
ICML 2024 | 梯度檢查點太慢?不降速、省顯存,LowMemoryBP大幅提升反向傳播顯存效率

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-18 01:39:51767瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文論文一作是南開大學統計與資料科學學院研二君生楊雨辰,指導老師為南開大學統計與資料科學學院的徐亞碩士。徐君老師團隊的研究重點是電腦視覺、生成式 AI 和高效機器學習,並在頂級會議和期刊上發表了多篇論文,谷歌學術引用超過 4700 次。
自從大型 Transformer 模型逐漸成為各個領域的統一架構,微調就成為了將預訓練大模型應用到下游任務的重要手段。然而,由於模型的尺寸日益增大,微調所需的顯存也逐漸增加,如何有效率地降低微調顯存就成了一個重要的問題。先前,微調Transformer 模型時,為了節省顯存開銷,通常的做法是使用梯度檢查點(gradient checkpointing,也叫作激活重算),以犧牲訓練速度為代價降低反向傳播(Backpropagation, BP)過程中的啟動顯存佔用。
最近,由南開大學統計與數據科學學院徐君老師團隊發表在ICML 2024 上的論文《Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation》提出透過更改反向傳播(BP)過程,在在不增加計算量的情況下,顯著減少峰值啟動顯存佔用。

論文:Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing-Sharing Backpropagation
論文連結:https :/ /github.com/yyyyychen/LowMemoryBP
