AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本論文作者來自華為蒙特利爾諾亞實驗室的康計堹嬢,本論文作者來自華為蒙特利爾諾亞實驗室的康計堯。 人工智慧(AI)在過去十年中取得了長足進步,特別是在自然語言處理和電腦視覺領域。然而,如何提升 AI 的認知能力和推理能力,仍然是一個巨大的挑戰。 近期,一篇題為《MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time》的論文提出了基於樹搜尋的推理時間能力提升方法MindStar [1],該方法在開源模型Llama -13-B 與Mistral-7B 上達到了近似閉源大模型GPT-3.5 與Grok-1 在數學問題上的推理能力。 
- 論文標題:MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
-
論文地址:https://arxiv.org/abs/
MindStar數學問題的應用效果:
 圖1 中:不同大型語言模式的數學準確度。 LLaMA-2-13B 在數學表現上與 GPT-3.5 (4-shot) 類似,但節省了約 200 倍的運算資源。
圖1 中:不同大型語言模式的數學準確度。 LLaMA-2-13B 在數學表現上與 GPT-3.5 (4-shot) 類似,但節省了約 200 倍的運算資源。
隨著模型規模的快速增長,基於Transformer 的大型語言模型(LLMs)在指令遵循[1,24]和創意寫作[5] 等領域展現了令人印象深刻的成果。然而,解鎖 LLMs 解決複雜推理任務的能力仍然是一大挑戰。最近的一些研究[6,7] 嘗試透過監督微調(Supervised Fine-Tuning, SFT)來解決,透過將新的推理資料樣本與原始資料集混合,使LLMs 學習這些樣本的底層分佈,並嘗試模仿所學邏輯來解決未見過的推理任務。儘管這種方法有效能提升,但它嚴重依賴大量的訓練和額外的資料準備 [8,9]。
Llama-3 報告 [10] 強調了一個重要的觀察:當面對一個具有挑戰性的推理問題時,模型有時會產生正確的推理軌跡。這表明模型知道如何產生正確答案,但在選擇上有困難。基於這項發現,我們提出了一個簡單的問題:我們能否透過幫助 LLMs 選擇正確的輸出來增強它們的推理能力?為探索這一點,我們進行了一項實驗,利用不同的獎勵模型進行 LLMs 輸出選擇。實驗結果表明,步驟級選擇顯著優於傳統的 CoT 方法。
圖2 MindStar No並利用過程監督的獎勵模型(Process-supervised Reward Model, PRM),M * 在推理樹空間中有效導航,辨識近似最優路徑。結合束搜尋(Beam Search, BS)和 Levin 樹搜尋(Levin Tree Search, LevinTS)的思想,進一步增強了搜尋效率,並保證在有限計算複雜度內找到最佳推理路徑。 2.1 過程監督獎勵模型過程監督獎勵模型 (PRM) 的設計目的是評估大語言模型 (LLM) 產生的中間步驟,以幫助選擇正確的推理路徑。這種方法借鑒了其他應用中 PRM 的成功經驗。具體而言,PRM 以當前推理路徑和潛在的下一步作為輸入,並傳回獎勵值。 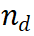 PRM 透過考慮整個當前推理軌跡來評估新步驟,鼓勵與整體路徑的一致性和忠實性。高獎勵值表明,新的步驟
PRM 透過考慮整個當前推理軌跡來評估新步驟,鼓勵與整體路徑的一致性和忠實性。高獎勵值表明,新的步驟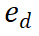 )對於給定的推理路徑
)對於給定的推理路徑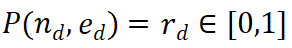 可能是正確的,從而使擴展路徑值得進一步探索。相反,低獎勵值則表示新步驟可能不正確,這意味著遵循此路徑的解決方案也可能不正確。 M* 演算法包含兩個主要步驟,迭代直到找到正確的解決方案:
可能是正確的,從而使擴展路徑值得進一步探索。相反,低獎勵值則表示新步驟可能不正確,這意味著遵循此路徑的解決方案也可能不正確。 M* 演算法包含兩個主要步驟,迭代直到找到正確的解決方案: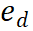
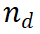
