
大模型推理效率無損提升3倍,滑鐵盧大學、北京大學等機構發表EAGLE

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-18 14:43:481027瀏覽

技術報告:https://sites.google.com/view/eagle-llm 程式碼(支援商用Apache 2.0):https://github.com/LE
EAGLE 具有以下特點:
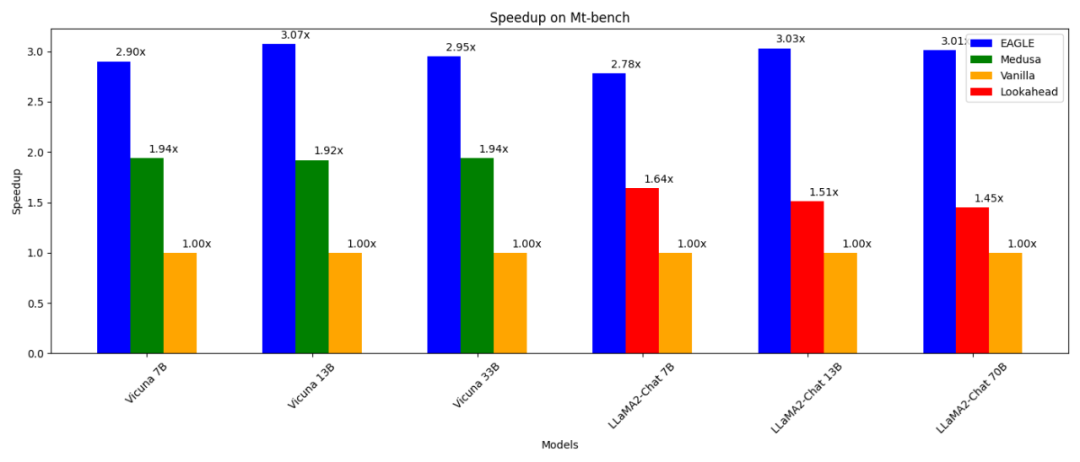
- 比普通自回歸解碼(13B)快3 倍;
比普通自回歸解碼(13B)快3 倍;比;解碼(13B)快1.6 倍; 可以證明在生成文本的分佈上與普通解碼保持一致; -
可以在RTX 3090 上進行訓練(1-2 天內)和測試; 可以在RTX 3090 上進行訓練(1-2 月)和測試; 與vLLM、DeepSpeed、Mamba、FlashAttention、量化和硬體優化等其他平行技術結合使用。 - 加速自迴歸解碼的一種方法是投機取樣(speculative sampling)。這種技術使用一個較小的草稿模型,透過標準自迴歸產生來猜測接下來的多個字。隨後,原始 LLM 並行驗證這些猜測的字詞(只需要進行一次前向傳播進行驗證)。如果草稿模型準確預測了 α 詞,原始 LLM 的一次前向傳播就可以產生 α+1 個字。
 在投機採樣中,草稿模型的任務是基於當前詞序列預測下一個詞。使用一個參數數量顯著較少的模型完成這個任務極具挑戰性,通常會產生次優結果。此外,標準投機採樣方法中的草稿模型獨立預測下一個詞而不利用原始 LLM 提取的豐富語義訊息,導致潛在的效率低下。
在投機採樣中,草稿模型的任務是基於當前詞序列預測下一個詞。使用一個參數數量顯著較少的模型完成這個任務極具挑戰性,通常會產生次優結果。此外,標準投機採樣方法中的草稿模型獨立預測下一個詞而不利用原始 LLM 提取的豐富語義訊息,導致潛在的效率低下。 




以上是大模型推理效率無損提升3倍,滑鐵盧大學、北京大學等機構發表EAGLE的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn