近日,快手可靈大模型團隊開源了名為LivePortrait的可控人像視訊生成框架,該框架能夠準確、實時地將驅動視頻的表情、姿態遷移到靜態或動態人像視頻上,生成極具表現力的影片結果。如下動圖:
 紙中
紙中5
紙
紙
5
紙 紙
紙
紙
555 LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control 》

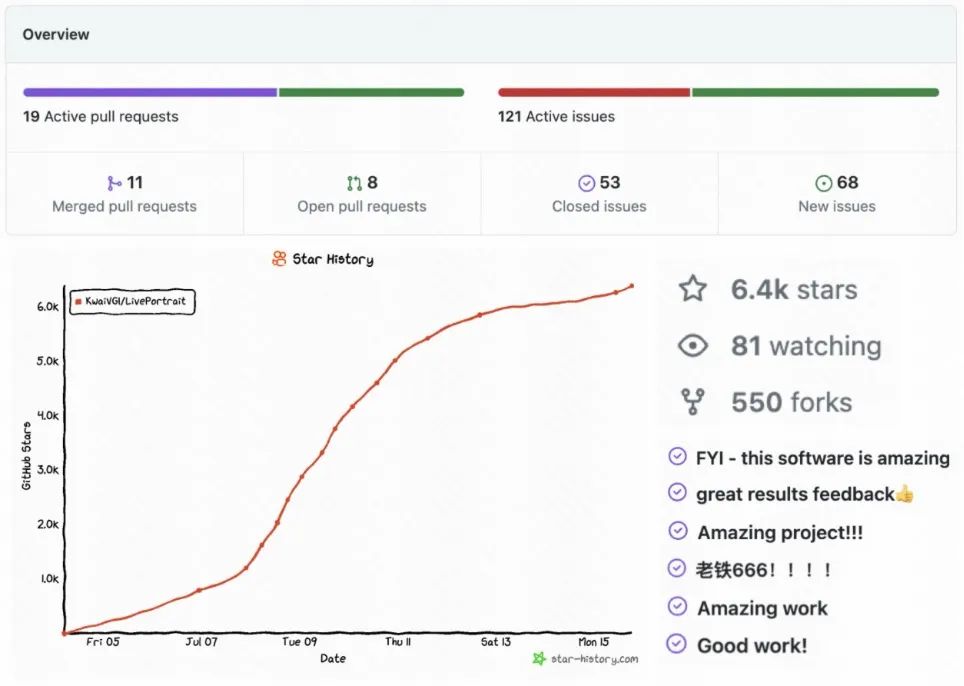
同時,LivePotrait獲得了開源社群的廣泛關注,短短一周多時間左右,在GitHub上總計收穫了6.4K Stars,550 Forks,140 Issues&PRs,獲得廣泛好評,此外關注仍在持續增長中:此外,HuggingFace Space、Papers code 連續一週榜一,近日登頂HuggingFace所有主題排行榜榜一| : 

| 🎝
Papers with code榜一
|
HuggingFace所有主題排行榜一
🎜🎜🎜🎜Untuk maklumat sumber lanjut, anda boleh melihat:
- Alamat kod: https://github.com/KwaiVGI/LivePortrait
- pautan: https://github.com/LivePortrait
- abs /2407.03168
- Laman utama projek: https://liveportrait.github.io/
HuggingFace Space pengalaman dalam talian satu klik: https://huggingface.co/spaces/KwaiVGI/LivePortrait
Apakah jenis teknologi yang digunakan LivePortrait untuk cepat menjadi popular di seluruh Internet?
Pengenalan Kaedah
Berbeza daripada kaedah berasaskan model resapan arus perdana, LivePortrait meneroka dan mengembangkan potensi kerangka kerja implisit kebolehcapaian yang berpotensi. LivePortrait memfokuskan pada generalisasi, kebolehkawalan dan kecekapan praktikal yang lebih baik. Untuk meningkatkan keupayaan penjanaan dan kebolehkawalan, LivePortrait menggunakan bingkai latihan berkualiti tinggi 69M, strategi latihan hibrid gambar video, menaik taraf struktur rangkaian dan mereka bentuk pemodelan tindakan dan kaedah pengoptimuman yang lebih baik. Selain itu, LivePortrait menganggap perkara utama tersirat sebagai gambaran tersirat yang berkesan bagi ubah bentuk campuran muka (Blendshape), dan dengan berhati-hati mencadangkan modul jahitan dan penyasaran semula berdasarkan perkara ini. Kedua-dua modul ini adalah rangkaian MLP yang ringan, jadi sambil meningkatkan kebolehkawalan, kos pengiraan boleh diabaikan. Walaupun dibandingkan dengan beberapa kaedah berasaskan model penyebaran sedia ada, LivePortrait masih sangat berkesan. Pada masa yang sama, pada GPU RTX4090, kelajuan penjanaan bingkai tunggal LivePortrait boleh mencapai 12.8ms Jika terus dioptimumkan, seperti TensorRT, ia dijangka mencapai kurang daripada 10ms.
Latihan model LivePortrait dibahagikan kepada dua peringkat. Peringkat pertama ialah latihan model asas, dan peringkat kedua ialah latihan modul pemasangan dan pengalihan.
Peringkat pertama latihan model asas

🎜🎜模 Peringkat pertama latihan model asas
Dalam latihan model fasa pertama, LivePortrait telah membuat satu siri penambahbaikan pada rangka kerja berasaskan titik tersembunyi, seperti Face vid2vid [1], termasuk:
Pengumpulan data latihan berkualiti tinggi: LivePortrait menggunakan set data video awam Voxceleb[2], MEAD[3], RAVDESS[4] dan set data gambar yang digayakan AAHQ[5]. Selain itu, video potret beresolusi 4K berskala besar digunakan, termasuk ekspresi dan postur yang berbeza, lebih daripada 200 jam video potret bercakap, set data peribadi LightStage [6] dan beberapa video dan gambar yang digayakan. LivePortrait membahagikan video panjang kepada segmen kurang daripada 30 saat dan memastikan setiap segmen hanya mengandungi satu orang. Untuk memastikan kualiti data latihan, LivePortrait menggunakan KVQ yang dibangunkan sendiri oleh Kuaishou [7] (kaedah penilaian kualiti video yang dibangunkan sendiri oleh Kuaishou, yang boleh melihat secara menyeluruh kualiti, kandungan, pemandangan, estetika, pengekodan, audio dan ciri-ciri lain bagi video untuk melaksanakan penilaian berbilang dimensi ) untuk menapis klip video berkualiti rendah. Jumlah data latihan termasuk 69J video, termasuk 18.9K identiti dan 60K potret bergaya statik.
Latihan Hibrid Imej-Video: Model yang dilatih menggunakan hanya video orang sebenar menunjukkan prestasi yang baik untuk orang sebenar, tetapi mempunyai keupayaan generalisasi yang tidak mencukupi untuk orang yang digayakan (seperti anime). Video potret bergaya adalah lebih jarang, dengan LivePortrait hanya mengumpul kira-kira 1.3K klip video daripada kurang daripada 100 identiti. Sebaliknya, gambar potret yang digayakan berkualiti tinggi lebih banyak LivePortrait telah mengumpulkan kira-kira 60K gambar dengan identiti yang berbeza, memberikan maklumat identiti yang pelbagai. Untuk memanfaatkan kedua-dua jenis data, LivePortrait menganggap setiap imej sebagai klip video dan melatih model pada kedua-dua video dan imej secara serentak. Latihan hibrid ini meningkatkan keupayaan generalisasi model.
Struktur rangkaian yang dipertingkatkan: LivePortrait menyatukan rangkaian anggaran titik kunci tersirat kanonik (L), rangkaian anggaran pose kepala (H) dan rangkaian anggaran ubah bentuk ungkapan (Δ) ke dalam model tunggal (M), Dan menggunakan ConvNeXt-V2-Tiny[8] sebagai strukturnya untuk menganggarkan secara langsung titik utama tersirat kanonik, pose kepala dan ubah bentuk ekspresi imej input. Selain itu, diilhamkan oleh kerja berkaitan face vid2vid, LivePortrait menggunakan penyahkod SPADE [9] yang lebih berkesan sebagai penjana (G). Ciri terpendam (fs) dimasukkan secara halus ke dalam penyahkod SPADE selepas ubah bentuk, di mana setiap saluran ciri terpendam digunakan sebagai peta semantik untuk menjana imej yang didorong. Untuk meningkatkan kecekapan, LivePortrait turut memasukkan lapisan PixelShuffle[10] sebagai lapisan terakhir (G), sekali gus meningkatkan peleraian daripada 256 kepada 512.
