AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本工作由中科大認知智能全國重點實驗室 IEEE F 本工作由中科大認知智能全國重點實驗室 IEEE F 諾恩方舟團隊完成。陳恩紅教授團隊深耕資料探勘、機器學習領域,在頂尖期刊與會議發表多篇論文,Google學術論文引用超兩萬次。諾亞方舟實驗室是華為公司從事人工智慧基礎研究的實驗室,秉持理論研究與應用創新並重的理念,致力於推動人工智慧領域的技術創新與發展。
資料是大語言模型(LLMs)成功的基石,但並非所有資料都有益於模型學習。直覺上,高品質的樣本在教授 LLM 上預期會有更好的效率。因此,現有方法通常專注於基於品質的數據選擇。然而,這些方法中的大多數獨立地評估不同的資料樣本,忽略了樣本之間複雜的組合效應。如圖 1 所示,即使每個樣本品質完美,由於它們的互資訊冗餘或不一致性,它們的組合可能仍然次優。儘管基於品質的子集由所有三個優質樣本組成,但它們編碼的知識實際上是冗餘和衝突的。相較之下,另一個由幾個相對較低品質但多樣化的樣本組成的資料子集在教授 LLM 方面可能傳達更多資訊。因此,基於品質的資料選擇並未完全符合最大化 LLM 知識掌握的目標。
而本文旨在揭示 LLM 效能與資料選擇之間的內在關係。受LLM 資訊壓縮本質的啟發,我們發現了一條entropy law,它將LLM 效能與資料壓縮率和前幾步模型訓練的損失加以聯繫,分別反映了資料集的資訊冗餘程度和LLM 對資料集中固有知識的掌握程度。透過理論推導和實證評估,我們發現模型表現與訓練資料的壓縮率呈負相關,而這通常會產生較低的訓練損失。基於 entropy law 的發現,我們提出了一種非常高效且通用的資料選擇方法用於訓練 LLM,名為 ZIP,其旨在優先選擇低壓縮率的資料子集。 ZIP 分多階段、貪心地選擇多樣化的數據,最終獲得一個具有良好多樣性的數據子集。 
團隊:中科大認知智慧全國重點實驗室陳恩紅團隊,華為諾亞方舟實驗室論文連結: https://arxiv.org/pdf/2407.066455% : https://github.com/USTC-StarTeam/ZIP
圖 1時,性能之間的關係進行理論分析。直覺上,訓練資料的正確性和多樣性會影響最終模型的表現。同時,如果資料有嚴重的內在衝突或模型對資料編碼的資訊掌握不佳,LLM 的效能可能會次優。基於這些假設,我們將 LLM 的效能表示為 Z ,其預期會受到以下因素的影響:資料壓縮率 R:直覺上,壓縮率越低的資料集顯示資訊密度越高。
訓練損失 L:表示資料對模型來說是否難以記憶。在相同的基礎模型下,高訓練損失通常是由於資料集中存在雜訊或不一致的資訊。
資料一致性 C:資料的一致性透過給定前文情況下下一個 token 的機率的熵來反映。更高的資料一致性通常會帶來更低的訓練損失。 平均數據質量 Q:反映了數據的平均樣本級質量,可以透過各種客觀和主觀方面來衡量。
-
給定一定量的訓練數據,模型性能可以透過上述因素來估計:
其中 f 是一個隱函數。給定一個特定的基礎模型,L 的規模通常取決於R 和C,可以表示為:
由於具有更高同質性或更好數據一致性的數據集更容易被模型學習,L預計在R 和C 上是單調的。因此,我們可以將上述公式改寫為:
其中 g' 是一個反函數。結合上述三個方程,我們得到:
其中 h 是另一個隱函數。如果資料選擇方法不會顯著改變平均資料品質 Q,我們可以近似地將變數 Q 視為常數。因此,最終效能可以粗略地表示為:這意味著模型效能與資料壓縮率和訓練損失有關。我們將這種關係稱為 Entropy law。
- 如果將 C 視為常數,訓練損失直接受壓縮率影響。因此,模型性能由壓縮率控制:如果資料壓縮率 R 較高,那麼 Z 通常較差,這將在我們的實驗中得到驗證。
- 在相同的壓縮率下,較高訓練損失意味著較低的資料一致性。因此,模型學到的有效知識可能更有限。這可以用來預測 LLM 在具有相似壓縮率和樣本品質的不同數據上的表現。我們將在後續展示這項推論在實務上的應用。
在entropy law 的指導下,我們提出了ZIP 資料來選擇,並透過樣本數據在有限的訓練資料預算下最大化有效資訊量。出於效率考量,我們採用了一種迭代多階段貪心範式,以高效地獲得具有相對低壓縮率的近似解。在每輪迭代中,我們首先使用全域選擇階段來選擇一組具有低壓縮率的候選樣本池,找到資訊密度高的樣本。然後,我們採用粗粒度的局部選擇階段,選擇一組與已選樣本冗餘度最低的較小樣本集。最後,我們使用細粒度的局部選擇階段,最小化要添加樣本之間的相似性。上述過程持續進行直到獲得足夠的數據,具體演算法如下:
比較不同的SFT 資料選擇演算法,基於ZIP 選擇資料所訓練所得的模型效能上展現優勢,並且在效率上也佔優。具體結果請見下表:
得益於 ZIP 的模型無關、內容無感知的特性,其同樣也可應用於偏好對齊階段的資料選擇。而 ZIP 所選擇的數據同樣展現出了較大的優勢。具體結果請見下表:
2.Entropy law 的實驗驗證
基於SFT 資料選擇實驗,我們基於模型效果、資料壓縮率、以及模型效果擬合了多個關係曲線。結果見圖 2 以及圖 3,我們可以從圖中觀察到三個因素之間的緊密關聯。首先,低壓縮率資料通常會帶來更好的模型效果,這是因為LLMs 的學習過程與資訊壓縮高度相關,我們可以將LLM 視為資料壓縮器,那麼壓縮率較低的資料意味著更多的知識量,從而對壓縮器更有價值。同時,可以觀察到較低的壓縮率通常伴隨著更高的訓練損失,這是因為難以壓縮的數據攜帶了更多的知識,對 LLM 吸收其中蘊含的知識提出了更大的挑戰。
Figure 3 Llama-3-8B We provide an entropy law to guide the incremental update of LLM training data in real scenarios Applications. In this task scenario, the amount of training data remains relatively stable, and only a small portion of the data is modified. The results are shown in Figure 4, where to are 5 data versions that are gradually updated incrementally. Due to confidentiality requirements, only the relative relationship of the model effects under different compression rates is provided. According to entropy law predictions, assuming that data quality does not drop significantly after each incremental update, it can be expected that model performance will improve as the data compression rate decreases. This prediction is consistent with the results for data versions to in the figure. However, data version shows an unusual increase in loss and data compression ratio, which indicates the potential for model performance degradation due to reduced consistency of the training data. This prediction was further confirmed by subsequent model performance evaluation. Therefore, entropy law can serve as a guiding principle for LLM training, predicting the potential risk of LLM training failure without training the model on the full dataset until convergence. This is particularly important given the high cost of training LLMs.
以上是中科大聯合華為諾亞提出Entropy Law,揭秘大模型效能、資料壓縮率以及訓練損失關係的詳細內容。更多資訊請關注PHP中文網其他相關文章!






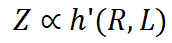



 Figure 3 Llama-3-8B
Figure 3 Llama-3-8B