
Runway和Luma又打起來了! Yann LeCun炮轟:你們再牛,也不是「世界模型」

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-03 09:13:061113瀏覽
機器之能報道
編輯:楊文
的生活絕大部分人依然不知道該如何使用。AI 影片界又「打」起來了! 因此,我們推出了「AI在用」專欄,透過直覺、有趣且簡潔的人工智慧使用案例,來具體介紹AI使用方法,並激發大家思考。
我們也歡迎讀者投稿親自實踐的創新用例。
6 月 29 日,著名生成式 AI 平台 Runway 宣布,其最新模型 Gen-3 Alpha 向部分用戶開啟測試。
同一天,Luma 推出關鍵影格新功能,並向所有用戶免費開放使用。
可謂是「你有張良計,我有過牆梯」,二者鬥得不亦樂乎。
 這可把網友們高興壞了,「6 月,多麼美好的一個月!」
這可把網友們高興壞了,「6 月,多麼美好的一個月!」
 「瘋狂的5 月、瘋狂的6 月,瘋狂到根本停下來!」
「瘋狂的5 月、瘋狂的6 月,瘋狂到根本停下來!」
「瘋狂的5 月、瘋狂的6 月,瘋狂到根本停下來!」
「瘋狂的5 月、瘋狂的6 月,瘋狂到根本停下來! 
-1-
Runway超絕鏡頭,幹掉好萊塢
Alphaway 遊戲前祭典,Runway超絕鏡頭,幹掉好萊塢迷預告—
將在「幾天內」首先向付費用戶提供,免費版本也將在未來某個時間點向所有用戶開放。

6 月 29 日,Runway 兌現承諾,宣布其最新推出的 Gen-3 Alpha 向部分用戶開啟測試。
Gen-3 Alpha 之所以備受追捧,是因為它與上一代相比,無論在光影、質量、構圖,還是文本語義還原、物理模擬、動作一致性等方面,均實現大幅度提升,就連宣傳語都是「For artists,by artists(為藝術家而生,由藝術家而生)」。

Gen-3 Alpha 效果究竟咋樣?向來整花活的網友最有發言權。接下來請欣賞-
一個可怕的怪物從倫敦泰晤士河升起的電影鏡頭:

一隻悲傷的泰迪熊在哭泣,哭到傷心處還拿紙巾鼻涕:

身穿華麗禮服的英國女郎,行走在古堡聳立的大街上,旁邊有疾馳的車輛、緩行的馬匹:

一個巨大的蜥蜴,全身鑲嵌著華麗的珠寶、珍珠,穿過茂密的植被。蜥蜴在光線下閃閃發光,畫面逼真程度堪比紀錄片。

還有一隻滿身紅藍寶石的鑲鑽蛤蟆:

夜晚的城市街道,雨水氾起霓虹燈的倒影。
鏡頭從水坑中反射的燈光開始,緩緩升起,展現出那發光的霓虹廣告牌,隨後繼續向後拉遠,呈現出整條被雨水浸濕的街道。
鏡頭的移動:一開始對準水坑中的倒影,接著一氣呵成向上提起,向後拉開,以展現這雨夜的都市風光。

視訊連結:https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
培養皿中生長的十足培養皿中生長的十足黴菌,在暗而暗的燈光,

秋天的森林中,地面被各種橙色、黃色和紅色的落葉覆蓋。
輕風拂過,鏡頭緊貼地面向前推進,一陣旋風開始形成,將落葉捲起,形成一道螺旋。鏡頭隨著落葉升起,繞著旋轉的落葉柱旋轉。

視訊連結:https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
從滿是塗鴉的隧道的低視角開始,一段穿過一段短而平坦道路的隧道,鏡頭在另一側出現後迅速升高,展現出一大片五彩繽紛的野花田,周圍是雪山環繞。

影片連結:https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
一個彈鋼琴的特寫鏡頭,沒有手指在琴鍵上跳躍,動作不足的一個彈鋼琴的特寫鏡頭,沒有手指在琴鍵上跳躍,動作不足是一個彈鋼琴的特寫鏡頭,沒有手指在琴鍵上跳躍,動作不足的一個彈鋼琴的特寫鏡頭,沒有手指在琴鍵上跳躍,動作不足,無名指上沒有戒指,但影子「無中生有」。

網友們的整活還炸出了 Runway 聯合創始人 Cristóbal Valenzuela,他為自創的蜜蜂相機生成了一段影片。
把相機安在蜜蜂背上,拍出來的景兒是這樣的:

影片連結:https://www.php.cn/link/dbf138511ed1d9278bde43cca是醬紫的:
視訊連結: https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
AI 再這樣進化下去,好萊塢的演員們又要鬧罷工了。 
-2-
Luma的關鍵幀新功能,畫面過渡絲滑
6 月 29 日,Luma AI 推出了關鍵幀功能,而且大手一揮,直接向所有用戶免費開放使用。
用戶只需上傳起始和結束圖片,並添加文字描述,Luma 就能產生具有好萊塢等級的特效影片。 例如,X 網友 @hungrydonke 上傳了兩張關鍵影格照片:
 |
 |
然後輸入提示詞是:A bunch of black confettiddenly falls(突然,黑紙屑網友@JonathanSolder3 先用midjourney 產生兩張圖片:

 |
 |
Then use the Luma keyframe function to generate an animation of Super Saiyan transformation. According to the author, Luma does not need a power-up prompt, just enter "Super Saiyan".

