
拋棄視覺編碼器,這個「原生版」多模態大模型也能媲美主流方法

- WBOY原創
- 2024-07-18 19:21:11371瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
一作刁海文,是大連理工大學博士生,導師是盧湖教授。目前在北京智源人工智慧研究院實習,指導教師是王鑫龍博士。他的研究興趣是視覺與語言,大模型高效遷移,多模態大模型等。共同一作崔玉峰,畢業於北京航空航天大學,是北京智源人工智慧研究院視覺中心演算法研究員。他的研究興趣是多模態模型、生成模型和電腦視覺,主要工作有 Emu 系列。
近期,關於多模態大模型的研究如火如荼,工業界對此的投入也越來越多。國外相繼推出了炙手可熱的模型,例如 GPT-4o (OpenAI)、Gemini(Google)、Phi-3V (Microsoft)、Claude-3V(Anthropic),以及 Grok-1.5V(xAI)等。同時,國內的GLM-4V(智譜AI)、Step-1.5V(階躍星辰)、Emu2(北京智源)、Intern-VL(上海AI 實驗室)、Qwen-VL(阿里巴巴)等模型百花齊放。
目前的視覺語言模型(VLM)通常依賴視覺編碼器(Vision Encoder, VE)來提取視覺特徵,再結合使用者指令傳入大語言模型(LLM)進行處理和回答,主要挑戰在於視覺編碼器和大語言模型的訓練分離。這種分離導致視覺編碼器在與大語言模型對接時引入了視覺歸納偏置問題,例如受限的影像解析度和縱橫比,以及強烈的視覺語義先驗。隨著視覺編碼器容量的不斷擴大,多模態大模型在處理視覺訊號時的部署效率也受到極大限制。此外,如何找到視覺編碼器和大語言模型的最佳容量配置,也變得越來越具有複雜性和挑戰性。
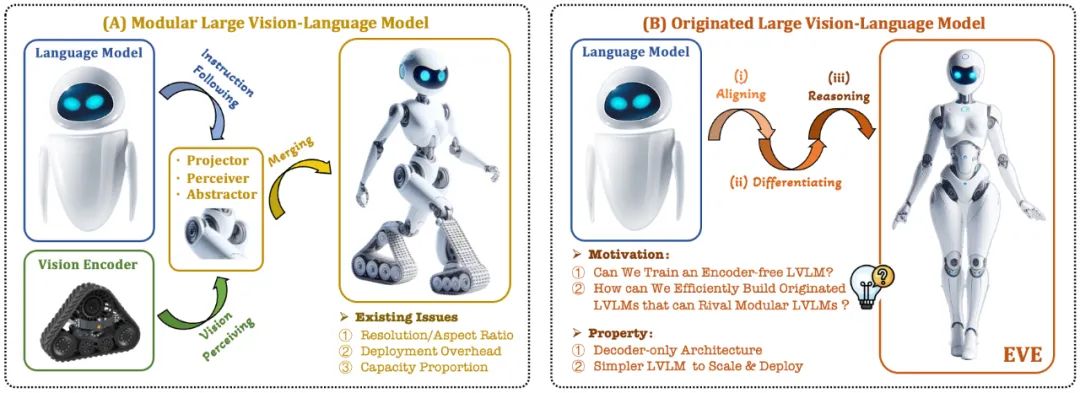
在此背景下,一些更前沿的構想迅速浮現:
能否去除視覺編碼器,即直接構建無視覺編碼器的原生多模態大模型?
如何有效率且絲滑地將大語言模型演變為無視覺編碼器的原生多模態大模型?
如何彌合無編碼器的原生多模態框架和基於編碼器的主流多模態範式的效能差距?
