圖左),將同聲傳譯定義為一系列簡單且協調的操作,包括讀入音頻流,檢索(可選),讀取記憶體,更新記憶體,輸出等。整個流程由大語言模型自主控制,在即時性和翻譯品質之間達到了高效的平衡。該系統能夠根據實際需求靈活調整各個環節的處理策略,確保在高效傳遞訊息的同時,保持翻譯內容的準確性和連貫性。 CLASI 底層模型是一個 Encoder-conditioned LLM,在海量的無監督和有監督資料上進行了預訓練。 CLASI 模型的系統架構如下圖所示。 圖 1:圖示展示了 CLASI 的整體操作流程。在步驟 1 中,CLASI 處理目前輸入的音訊資料。接下來檢索器會被啟動(可選),從使用者自訂的知識庫中取得相關資訊。在這個範例中,使用知識庫中的翻譯對 “伊辛模型: Ising model” 能夠幫助模型輸出正確的譯本。在步驟 3 中,CLASI 從上一輪的記憶體中載入轉寫(可選)和翻譯。接下來(步驟 4 和步驟 5),CLASI 可能會啟用思維鏈(CoT)來輸出轉寫(可選)和翻譯結果,然後更新其記憶體。最後,返回步驟 1 以處理下一輪的語音。 圖 2:CLASI 的結構圖。在第 r 輪中,CLASI 將目前音訊流、前序的記憶體(r-1)和檢索到的知識(如果有)作為輸入。 CLASI 根據給定的指示輸出反應,然後更新記憶體。同時,CLASI 也會輸出截止當前,最後一個語意片段的截止時間戳記。對於給定的範例,短語 “就在” 之前的內容被認為是完整的語義片段,所以截止時間戳就在此短語之前。 實驗結果 表1:人工評測有效字段佔比(Valid Information Proportion, VIP)中,CLASI 系統顯著超過了兩個其他系統顯著,並且在所有競品上均有顯著競品達到了78% 以上的準確性。一般而言,可以認為人類同傳的準確性在 70% 以上,理想情況下可以達到 95%,研究人員以 80% 的準確性作為高水準人類譯員的平均標準。 範例分析 中翻英: 英翻中: 可以看到在多個方面,CLASI 的翻譯。 總結 來自字節跳動 ByteDance Research 團隊的研究人員提出了基於豆包大模型的同傳智能體:CLASI。由於大規模預訓練和模仿學習,在人工評估中,CLASI 的表現顯著優於現有的自動同聲傳譯系統的性能,幾乎達到人類同傳水平。 1. 研究人員提出了一種透過模仿專業人類譯員的、數據驅動的讀寫策略。此策略無需複雜的人類預設計,即可輕鬆平衡翻譯品質和延遲。與大多數商業系統在翻譯過程中頻繁重寫輸出以提高品質不同,該策略保證所有輸出在保持高品質的同時是確定性的。 2. 人類譯員一般需要預先準備同傳內容,受此啟發,研究人員引入了一種多模態檢索增強生成(MM-RAG)過程,使 LLM 實時地具有領域特定的知識。所提出的模組在推理過程中以最小的計算開銷進一步提高了翻譯品質。 3. 研究人員與專業人類同傳譯員密切合作,制定了新的人工評估策略 「有效資訊佔比」(VIP),並公開了詳細的指南。同時也發布了一個更接近現實場景的長語音翻譯的多領域人工標註測試集。 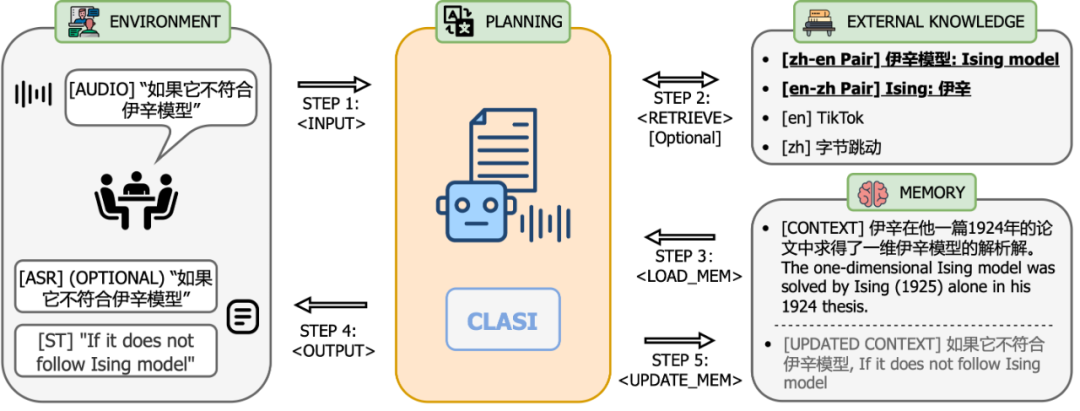
以上是字節大模型同傳智能體,一出手就是媲美人類的同聲傳譯水平的詳細內容。更多資訊請關注PHP中文網其他相關文章!