Video link: https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
Some netizens use this function to complete the transition of each shot, thereby mixing and matching classic fairy tales to generate a segment called "The Wolf" , The Warrior, and The Wardrobe” animation.

Video link: https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
Devil turns into angel:

Orange turns into chick:

Starbucks logo transformation:


Video link: https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
The AI video industry is so anxious. God knows how Sora can keep his composure and not show up until now.-3-
Yann LeCun "Bombardment": They don't understand physics at all
When Sora was released at the beginning of the year, "world model" suddenly became a hot concept.
Later, Google’s Genie also used the banner of “world model”. When Runway launched Gen-3 Alpha this time, the official said it “took an important step towards building a universal world model.”
What exactly is a world model?
In fact, there is no standard definition for this, but AI scientists believe that humans and animals will subtly grasp the operating laws of the world, so that they can "predict" what will happen next and take action. The study of world models is to let AI learn this ability.
Many people believe that the videos generated by applications such as Sora, Luma, and Runway are quite lifelike, and they can also generate new video content in chronological order. They seem to have learned the ability to "predict" the development of things. This coincides with the goal pursued by world model research.
However, Turing Award winner Yann LeCun has been "pouring cold water".
He believes, "Producing the most realistic-looking videos based on prompts does not mean that the system understands the physical world, and generating causal predictions from world models is very different."
On July 1, Yann LeCun posted 6 posts in a row. Generative models for bombardment videos.
He retweeted a video of AI-generated gymnastics. The characters in the video either had their heads disappear out of thin air, or four legs suddenly appeared, and all kinds of weird pictures were everywhere.

Video link: https://www.php.cn/link/dbf138511ed1d9278bde43cc0000e49a
Yann LeCun said that the video generation model does not understand basic physical principles, let alone the structure of the human body.

"Sora and other video generative models have similar problems. There is no doubt that video generation technology will become more advanced over time, but a good world model that truly understands physics will not be generative "All birds and mammals understand physics better than any video generation model, yet none of them can generate detailed videos," said Yann LeCun.

Some netizens questioned: Aren’t humans constantly generating detailed “videos” in their minds based on their understanding of physics?
Yann LeCun answered questions online, "We envision abstract scenarios that may occur, rather than generating pixel images. This is the point I want to express."
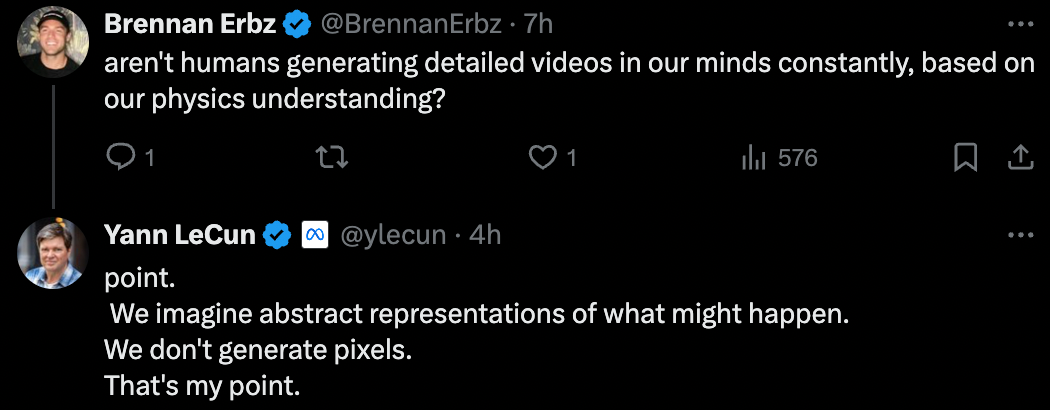
Yann LeCun retorts: No, they don’t. They just generate abstract scenarios of what might happen, which is very different from generating detailed videos.  In the future, we will bring more AIGC case demonstrations through new columns, and everyone is welcome to join the group for communication.
In the future, we will bring more AIGC case demonstrations through new columns, and everyone is welcome to join the group for communication.

以上是Runway和Luma又打起來了! Yann LeCun炮轟:你們再牛,也不是「世界模型」的詳細內容。更多資訊請關注PHP中文網其他相關文章!