Adept AI 在 2023 年末發布了 Fuyu 系列模型並做出了一些相關嘗試,但在訓練策略、數據資源和設備資訊方面沒有任何披露。同時,Fuyu 模型在公開的視覺文字評測指標上與主流演算法存在顯著的表現差距。在同一時期,我們進行的一些先導試驗顯示,即使大規模拉升預訓練資料規模,無編碼器的原生多模態大模型仍面臨收斂速度慢和效能表現差等棘手問題。
針對這些挑戰,智源研究院視覺團隊聯合大連理工大學、北京大學等國內大學,推出了新一代無編碼器的視覺語言模型 EVE。透過精細化的訓練策略和額外的視覺監督,EVE 將視覺 - 語言表徵、對齊和推理整合到統一的純解碼器架構中。使用公開數據,EVE 在多個視覺 - 語言基準測試中表現出色,與類似容量的基於編碼器的主流多模態方法相媲美,並顯著優於同類型 Fuyu-8B。 EVE 的提出旨在為純解碼器的原生多模態架構發展提供一條透明且高效的路徑。


論文地址: https://arxiv.org/abs/2406.11832
- 🜎 https ://huggingface.co/BAAI/EVE-7B-HD-v1.0
- 1. 技術亮點
原生視覺語言模型:打破了主流的多模態模型的固定範式,去除視覺編碼器,可處理任意影像長寬比。在多個視覺語言基準測試中顯著優於同類型的 Fuyu-8B 模型,並接近主流的基於視覺編碼器的視覺語言架構。
數據和訓練代價少: EVE 模型的預訓練僅篩選了來自OpenImages、SAM 和LAION 的公開數據,並利用了66.5 萬條LLaVA 指令數據和額外的120 萬條視覺對話數據,分別構建了常規版本和高分辨版本的EVE-7B。訓練在兩個 8-A100 (40G) 節點上約 9 天完成,或在四個 8-A100 節點上約 5 天完成。
透明和高效的探索: EVE 嘗試探索一條高效、透明且實用的路徑通往原生視覺語言模型,為開發新一代純解碼器的視覺語言模型架構提供全新的思路和寶貴的經驗,為未來多模態模型的發展開啟新的探索方向。
2. 模型結構
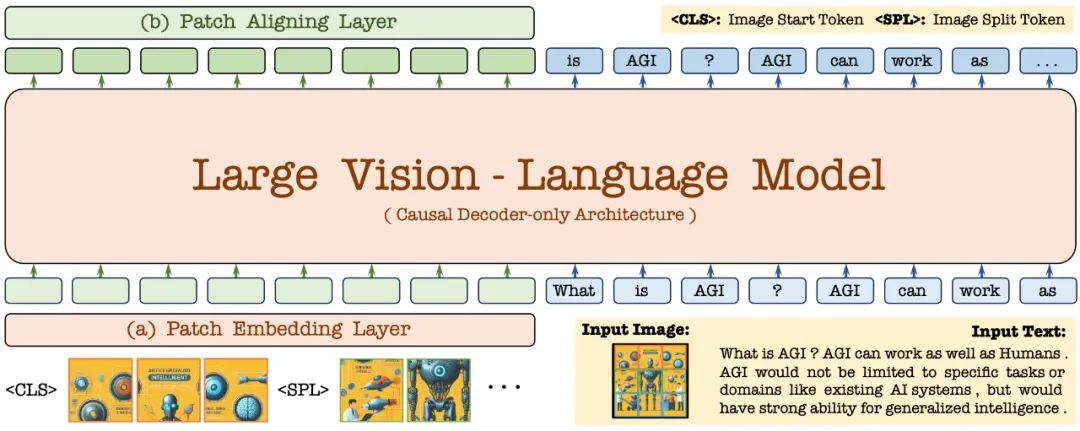
首先,透過 Vicuna-7B 語言模型進行初始化,使其具備豐富的語言知識和強大的指令跟隨能力。在此基礎上,去除深度視覺編碼器,建立輕量級視覺編碼層,高效無損地編碼影像輸入,並將其與使用者語言命令輸入到統一的解碼器中。此外,透過視覺對齊層與通用的視覺編碼器進行特徵對齊,強化細粒度的視覺資訊編碼和表徵。
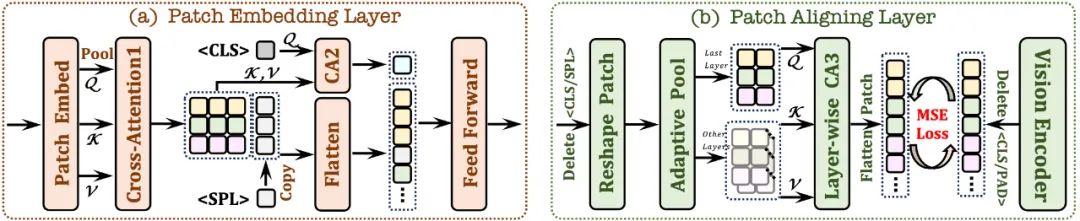