Pemodelan transformasi tindakan yang lebih fleksibel: Kaedah pengiraan dan pemodelan bagi perkara utama tersirat asal mengabaikan pekali penskalaan, yang menyebabkan penskalaan mudah dipelajari ke dalam pekali ekspresi, menjadikan latihan lebih sukar. Untuk menyelesaikan masalah ini, LivePortrait memperkenalkan faktor penskalaan ke dalam pemodelan. LivePortrait mendapati bahawa penskalaan unjuran biasa boleh membawa kepada pekali ekspresi boleh dipelajari yang terlalu fleksibel, menyebabkan lekatan tekstur apabila didorong merentas identiti. Oleh itu, transformasi yang diterima pakai oleh LivePortrait adalah kompromi antara fleksibiliti dan kebolehpanduan. . Khususnya, arah bola mata dan orientasi kepala potret dalam hasil pemanduan cenderung kekal selari. LivePortrait mengaitkan had ini kepada kesukaran pembelajaran ekspresi muka halus tanpa pengawasan. Untuk menyelesaikan masalah ini, LivePortrait memperkenalkan titik kekunci 2D untuk menangkap ekspresi mikro, menggunakan kehilangan berpandukan titik kunci (Lguide) sebagai panduan untuk pengoptimuman titik kunci tersirat.
: LivePortrait menggunakan kehilangan invarian mata utama vid2vid tersirat (LE), kehilangan sebelum mata utama (LL), kehilangan pose kepala (LH) dan kehilangan sebelum ubah bentuk (LΔ). Untuk meningkatkan lagi kualiti tekstur, LivePortrait menggunakan kehilangan persepsi dan GAN, yang bukan sahaja digunakan pada domain global imej input, tetapi juga pada domain tempatan muka dan mulut, direkodkan sebagai kehilangan persepsi lata (LP, lata) dan lata GAN (LG, lata). Kawasan muka dan mulut ditakrifkan oleh titik kekunci semantik 2D. LivePortrait juga menggunakan kehilangan identiti muka (Lfaceid) untuk mengekalkan identiti imej rujukan.
Semua modul dalam peringkat pertama dilatih dari awal, dan jumlah fungsi pengoptimuman latihan (Lbase) ialah jumlah wajaran syarat kerugian di atas. Latihan modul pemasangan dan ubah hala peringkat kedua kos pengiraan boleh diabaikan. Mengambil kira keperluan sebenar, LivePortrait mereka bentuk modul yang sesuai, modul ubah hala mata dan modul ubah hala mulut.Apabila potret rujukan dipangkas, potret yang didorong akan ditampal kembali ke ruang imej asal dari ruang pangkas Modul pemasangan ditambah untuk mengelakkan salah jajaran piksel semasa proses menampal, seperti kawasan bahu. Akibatnya, LivePortrait boleh dipacu tindakan untuk saiz gambar yang lebih besar atau foto kumpulan. Modul penyasaran semula mata direka untuk menyelesaikan masalah penutupan mata yang tidak lengkap apabila memandu merentasi identiti, terutamanya apabila potret dengan mata kecil memandu potret dengan mata besar. Idea reka bentuk modul ubah hala mulut adalah serupa dengan modul ubah hala mata Ia menormalkan input dengan memacu mulut gambar rujukan ke dalam keadaan tertutup untuk pemanduan yang lebih baik. Fasa kedua latihan model: sesuaikan dan ubah hala latihan modul 
Ikuti modul : Semasa proses latihan, input modul (s) ialah rajah rujukan Titik kekunci tersirat (xs) dan titik kekunci tersirat (xd) bingkai terdorong identiti lain dan menganggarkan perubahan ungkapan (Δst) memacu titik kekunci tersirat (xd). Dapat dilihat bahawa, tidak seperti peringkat pertama, LivePortrait menggunakan tindakan silang identiti untuk menggantikan tindakan identiti yang sama untuk meningkatkan kesukaran latihan, bertujuan untuk menjadikan modul yang sesuai mempunyai generalisasi yang lebih