Llama 3.1 終於現身了,不過出處卻不是 Meta 官方。 今日,Reddit 上新版 Llama 大模型洩露的消息遭到了瘋傳,除了基礎模型,還包括 8B、70B 和最大參數的 405B 的基準測試結果。 
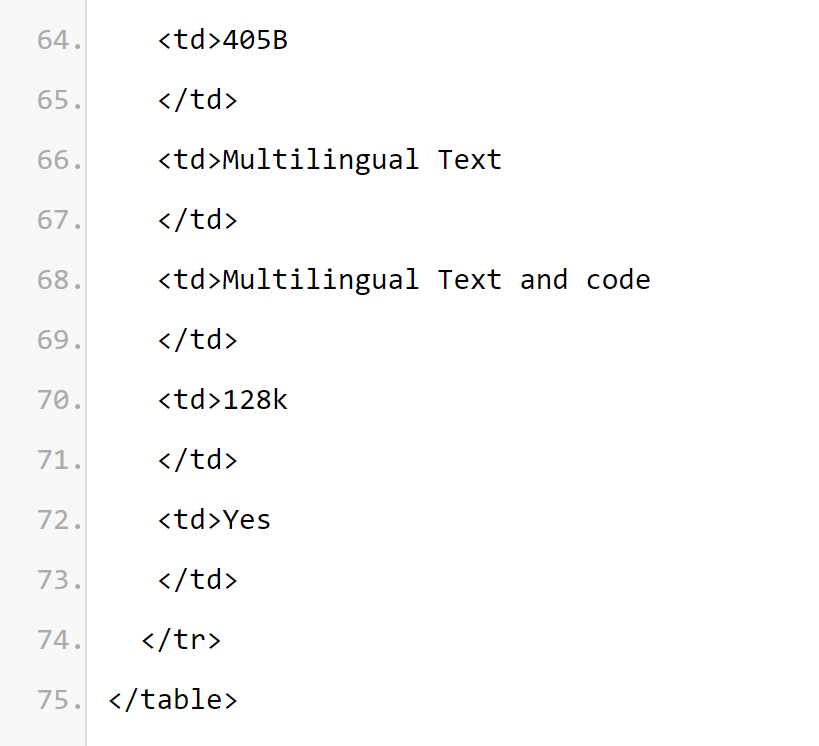
下圖為 Llama 3.1 各版本與 OpenAI GPT-4o、Llama 3 8B/70B 的比較結果。可以看到,即使是 70B 的版本,也在多項基準上超過了 GPT-4o。
顯然,3.1 版本的8B 和70B 模型是由405B 蒸餾得來的,因此相比上一代有著明顯的效能提升。
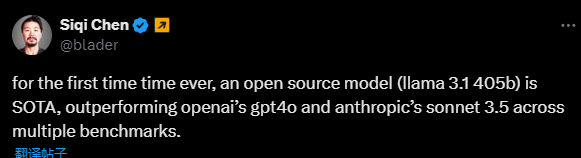
有網友表示,這是
首次開源模型超越了 GPT4o 和 Claude Sonnet 3.5 等閉源模型,在多個 benchmark 上達到 SOTA
。 與此同時,Llama 3.1 的模型卡流出,細節也洩露了(從模型卡中標註的日期看出基於 7 月 23 日發布)。
有人總結了以下幾個亮點:
模型使用了公開來源的15T+ tokens 進行訓練,預訓練資料截止日期為2023 年公開資料可用的指令微調資料集(與Llama 3 不同)和1500 萬個合成樣本;
-
模型支援多語言,包括英語、法語、德語、印地語、義大利語、葡萄牙語、西班牙語和泰語。
作用中:https
雖然洩漏的Github 連結目前404 了,但有網友給了下載連結(不過為了安全,建議還是等今晚的官方管道公佈):不過這畢竟是個千億級大模型,下載之前請準備好足夠的硬碟空間:
以下是Llama 3.1 模型卡片中的重要內容:
模型基本資訊
Meta Llama 3.1 多語言大型語言模型(LLM) 集合經過預訓練和指令和指令、70B 和405B(文字輸入/ 文字輸出)。 Llama 3.1 指令微調的純文字模型(8B、70B、405B)針對多語言對話用例進行了最佳化,在常見的行業基準上優於許多可用的開源和閉源聊天模型。
模型架構:Llama 3.1 是最佳化了的 Transformer 架構自迴歸語言模型。微調後的版本使用 SFT 和 RLHF 來對齊可用性與安全偏好。
支援語言:英語、德語、法語、義大利語、葡萄牙語、印地語、西班牙語和泰語。
從模型卡資訊可以推斷,
Llama 3.1 系列模型的上下文長度為 128k
。所有模型版本都使用分組查詢注意力(GQA)來提高推理可擴展性。
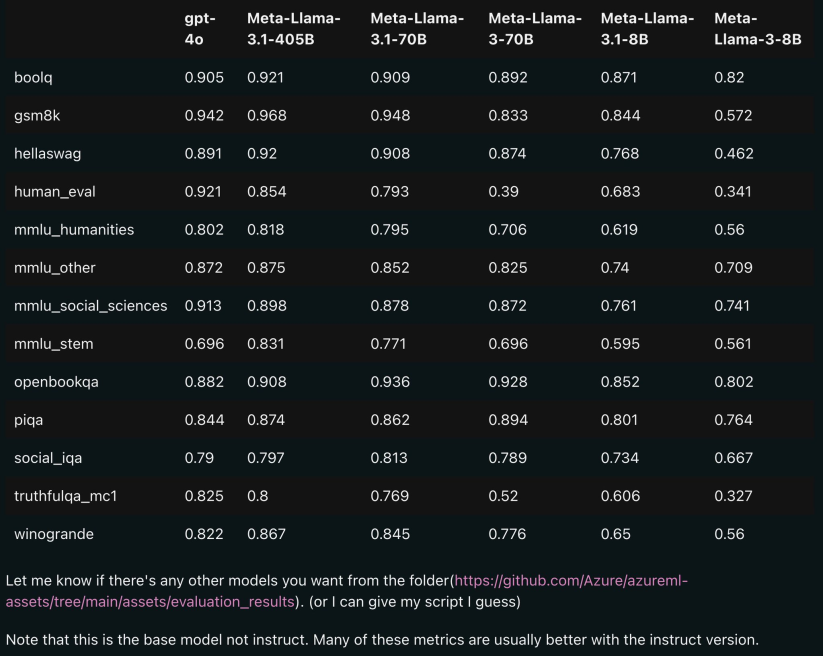
預期用例。 Llama 3.1 旨在用於多語言的商業應用與研究。指令調整的純文字模型適用於類別助理聊天,而預訓練模型可以適應各種自然語言生成任務。 Llama 3.1 模型集也支持利用其模型輸出來改進其他模型(包括合成資料生成和蒸餾)的能力。 Llama 3.1 社群授權協議允許這些用例。 Llama 3.1 在比 8 種受支援語言更廣泛的語言集合上進行訓練。開發人員可以針對8 種受支援語言以外的語言對Llama 3.1 模型進行微調,前提是遵守Llama 3.1 社區許可協議和可接受使用策略, 並且在這種情況下負責確保以安全和負責任的方式使用其他語言的Llama 3.1。 首先是訓練要素,Llama 3.1 使用自訂訓練庫、Meta 客製化的GPU 叢集、註釋和評估。 其次是訓練能耗,Llama 3.1 訓練在 H100-80GB(TDP 為 700W)類型硬體上累計使用了 39.3 M GPU 小時的計算。這裡訓練時間是訓練每個模型所需的總 GPU 時間,功耗是每個 GPU 裝置的峰值功率容量,根據用電效率進行了調整。 訓練溫室氣體排放。 Llama 3.1 訓練期間基於地理基準的溫室氣體總排放量預估為 11,390 噸二氧化碳當量。自2020 年以來,Meta 在全球營運中一直保持淨零溫室氣體排放,並將其100% 的電力使用與再生能源相匹配,因此訓練期間基於市場基準的溫室氣體總排放量為0 噸二氧化碳當量。 用於確定訓練能源使用和溫室氣體排放的方法可以在以下論文中找到。由於 Meta 公開發布了這些模型,因此其他人不需要承擔訓練能源使用和溫室氣體排放。 論文地址:https://arxiv.org/pdf/2204.05149約150007537535353 萬個資料的資料。預訓練。微調資料包括公開可用的指令資料集,以及超過 2500 萬個綜合生成的範例。 資料新鮮度:預訓練資料的截止日期為 2023 年 12 月。 在這一部分,Meta 報告了 Llama 3.1 模型在標註 benchmark 上的評分結果。所有的評估,Meta 都是使用內部的評估庫。