1. 推理路徑擴展:在每次迭代中,基礎 LLM 產生當前推理路徑的下一步。 2. 評估與選擇:使用 PRM 評估產生的步驟,並根據這些評估選擇下一次迭代的推理路徑。 2.2 推理路徑擴展在選擇要擴展的推理路徑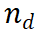 後,我們設計了一個提示模板(Example 3.1),以從 LLM 中收集下一步。如範例所示,LLM 將原始問題作為 {question},將當前推理路徑作為 {answer}。請注意,在演算法的第一次迭代中,所選的節點是僅包含問題的根節點,因此 {answer} 為空。對於推理路徑
後,我們設計了一個提示模板(Example 3.1),以從 LLM 中收集下一步。如範例所示,LLM 將原始問題作為 {question},將當前推理路徑作為 {answer}。請注意,在演算法的第一次迭代中,所選的節點是僅包含問題的根節點,因此 {answer} 為空。對於推理路徑 ,LLM 會產生 N 個中間步驟,並將它們作為目前節點的子節點附加。在演算法的下一步中,將評估這些新產生的子節點,並選擇一個新的節點進行進一步擴展。我們也意識到,生成步驟的另一種方法是使用步驟標記對 LLM 進行微調。然而,這可能會降低 LLM 的推理能力,更重要的是,這與本文的重點 —— 在不修改權重的情況下增強 LLM 推理能力相悖。 在擴展推理樹後,我們使用預訓練的過程監督獎勵模型(PRM)來評估每個新生成的步驟。如同前面所提到的,PRM 採取路徑和步驟 ,並傳回對應的獎勵值。在評估之後,我們需要一個樹搜尋演算法來選擇下一個要擴展的節點。我們的框架不依賴特定的搜尋演算法,在這項工作中,我們實例化了兩種最佳優先搜尋方法,即 Beam Search 和 Levin Tree Search。 在GSM8K 和MATH 資料集上的廣泛評估顯示,M * 顯著提升了開源模型(如LLaMA-2)的推理能力,其表現可與性能更大規模的閉源模型(如GPT-3.5 和Grok-1)媲美,同時大幅減少了模型規模和計算成本。這些發現突顯了將計算資源從微調轉移到推理時間搜尋的潛力,為未來高效推理增強技術的研究開闢了新途徑。
,LLM 會產生 N 個中間步驟,並將它們作為目前節點的子節點附加。在演算法的下一步中,將評估這些新產生的子節點,並選擇一個新的節點進行進一步擴展。我們也意識到,生成步驟的另一種方法是使用步驟標記對 LLM 進行微調。然而,這可能會降低 LLM 的推理能力,更重要的是,這與本文的重點 —— 在不修改權重的情況下增強 LLM 推理能力相悖。 在擴展推理樹後,我們使用預訓練的過程監督獎勵模型(PRM)來評估每個新生成的步驟。如同前面所提到的,PRM 採取路徑和步驟 ,並傳回對應的獎勵值。在評估之後,我們需要一個樹搜尋演算法來選擇下一個要擴展的節點。我們的框架不依賴特定的搜尋演算法,在這項工作中,我們實例化了兩種最佳優先搜尋方法,即 Beam Search 和 Levin Tree Search。 在GSM8K 和MATH 資料集上的廣泛評估顯示,M * 顯著提升了開源模型(如LLaMA-2)的推理能力,其表現可與性能更大規模的閉源模型(如GPT-3.5 和Grok-1)媲美,同時大幅減少了模型規模和計算成本。這些發現突顯了將計算資源從微調轉移到推理時間搜尋的潛力,為未來高效推理增強技術的研究開闢了新途徑。 
表 1 展示了各種方案在 GSM8K 和 MATH 推理基準上的對比結果。每個條目的數字表示問題解決的百分比。符號 SC@32 表示在 32 個候選結果中的自一致性,而 n-shot 表示少樣本例子的結果。 CoT-SC@16 指的是 16 個思維鏈(CoT)候選結果中的自一致性。 BS@16 代表束搜尋方法,即在每個步驟層級涉及 16 個候選結果,而 LevinTS@16 詳細說明了使用相同數量候選結果的 Levin 樹搜尋方法。值得注意的是,MATH 資料集上 GPT-4 的最新結果為 GPT-4-turbo-0409,我們特別強調這一點,因為它代表了 GPT-4 家族中的最佳表現。 
圖 3 我們研究了 M * 性能如何隨著步驟層級候選數量的變化而變化。我們選擇 Llama-2-13B 作為基礎模型,並分別選擇束搜尋(BS)作為搜尋演算法。 
圖 4 Llama-2 和 Llama-3 模型家族在 MATH 資料集上的尺度定律。所有結果均來自它們的原始資源。我們使用 Scipy 工具和對數函數來計算擬合曲線。 