baik. Seterusnya, titik kunci tersirat pemacu (xd) dikemas kini, dan output pemacu yang sepadan ialah (Ip,st). LivePortrait juga mengeluarkan imej yang dibina semula sendiri (Ip,recon) pada peringkat ini. Akhir sekali, fungsi kehilangan modul pemasangan (Lst) mengira kehilangan konsisten piksel bagi kawasan bahu kedua-dua bahu dan kehilangan regularisasi variasi pemasangan. Modul ubah hala mata dan mulut: Input modul ubah hala mata (Reyes) ialah titik kunci tersirat imej rujukan (xs), tuple keadaan bukaan mata imej rujukan dan rawak Pekali bukaan mata memandu ialah digunakan untuk menganggarkan perubahan ubah bentuk (Δmata) titik utama pemanduan. Tuple keadaan pembukaan mata mewakili nisbah bukaan mata, dan semakin besar, semakin tinggi tahap pembukaan mata. Begitu juga, input modul ubah hala mulut (Rlip) ialah titik kunci tersirat (xs) imej rujukan, pekali keadaan pembukaan mulut imej rujukan dan pekali pembukaan mulut pemanduan rawak, dan titik kunci pemanduan dianggarkan daripada ini Jumlah perubahan (Δlip). Seterusnya, titik utama pemanduan (xd) dikemas kini oleh perubahan ubah bentuk yang sepadan dengan mata dan mulut masing-masing, dan output pemanduan yang sepadan ialah (Ip,mata) dan (Ip,bibir). Akhir sekali, fungsi objektif modul penargetan semula mata dan mulut ialah (Leyes) dan (Llip), yang mengira kehilangan ketekalan piksel kawasan mata dan mulut, kehilangan regularisasi variasi mata dan mulut, dan kehilangan rawak. Kehilangan antara pekali pemacu dan pekali keadaan pembukaan output pemacu. Perubahan mata dan mulut (Δmata) dan (Δbibir) adalah bebas antara satu sama lain, jadi semasa fasa inferens ia boleh dijumlahkan secara linear dan titik kekunci tersirat pemanduan dikemas kini. Pemandu identiti yang sama : Daripada hasil perbandingan pemacu identiti yang sama di atas, dapat dilihat bahawa dibandingkan dengan model bukan resapan model sedia ada kaedah berasaskan, LivePortrait Dengan kualiti penjanaan yang lebih baik dan ketepatan pemanduan, ia boleh menangkap ekspresi halus bingkai pemanduan mata dan mulut sambil mengekalkan tekstur dan identiti imej rujukan. Walaupun dalam postur kepala yang lebih besar, LivePortrait mempunyai prestasi yang lebih stabil.
: Daripada hasil perbandingan pemacu identiti yang sama di atas, dapat dilihat bahawa dibandingkan dengan model bukan resapan model sedia ada kaedah berasaskan, LivePortrait Dengan kualiti penjanaan yang lebih baik dan ketepatan pemanduan, ia boleh menangkap ekspresi halus bingkai pemanduan mata dan mulut sambil mengekalkan tekstur dan identiti imej rujukan. Walaupun dalam postur kepala yang lebih besar, LivePortrait mempunyai prestasi yang lebih stabil.

Pemandu silang identiti: Seperti yang dapat dilihat daripada hasil perbandingan pemandu identiti silang di atas, berbanding dengan kaedah sedia ada, LivePortrait boleh mewarisi pergerakan mata dan mulut yang halus dengan tepat dalam video pemandu, dan juga agak stabil apabila postur adalah besar. LivePortrait adalah lebih lemah sedikit daripada kaedah berasaskan model penyebaran AniPortrait [11] dari segi kualiti penjanaan, tetapi berbanding dengan yang terakhir, LivePortrait mempunyai kecekapan inferens yang sangat pantas dan memerlukan FLOP yang lebih sedikit. : LivePortrait bukan sahaja mempunyai generalisasi yang baik untuk potret, tetapi juga boleh didorong dengan tepat untuk potret haiwan selepas penalaan halus pada set data haiwan. 
