
LLama+Mistral+…+Yi=? 免訓練異構大模型整合學習架構DeePEn來了

- 王林原創
- 2024-07-19 17:10:501284瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com


- 論文地址:https://arxiv.org/abs/2404.12715
- 🜟地址
方法介紹

,DeePEn 計算詞表中每個 token 與錨點 token 的嵌入相似度,得到相對錶示矩陣

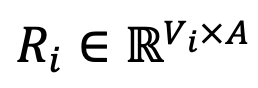
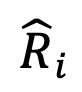
相對錶示融合
在每個解碼步驟中,一旦模型輸出機率分佈

 其中
其中 是模型的協作權重。作者嘗試了兩種確定協作權重值的方法:(1) DeePEn-Avg,對所有模型使用相同的權重;(2) DeePEn-Adapt,根據各個模型的驗證集性能成比例地為每個模型設定權重。
是模型的協作權重。作者嘗試了兩種確定協作權重值的方法:(1) DeePEn-Avg,對所有模型使用相同的權重;(2) DeePEn-Adapt,根據各個模型的驗證集性能成比例地為每個模型設定權重。

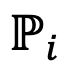 表示模型的絕對空間,
表示模型的絕對空間,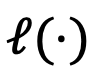 是衡量相對錶示之間距離的損失函數(KL 散度)。
是衡量相對錶示之間距離的損失函數(KL 散度)。  相對於絕對表示
相對於絕對表示 的梯度來指導搜尋過程,並迭代地進行搜尋。具體來說,DeePEn 將搜尋的起始點
的梯度來指導搜尋過程,並迭代地進行搜尋。具體來說,DeePEn 將搜尋的起始點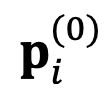 初始化為主模型的原始絕對表示,並進行更新:
初始化為主模型的原始絕對表示,並進行更新:
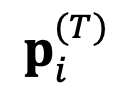 來決定下一步輸出的 token。
來決定下一步輸出的 token。 
。如表 1 所示,不同大模型在不同資料集上的表現有顯著差異。例如 LLaMA2-13B 在知識問答 TriviaQA 和 NQ 資料集上取得了最高的結果,但是其他四個任務上的排名並未進入前四名。
分佈融合在各個資料集上取得了一致性的提升 。如表 1 所示,DeePEn-Avg 和 DeePEn-Adapt 在所有資料集上均取得了效能提升。在 GSM8K 上,透過與投票法組合使用,最終取得了 + 11.35 的效能提升。
。如表 1 所示,DeePEn-Avg 和 DeePEn-Adapt 在所有資料集上均取得了效能提升。在 GSM8K 上,透過與投票法組合使用,最終取得了 + 11.35 的效能提升。
隨著整合模型數量的增加,整合效能先增後減 。作者在根據模型性能由高到低,依次將模型加入集成,然後觀察性能變化。如表 2 所示,不斷引入性能較差的模型,集成性能先增後減。
。作者在根據模型性能由高到低,依次將模型加入集成,然後觀察性能變化。如表 2 所示,不斷引入性能較差的模型,集成性能先增後減。
。作者也在機器翻譯任務上整合大模型 LLaMA2-13B 和多語言翻譯模型 NLLB 。如表 3 所示,通用大模型與任務特定的專家模型之間的集成,可顯著提升效能。
以上是LLama+Mistral+…+Yi=? 免訓練異構大模型整合學習架構DeePEn來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn