AI 已經在幫助數學家和科學家做研究了,比如著名數學家陶哲軒就曾多次分享自己借助 GPT 等 AI 工具研究探索的經歷。 AI 要在這些領域大戰拳腳,強大可靠的因果推理能力是不可或缺的。 本文要介紹的這項研究發現:在小圖譜的因果傳遞性公理演示上訓練的 Transformer 模型可以泛化用於大圖譜的傳遞性公理。 也就是說,如果讓 Transformer 學會執行簡單的因果推理,就可能將其用於更為複雜的因果推理。團隊提出的公理訓練框架是一種基於被動資料來學習因果推理的新範式,只有演示足夠就能用於學習任意公理。 引言(causal reasoning)可以定義成一組推理流程並且這組推理流程要符合專門針對因果性的預定義或公理規則。舉個例子,d-separation(有向分離)和 do-calculus 規則可被視為公理,而 collider set 或 backdoor set 的規範則可被看作是由公理推導出的規則。 通常來說,因果推理所使用的資料對應於一個系統中的變數。透過正規化、模型架構或特定的變數選擇,可以歸納偏移的形式將公理或規則整合到機器學習模型中。 根據可用資料種類的差異(觀察資料、介入資料、反事實資料),Judea Pearl 提出的「因果階梯」定義了因果推理的可能類型。 由於公理是因果性的基石,因此我們不禁會想是否可以直接使用機器學習模型來學習公理。也就是說,如果學習公理的方式不是學習透過某個資料產生流程所得到的數據,而是直接學習公理的符號演示(並由此學習因果推理),哪又會如何呢? 相較於使用特定的數據分佈構建的針對特定任務的因果模型,這樣的模型有一個優勢:其可在多種不同的下游場景中實現因果推理。隨著語言模型具備了學習以自然語言表達的符號資料的能力,這個問題也變得非常重要了。 事實上,近期已有一些研究透過創建以自然語言編碼因果推理問題的基準,評估了大型語言模型(LLM)是否能夠執行因果推理。 微軟、MIT 和印度理工學院海得拉巴分校(IIT Hyderabad)的研究團隊也朝這個方向邁出了重要一步:提出了一種透過公理訓練(axiomatic training)學習因果推理的方法。 
- 論文標題:Teaching Transformers Causal Reasoning through Axiomatic Training
-
論文地址:https://arxiv.org/pdf/2407.07612論文地址:https://arxiv.org/pdf/2407.07612
。
他們假設,因果公理可表示成以下符號元組〈premise, hypothesis, result”。其中 hypothesis 是指假設,即因果陳述;premise 是前提,是指用於確定該陳述是否為「真」的任意相關資訊;result 自然就是結果了。結果可以是簡單的“是”或“否”。 舉個例子,來自論文《Can large language models infer causation from correlation?》的 collider 公理可以表示成:
基於這個模板,可透過修改變數名稱、變數數量和變數順序等來產生大量合成元組。
為了用 Transformer 學習因果公理,實現公理訓練,該團隊採用了以下方法構建資料集、損失函數和位置嵌入。
Yes 或No)。要建立訓練資料集,團隊的做法是在特定的變數設定X、Y、Z、A 下列舉所有可能的元組{(P, H, L)}_N,其中P 是前提,H 是假設,L 是標籤(Yes 或No)。
給定一個基於某個因果圖譜的前提 P,如果可透過使用特定的公理(一次或多次)推導出假設 P,那麼標籤 L 就為 Yes;否則為 No。
舉個例子,假設一個系統的底層真實因果圖譜具有鍊式的拓撲結構:X_1 → X_2 → X_3 →・・・→ X_n。那麼,可能的前提是 X_1 → X_2 ∧ X_2 → X_3,那麼假設 X_1 → X_3 有標籤 Yes,而另一個假設 X_3 → X_1 有標籤 No。上述公理可被歸納式地多次用於產生更複雜的訓練元組。
對於訓練設置,使用傳遞性公理產生的 N 個公理實例建立一個合成資料集 D。 D 中的每個實例都建構成了 (P_i, H_ij, L_ij) 的形式,
,其中 n 是每第 i 個前提中的節點數。 P 是前提,即某種因果結構的自然語言表達(如 X 導致 Y,Y 導致 Z);之後是問題 H(如 X 導致 Y 嗎?);L 為標籤(Yes 或 No)。此形式能有效涵蓋給定因果圖譜中每條獨特鏈的所有成對節點。
損失函數
給定一個資料集,損失函數的定義基於每個元組的基本真值標籤,表示為:
分析表明,相比於下一同預測,使用該損失能得到很有希望的結果。
位置編碼
除了訓練和損失函數,位置編碼的選擇也是另一個重要因素。位置編碼能提供 token 在序列中絕對和相對位置的關鍵資訊。
著名論文《Attention is all you need》中提出了一種使用週期函數(正弦或餘弦函數)來初始化這些編碼的絕對位置編碼策略。
絕對位置編碼能為任何序列長度的所有位置提供確定的值。但是,有研究顯示絕對位置編碼難以應對 Transformer 的長度泛化任務。在可學習的 APE 變體中,每個位置嵌入都是隨機初始化的,並使用該模型完成了訓練。此方法難以應對比訓練時的序列更長的序列,因為新的位置嵌入仍未被訓練和初始化。
有趣的是,近期有發現表明移除自回歸模型中的位置嵌入可以提升模型的長度泛化能力,而自回歸解碼期間的注意力機制足以編碼位置資訊。該團隊使用了不同的位置編碼來理解其對因果任務中的泛化的影響,包括可學習位置編碼(LPE)、正弦位置編碼(SPE)、無位置編碼(NoPE)。
為了提升模型的泛化能力,該團隊也採用了資料擾動,其中包括長度、節點名稱、鏈順序和分支情況的擾動。 下面問題又來了:如果使用這些數據訓練一個模型,那麼該模型能否學會將該公理應用於新場景? 為了解答這個問題,該團隊使用這個因果無關型公理的符號演示從頭開始訓練了一個 Transformer 模型。 為了評估其泛化性能,他們在簡單的大小為3-6 個節點的因果無關公理鏈上進行了訓練,然後測試了泛化性能的多個不同方面,包括長度泛化性能(大小7-15 的鏈)、名稱泛化性能(更長的變數名)、順序泛化性能(帶有反向的邊或混洗節點的鏈)、結構泛化性能(帶有分支的圖譜)。圖 1 給出了評估 Transformer 的結構泛化的方式。
具體來說,他們基於 GPT-2 架構訓練了一個基於解碼器的有 6700 萬參數的模型。此模型有 12 個注意力層、8 個注意力頭和 512 個嵌入維度。他們在每個訓練資料集上從頭開始訓練了該模型。為了理解位置嵌入的影響,他們還研究了三種位置嵌入設定:正弦位置編碼(SPE)、可學習位置編碼(LPE)和無位置編碼(NoPE)。
表 1 給出了在訓練時未曾見過的更大因果鏈上評估時不同模型的準確度。可以看到,新模型 TS2 (NoPE) 的表現能與萬億參數規模的 GPT-4 相媲美。 圖 3 是在有更長節點名稱(長於訓練集的)的因果序列上的泛化能力評估結果以及不同位置嵌入的影響。
圖 4 評估的是在更長的未見過的因果序列上的泛化能力。
他們發現,在簡單鏈上訓練的模型可以泛化到在更大的鏈上多次應用公理,但卻無法泛化到順序或結構泛化等更複雜的場景。但是,如果在簡單鏈以及具有隨機逆向邊的鏈組成的混合資料集上訓練模型,則模型可以很好地泛化到各種評估場景。 透過擴展在 NLP 任務上的長度泛化研究結果,他們發現了位置嵌入在確保在長度和其它方面實現因果泛化的重要性。他們表現最佳的模型沒有位置編碼,但他們也發現正弦編碼在某些情況下也很好用。 這種公理訓練方法還能泛化用於一個更困難的問題,如圖 5 所示。即以包含統計獨立性陳述的前提為基礎,任務目標是根據因果關係分辨相關性。解決該任務需要多個公理的知識,包括 d-separation 和馬可夫性質。
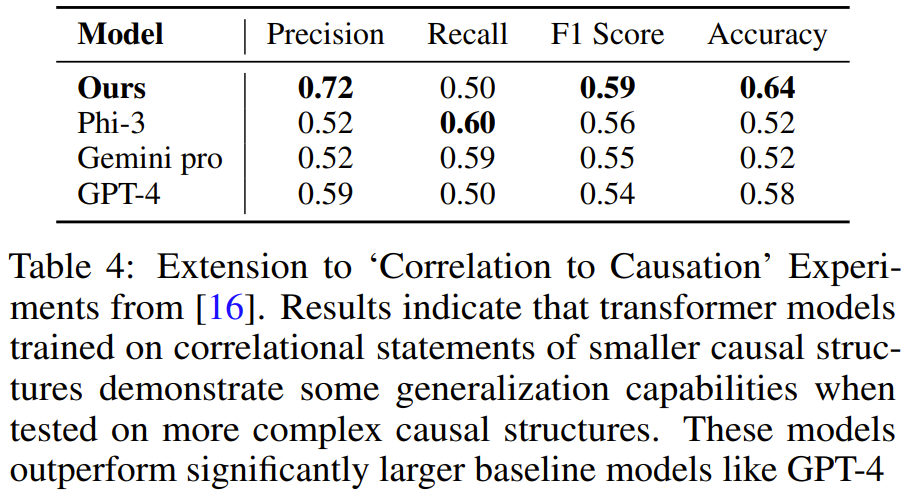
該團隊使用與上面一樣的方法生成了合成訓練數據,然後訓練了一個模型,結果發現在包含3-4 個變量的任務演示上訓練得到的Transformer 能學會解決包含5 個變量的圖譜任務。且在該任務上,該模型的準確度高於 GPT-4 和 Gemini Pro 等更大型的 LLM。
該團隊表示:「我們的研究提供了一種透過公理的符號演示教模型學習因果推理的新範式,我們稱之為公理訓練(axiomatic training)。」該方法的數據生成和訓練流程是普適的:只要一個公理能被表示成符號元組的格式,就可使用此方法學習它。 以上是公理訓練讓LLM學會因果推理:6700萬參數模型比肩萬億參數級GPT-4的詳細內容。更多資訊請關注PHP中文網其他相關文章!