Considérations sur les risques de sécuritéL'équipe de recherche de Llama s'engage à fournir à la communauté des chercheurs des ressources précieuses pour étudier la robustesse du réglage fin de la sécurité et à fournir aux développeurs des modèles prêts à l'emploi sûrs et robustes pour une variété de d'applications pour réduire la charge de travail des développeurs déployant des systèmes d'IA sécurisés. L'équipe de recherche utilise une approche de collecte de données à multiples facettes, combinant les données générées par les humains auprès des fournisseurs avec des données synthétiques pour atténuer les risques de sécurité potentiels. L'équipe de recherche a développé un certain nombre de classificateurs basés sur un grand modèle de langage (LLM) pour sélectionner judicieusement des invites et des réponses de haute qualité, améliorant ainsi le contrôle de la qualité des données. Il convient de mentionner que Llama 3.1 attache une grande importance au modèle de rejet des invites bénignes et au ton de rejet. L’équipe de recherche a introduit des invites de limites et des invites contradictoires dans la politique de données sécurisées et a modifié les réponses aux données sécurisées pour suivre les directives de ton. Le modèle Llama 3.1 n'est pas conçu pour être déployé seul, mais doit être déployé dans le cadre du système global d'intelligence artificielle, avec des « garde-corps de sécurité » supplémentaires fournis si nécessaire. Les développeurs doivent déployer des mesures de sécurité du système lors de la création de systèmes d'agents. Veuillez noter que cette version introduit de nouvelles fonctionnalités, notamment des fenêtres contextuelles plus longues, des entrées et sorties multilingues et une éventuelle intégration des développeurs avec des outils tiers. Lors de la construction avec ces nouvelles fonctionnalités, en plus de considérer les meilleures pratiques qui s'appliquent généralement à tous les cas d'utilisation de l'IA générative, vous devez également accorder une attention particulière aux problèmes suivants : Utilisation des outils : Comme pour le développement logiciel standard, le développeur est responsable d'intégrer LLM avec les outils et services de son choix. Ils doivent élaborer des politiques claires pour leurs cas d'utilisation et évaluer l'intégrité des services