2.1 Patch Embedding Layer
首先使用單層卷積層來獲取影像的2D 特徵圖,然後透過平均池化層進行下取樣;
- 1在限定感受野中交互,增強每個 patch 的局部特徵;
-
使用
token 並結合交叉注意力模組(CA2),為後續每個patch 特徵提供全局信息; 在每個patch 特徵提供全局信息;
在每個patch 特徵行的末尾插入了一個可學習的
token,幫助網路理解圖像的二維空間結構。2.2 Patch Aligning Layer
- 記錄有效patch 的二維形狀;丟棄
/
tokens,並利用自適應池化層還原到原始的二維形狀;/ tokens,並利用自適應池化層還原到原始的二維形狀;模組(CA3),整合多層網路視覺特徵,從而實現與視覺編碼器輸出的細粒度對齊。
3. 訓練策略
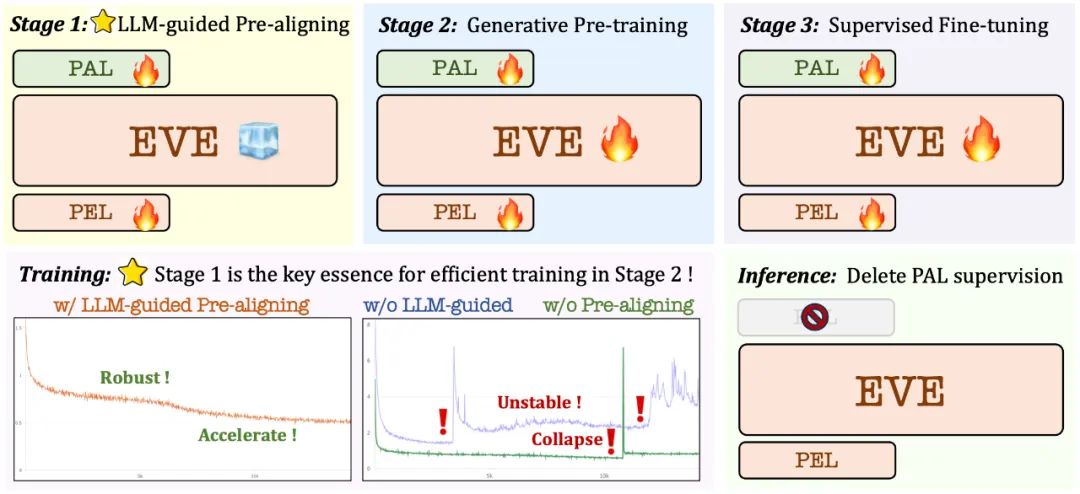
- 大語言模型引導的預訓練階段:建立視覺和語言之間的初步聯繫,為後續穩定的大規模預打基礎;
生成式預訓練階段:進一步提高模型對視覺- 語言內容的理解能力,實現純語言模型到多模態模型的絲滑轉變;
監督式的微調階段:進一步規範模型遵循語言指令和學習對話模式的能力,滿足各種視覺語言基準測試的要求。

在預訓練階段,篩選了來自 SA-1B、OpenImages 和 LAION 等 3300 萬公開數據,僅保留分辨率高於 448×448 的圖像樣本。特別地,針對LAION 影像冗餘度高的問題,透過在EVA-CLIP 擷取的影像特徵上應用K-means 聚類,產生50,000 個聚類,並從中挑選出最接近每個聚類中心的300 張圖像,最終選出1500 萬張LAION 圖像樣本。隨後,利用 Emu2 (17B)和 LLaVA-1.5 (13B)重新產生高品質影像描述。
在監督微調階段,使用LLaVA-mix-665K 微調資料集來訓練得到標準版的EVE-7B,並整合AI2D、Synthdog、DVQA、ChartQA、DocVQA、Vision-Flan 和Bunny-695K 等混合資料集來訓練得到高解析度版本的EVE-7B。
4. 定量分析
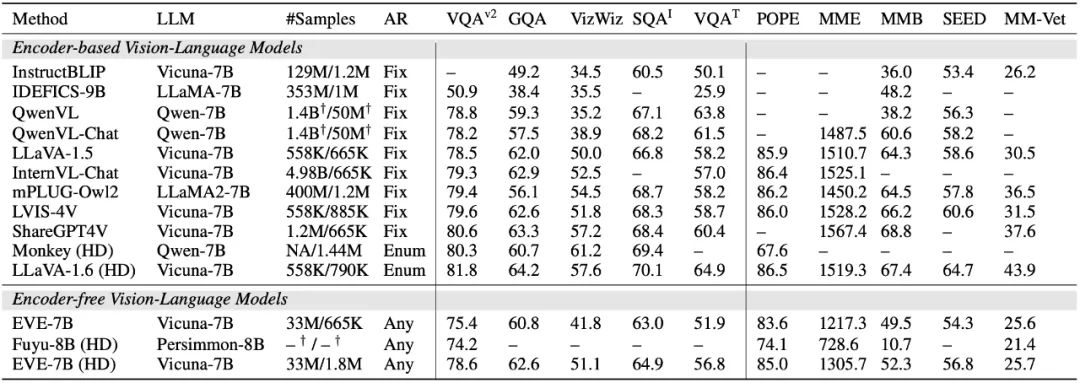