文章提出了兩種反向傳播改善策略,分別是Approximate Backpropagation(Approx-BP)和Memory-Sharing Backpropagation(MS-BP)。 Approx-BP 和 MS-BP 分別代表了兩種提升反向傳播中記憶體效率的方案,可以統稱為 LowMemoryBP。無論是在理論或實務意義上,文章都對更有效率的反向傳播訓練提供了開創性的指導。
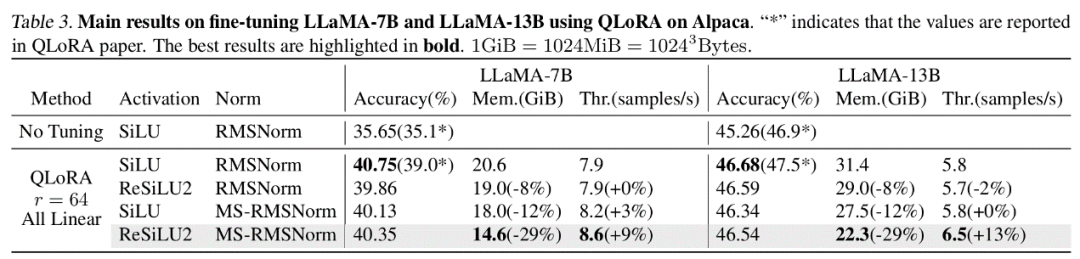
在理論顯存分析中,LowMemoryBP 可以大幅降低來自激活函數和標準化層的激活顯存佔用,以ViT 和LLaMA 為例,可以對ViT 微調降低39.47% 的激活顯存,可以對LLaMA 微調降低29.19% 的激活顯存。
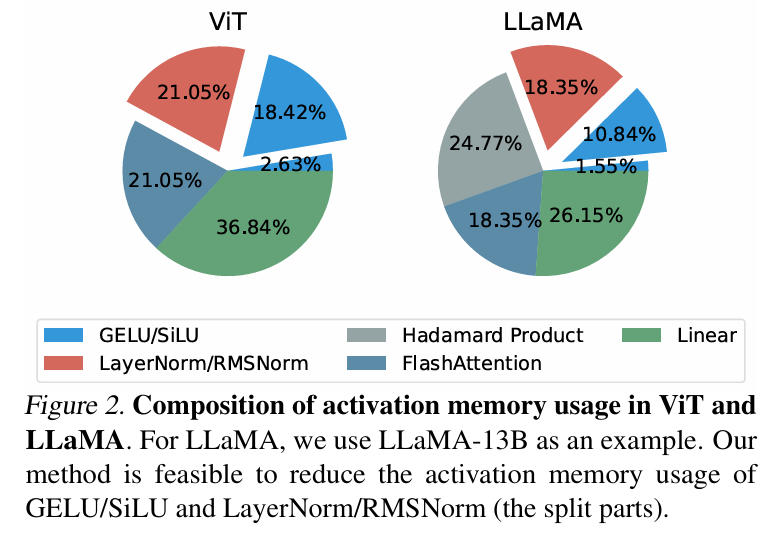
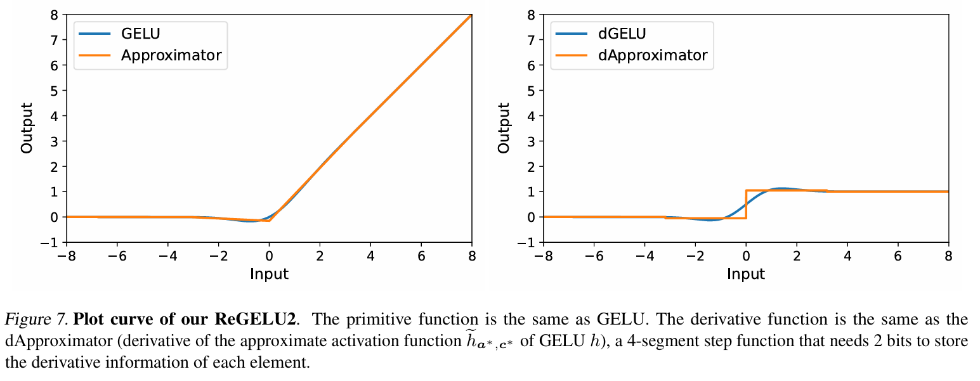
在傳統反向傳播訓練中,激活函數梯度的反向回傳是嚴格對應其導函數的,對於Transformer 模型中常用的GELU 和SiLU 函數,這意味著需要將輸入特徵張量完整存入激活顯存。而本文的作者提出了一套反向傳播近似理論,即 Approx-BP 理論。在理論的指導下,作者使用分段線性函數逼近活化函數,並以分段線性函數的導數(階梯函數)取代 GELU/SiLU 梯度的反向回傳。這個方法導出了兩個非對稱的記憶體高效激活函數:ReGELU2 和 ReSiLU2。這類啟動函數由於使用 4 段階梯函數進行反向回傳,使得啟動儲存只需要使用 2bit 資料型別。
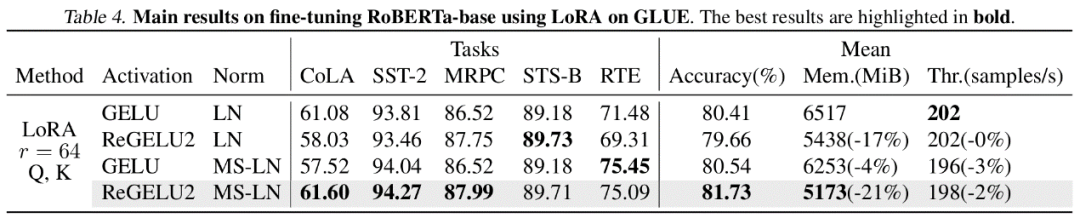
MS-BP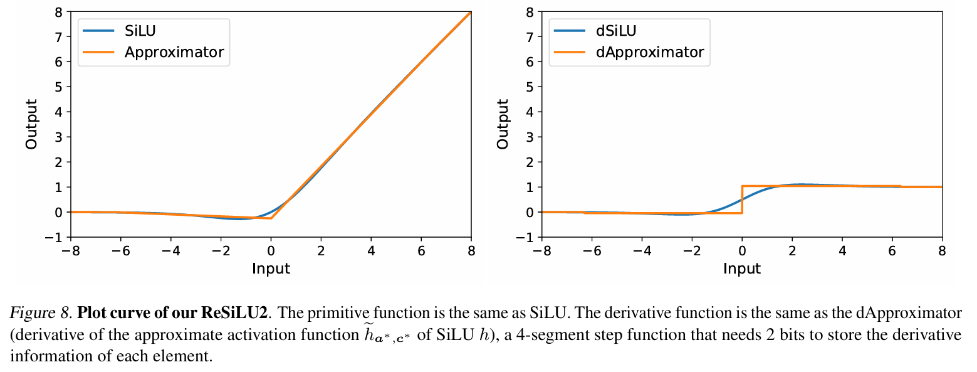
