
300多篇相關研究,復旦、南洋理工最新多模態影像編輯綜述論文

- PHPz原創
- 2024-06-29 06:14:41620瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
該文章的第一作者帥欣成,目前在復旦大學FVL實驗室攻讀博士學位,畢業於上海交通大學。他的主要研究方向包括影像和影片編輯以及多模態學習。

論文題目:A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models 發表單位:復旦大學FVL 實驗室,南洋理工大學 - 發表單位:復旦大學FVL 實驗室,南洋理工大學 發表單位:復旦大學FVL 實驗室,南洋理工大學
.org/abs/2406.14555
2.1 關於編輯任務的定義與討論範圍。相較於現有的演算法以及先前的編輯綜述,本文對於影像編輯任務的定義更加廣泛。具體的,本文將編輯任務分為 content-aware 和 content-free 場景群組。其中 content-aware 組內的場景為先前的文獻所討論的主要任務,它們的共通性是保留圖像中的一些低階語義特徵,如編輯無關區域的像素內容,或圖像結構。此外,我們開創性地將客製化任務(customization)納入到content-free 場景組中,將這一類保留高級語義(如主體身份信息,或者其他細粒度屬性)的任務作為對常規的編輯場景的補充。 

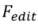 3.1 Inversion 演算法。 Inversion 演算法
3.1 Inversion 演算法。 Inversion 演算法(inversion clue),並以對應的來源文字描述
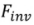 兩種類型的 inversion 演算法。其可以形式化為:
兩種類型的 inversion 演算法。其可以形式化為: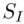
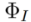
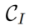 Tuning-based inversion
Tuning-based inversion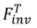 透過原有的 diffusion 訓練過程將來源影像集合植入擴散模型的生成分佈中。形式化過程為:
透過原有的 diffusion 訓練過程將來源影像集合植入擴散模型的生成分佈中。形式化過程為: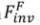

 其中
其中
。 
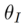
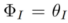 Forward-based inversion
Forward-based inversion)。形式化過程為:
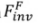
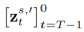
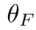 為方法中引入的參數,用於最小化
為方法中引入的參數,用於最小化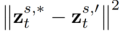 ,其中,
,其中,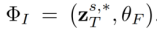 。
。 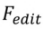 根據
根據 和多模態引導集合
和多模態引導集合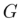 來產生最終的編輯結果
來產生最終的編輯結果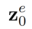 。包含 attention-based
。包含 attention-based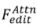 ,blending-based
,blending-based ,score-based
,score-based 以及 optimization-based
以及 optimization-based 的 editing 演算法。其可以被形式化為:
的 editing 演算法。其可以被形式化為:
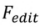 進行瞭如下操作:
進行瞭如下操作:
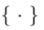 中的操作表示編輯演算法對於擴散模型的取樣,用於確保編輯後的影像
中的操作表示編輯演算法對於擴散模型的取樣,用於確保編輯後的影像 與來源影像集合
與來源影像集合 的一致性,並反應出
的一致性,並反應出 中引導條件所指明的視覺變換。
中引導條件所指明的視覺變換。 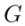


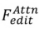 的形式化過程:
的形式化過程:

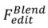 的形式化過程:
的形式化過程: 🎎 based editing
🎎 based editing
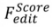
 3.3 Training-Based 的編輯方法。與 training-free 的方法不同的是,training-based 演算法透過在任務特定的資料集中直接學習來源影像集合到編輯影像的映射。這一類演算法可以看作是 tuning-based inversion 的擴展,即透過額外引入的參數將來源影像編碼到生成分佈中。在這類演算法中,最重要的是如何將來源影像注入 T2I 模型中,以下是針對不同編輯場景的注入方案。
3.3 Training-Based 的編輯方法。與 training-free 的方法不同的是,training-based 演算法透過在任務特定的資料集中直接學習來源影像集合到編輯影像的映射。這一類演算法可以看作是 tuning-based inversion 的擴展,即透過額外引入的參數將來源影像編碼到生成分佈中。在這類演算法中,最重要的是如何將來源影像注入 T2I 模型中,以下是針對不同編輯場景的注入方案。

Content-aware 任務的注入方案:

圖3. Content-free 任務的注入方案




圖 7.中關於optimization-based editing

5.不同組合在文字引導編輯場景下的比較
 結果分析以及更多實驗結果請查閱原始論文。
結果分析以及更多實驗結果請查閱原始論文。
以上是300多篇相關研究,復旦、南洋理工最新多模態影像編輯綜述論文的詳細內容。更多資訊請關注PHP中文網其他相關文章!