EVE 模型在多個視覺語言基準測試中明顯優於同類型的 Fuyu-8B 模型,並且與多種主流的基於編碼器的視覺語言模型表現相當。然而,由於使用大量視覺語言資料訓練,其在準確響應特定指令方面存在挑戰,在部分基準測試中表現有待提高。令人興奮的是,透過高效的訓練策略,可以實現無編碼器的EVE 與帶有編碼器基礎的視覺語言模型取得相當的性能,從根本上解決主流模型在輸入尺寸靈活性、部署效率和模態容量匹配方面的問題。
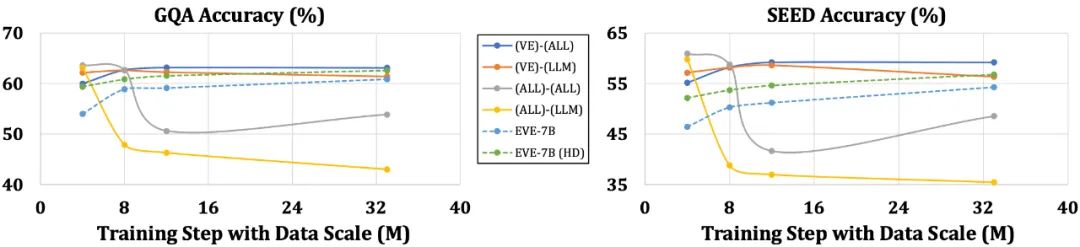
相較於帶編碼器的模型易受到語言結構簡化和豐富知識丟失等問題困擾,EVE 表現出隨著數據規模的增加而逐步穩定地提升性能,逐漸逼近基於編碼器模型的性能水平。這可能是因為在統一網路中編碼和對齊視覺和語言模態更具挑戰性,使得無編碼器模型相對於編碼器的模型更不容易過度擬合。
5. 同行怎麼看?
英偉達高級研究員 Ali Hatamizadeh 表示,EVE 令人耳目一新,嘗試提出全新的敘事,區別於構建繁雜的評測標準和漸進式的視覺語言模型改進。

谷歌 Deepmind 首席研究員 Armand Joulin 表示,建造純解碼器的視覺語言模型令人興奮。

蘋果機器學習工程師 Prince Canuma 表示,EVE 架構非常有趣,對 MLX VLM 專案集是一個很好的補充。

6.未來展望
作為無編碼器的原生視覺語言模型,目前 EVE 取得了令人鼓舞的結果。沿著這條路徑,未來還有一些有趣的方向值得探索嘗試:
進一步的性能提升:實驗發現,僅使用視覺- 語言數據進行預訓練顯著地降低了模型的語言能力(SQA 得分從65.3% 降至63.0%),但逐步提升了模型的多模態性能。這顯示在大語言模型更新時,內部存在語言知識的災難性遺忘。建議適當融合純語言的預訓練數據,或採用專家混合(MoE)策略來減少視覺與語言模態間幹擾。
無編碼器架構的暢想:透過恰當策略和高品質資料的訓練,無編碼器視覺語言模型可以與帶編碼器的模型相匹敵。那麼在相同的模型容量和海量的訓練資料下,二者表現如何?我們推定透過擴大模型容量和訓練資料量,無編碼器架構是能夠達到甚至超越基於編碼器架構,因為前者幾乎無損地輸入影像,避開了視覺編碼器的先驗偏移。
原生多模態的構建: EVE 完整地展現瞭如何高效穩定地構建原生多模態模型,這為之後整合更多模態(如音頻、視頻、熱成像、深度等)開闢了透明和切實可行的道路。核心思想是在引入大規模統一訓練之前,先透過凍結的大語言模型對這些模態進行預對齊,並利用相應的單模態編碼器和語言概念對齊進行監督。
以上是拋棄視覺編碼器,這個「原生版」多模態大模型也能媲美主流方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!