tiers qu'ils utilisent afin de comprendre les limites de sûreté et de sécurité lors de l'utilisation de cette fonctionnalité. Multi-langue : Lama 3.1 prend en charge 7 langues en plus de l'anglais : français, allemand, hindi, italien, portugais, espagnol et thaï. Llama peut être capable de produire du texte dans d'autres langues, mais ce texte peut ne pas répondre aux seuils de performances de sécurité et d'assistance. Les valeurs fondamentales de Llama 3.1 sont l’ouverture, l’inclusion et la serviabilité. Il est conçu pour servir tout le monde et adapté à une variété de cas d’utilisation. Par conséquent, Llama 3.1 est conçu pour être accessible aux personnes de tous horizons, expériences et perspectives. Llama 3.1 est centré sur les utilisateurs et leurs besoins, sans insérer de jugements ou de normes inutiles, tout en reflétant également la reconnaissance du fait que même un contenu qui peut sembler problématique dans certains contextes peut être utile dans d'autres. Llama 3.1 respecte la dignité et l'autonomie de tous les utilisateurs et, en particulier, respecte les valeurs de libre pensée et d'expression qui alimentent l'innovation et le progrès. Mais Llama 3.1 est une nouvelle technologie, et comme toute nouvelle technologie, son utilisation comporte des risques. Les tests effectués jusqu’à présent n’ont pas couvert et ne peuvent pas couvrir toutes les situations. Par conséquent, comme tous les LLM, les résultats potentiels de Llama 3.1 ne peuvent pas être prédits à l'avance et, dans certains cas, le modèle peut réagir de manière inexacte, biaisée ou autrement inacceptable aux invites de l'utilisateur. Par conséquent, avant de déployer une application du modèle Llama 3.1, les développeurs doivent effectuer des tests de sécurité et des réglages précis pour l'application spécifique du modèle. Source de la carte modèle : https://pastebin.com/9jGkYbXYInformations de référence : https://x.com/op7418/status/1815340034717069728 https : //x.com/iScienceLuvr/status/1815519917715730702https://x.com/mattshumer_/status/1815444612414087294以上是首個超越GPT4o級開源模型! Llama 3.1洩密:4050億參數,下載連結、模型卡都有了的詳細內容。更多資訊請關注PHP中文網其他相關文章!




 模型基本資訊
模型基本資訊