表2 不同方法在回答問題時的平均token 生產數量本文*增強預訓練大型語言模型的推理能力。透過將推理任務視為搜尋問題並利用過程監督的獎勵模型,M* 在推理樹空間中有效導航,辨識近似最優路徑。結合束搜尋和 Levin 樹搜尋的思想,進一步增強了搜尋效率,並保證在有限計算複雜度內找到最佳推理路徑。廣泛的實驗結果表明,M* 顯著提升了開源模型的推理能力,其表現可與更大規模的閉源模型媲美,同時大幅減少了模型規模和計算成本。 這些研究成果表明,將計算資源從微調轉移到推理時間搜尋具有巨大的潛力,為未來高效推理增強技術的研究開闢了新途徑。 [1] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowes, Ryana, Ryan Lowessl, Ryan A. summarize with human feedback。 Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022. Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. arXiv, preprint arXiv:238385, preprint [4] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models traine. arXiv preprint arXiv:2107.03374, 2021.[5] Carlos Gómez-Rodríguez and Paul Williams. A confederacy of models: A com Gómez-Rodríguez and Paul Williams. A confederacy of models: A com Gómez-Rodríguez and Paul Williams. A confederacy of models: A com Gómez-Rodríguez and Paul Williams. A confederacy of models: A com Gómez-Rodríguez and Paul Williams。 433, 2023. [6] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for mathlan. arXiv preprint arXiv:2309.12284, 2023.[7] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Ming Lia of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.[8] Keiran Paster, Marco Dos Sanaster, openir4s Sanqutical web text. arXiv preprint arXiv:2310.06786, 2023.[9] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Li, Zhihong Shao, RX Xu, Damai Dai, Yifei, Delii Li, Yhib. : Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023.[10] Metaable. 4 . URL https://ai.meta.com/blog/meta-llama-3/. Accessed: 2024-04-30.以上是等不來OpenAI的Q*,華為諾亞探索LLM推理的秘密武器MindStar先來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!



 ,LLM 會產生 N 個中間步驟,並將它們作為目前節點的子節點附加。在演算法的下一步中,將評估這些新產生的子節點,並選擇一個新的節點進行進一步擴展。我們也意識到,生成步驟的另一種方法是使用步驟標記對 LLM 進行微調。然而,這可能會降低 LLM 的推理能力,更重要的是,這與本文的重點 —— 在不修改權重的情況下增強 LLM 推理能力相悖。
,LLM 會產生 N 個中間步驟,並將它們作為目前節點的子節點附加。在演算法的下一步中,將評估這些新產生的子節點,並選擇一個新的節點進行進一步擴展。我們也意識到,生成步驟的另一種方法是使用步驟標記對 LLM 進行微調。然而,這可能會降低 LLM 的推理能力,更重要的是,這與本文的重點 —— 在不修改權重的情況下增強 LLM 推理能力相悖。