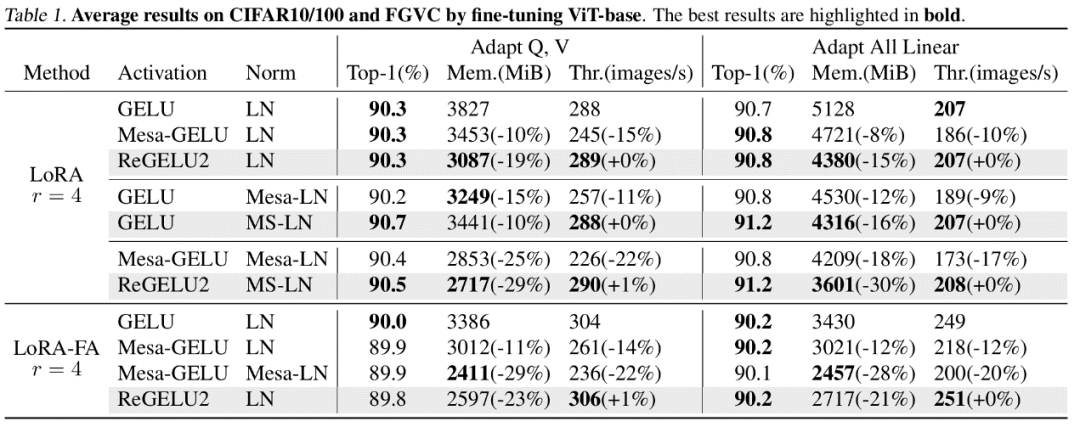
BP 網路每一層通常都會將輸入張量存入活化顯存以用作反向傳播計算。作者指出如果可以將某一層的反向傳播改寫成依賴輸出的形式,那麼這一層和後一層就可以共享同一個激活張量,從而降低激活存儲的冗餘。 而文章指出 Transformer 模型中常用的 LayerNorm 和 RMSNorm,在將仿射參數合併到後一層的線性層之後,可以很好地符合 MS-BP 策略的要求。經過重新設計的 MS-LayerNorm 和 MS-RMSNorm 不再產生獨立的活化記憶體。 實驗結果 作者對電腦視覺和自然語言處理領域的若干個代表模型進行了微調實驗。其中,在 ViT,LLaMA 和 RoBERTa 的微調實驗中,文章提出的方法分別將峰值顯存佔用降低了 27%,29% 和 21%,並且沒有帶來訓練效果和訓練速度的損失。注意到,作為對比的 Mesa(一個 8-bit Activation Compressed Training 方法)使訓練速度降低了約 20%,而文章提出的 LowMemoryBP 方法則完全保持了訓練速度。 結論及意義 文章提出的兩種BP 改進策略,Approx-BP 和MS-BP,均在保持訓練和改善速度的速度的顯著節省。這意味著從 BP 原理上進行最佳化是非常有前景的顯存節省方案。此外,文章提出的 Approx-BP 理論突破了傳統神經網路的最佳化框架,為使用非配對導數提供了理論可行性。其導出的 ReGELU2 和 ReSiLU2 展現了這項做法的重要實踐價值。 歡迎大家閱讀論文或程式碼去了解演算法的詳細細節,LowMemoryBP 專案的 github 倉庫上已經開源相關的模組。 
以上是ICML 2024 | 梯度檢查點太慢?不降速、省顯存,LowMemoryBP大幅提升反向傳播顯存效率的詳細內容。更多資訊請關注PHP中文網其他相關文章!