🎜Suntingan video potret: Selain foto potret, diberikan video potret, seperti video tarian, LivePortrait boleh menggunakan video pemanduan untuk melakukan pengeditan gerakan pada kawasan kepala. Terima kasih kepada modul yang sesuai, LivePortrait boleh mengedit pergerakan di kawasan kepala dengan tepat, seperti ekspresi, postur, dsb., tanpa menjejaskan imej di kawasan bukan kepala.  Perkara teknikal berkaitan LivePortrait telah dilaksanakan dalam banyak perniagaan Kuaishou, termasuk jam tangan Kuaishoutic, Kuaishoutic dan permainan peribadi siaran langsung ishou, dan APP Puchi untuk golongan muda yang diinkubasi oleh Kuaishou, dsb., dan akan meneroka kaedah pelaksanaan baharu untuk terus mencipta nilai untuk pengguna. Selain itu, LivePortrait akan meneroka lebih lanjut penjanaan video potret dipacu pelbagai mod berdasarkan model asas Keling untuk mengejar kesan berkualiti tinggi. Rujukan . , Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, dan Chen Change Loy: Set data audio-visual berskala besar untuk penjanaan emosi bercakap-wajah, 2020. [4] Steven R Livingstone dan Frank A Russo Pangkalan data audio-visual ryerson pertuturan dan lagu (ravdess): Satu set ekspresi wajah dan vokal yang dinamik dalam bahasa inggeris Amerika Utara, 2018 [5] Mingcong Liu, Qiang Li, Zekui Qin, Guoxin Zhang, Pengfei Wan, dan Wen Zheng: Pengadunan secara tersirat untuk penjanaan wajah yang digayakan sewenang-wenangnya, 2021.. ] Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, dan Chongyang Ma Ke arah penangkapan praktikal avatar yang boleh diterangi kesetiaan tinggi Di SIGGRAPH Asia, 2023.. [7] Kai Zhao, Kun Yuan, Ming Sun, Mading Li dan Xing Wen model pra-latihan sedar kualiti untuk kualiti imej butapenilaian dalam CVPR, 2023.. 8] Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon dan Saining Xie-vnext v2: Reka bentuk bersama dan penskalaan convnet dengan pengekod auto23PR .[9] Taesung Park, Ming-Yu Liu, Ting-Chun Wang dan Jun-Yan Zhu sintesis imej semantik dengan penyesuaian spatial dalam CVPR, 2019.. 10] Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, dan Zehan Wang peleraian super imej dan video masa nyata menggunakan rangkaian saraf konvolusi subpiksel yang cekap. Dalam CVPR, 2016.[11] Huawei Wei, Zejun Yang dan Zhisheng Wang: Sintesis dipacu audio bagi animasi potret realistik arXiv:2403.17694, 2024.
Perkara teknikal berkaitan LivePortrait telah dilaksanakan dalam banyak perniagaan Kuaishou, termasuk jam tangan Kuaishoutic, Kuaishoutic dan permainan peribadi siaran langsung ishou, dan APP Puchi untuk golongan muda yang diinkubasi oleh Kuaishou, dsb., dan akan meneroka kaedah pelaksanaan baharu untuk terus mencipta nilai untuk pengguna. Selain itu, LivePortrait akan meneroka lebih lanjut penjanaan video potret dipacu pelbagai mod berdasarkan model asas Keling untuk mengejar kesan berkualiti tinggi. Rujukan . , Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, dan Chen Change Loy: Set data audio-visual berskala besar untuk penjanaan emosi bercakap-wajah, 2020. [4] Steven R Livingstone dan Frank A Russo Pangkalan data audio-visual ryerson pertuturan dan lagu (ravdess): Satu set ekspresi wajah dan vokal yang dinamik dalam bahasa inggeris Amerika Utara, 2018 [5] Mingcong Liu, Qiang Li, Zekui Qin, Guoxin Zhang, Pengfei Wan, dan Wen Zheng: Pengadunan secara tersirat untuk penjanaan wajah yang digayakan sewenang-wenangnya, 2021.. ] Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, dan Chongyang Ma Ke arah penangkapan praktikal avatar yang boleh diterangi kesetiaan tinggi Di SIGGRAPH Asia, 2023.. [7] Kai Zhao, Kun Yuan, Ming Sun, Mading Li dan Xing Wen model pra-latihan sedar kualiti untuk kualiti imej butapenilaian dalam CVPR, 2023.. 8] Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon dan Saining Xie-vnext v2: Reka bentuk bersama dan penskalaan convnet dengan pengekod auto23PR .[9] Taesung Park, Ming-Yu Liu, Ting-Chun Wang dan Jun-Yan Zhu sintesis imej semantik dengan penyesuaian spatial dalam CVPR, 2019.. 10] Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, dan Zehan Wang peleraian super imej dan video masa nyata menggunakan rangkaian saraf konvolusi subpiksel yang cekap. Dalam CVPR, 2016.[11] Huawei Wei, Zejun Yang dan Zhisheng Wang: Sintesis dipacu audio bagi animasi potret realistik arXiv:2403.17694, 2024.以上是快手開源LivePortrait,GitHub 6.6K Star,實現表情姿態極速遷移的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 還親自體驗了功能,厲害了!
還親自體驗了功能,厲害了!