AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
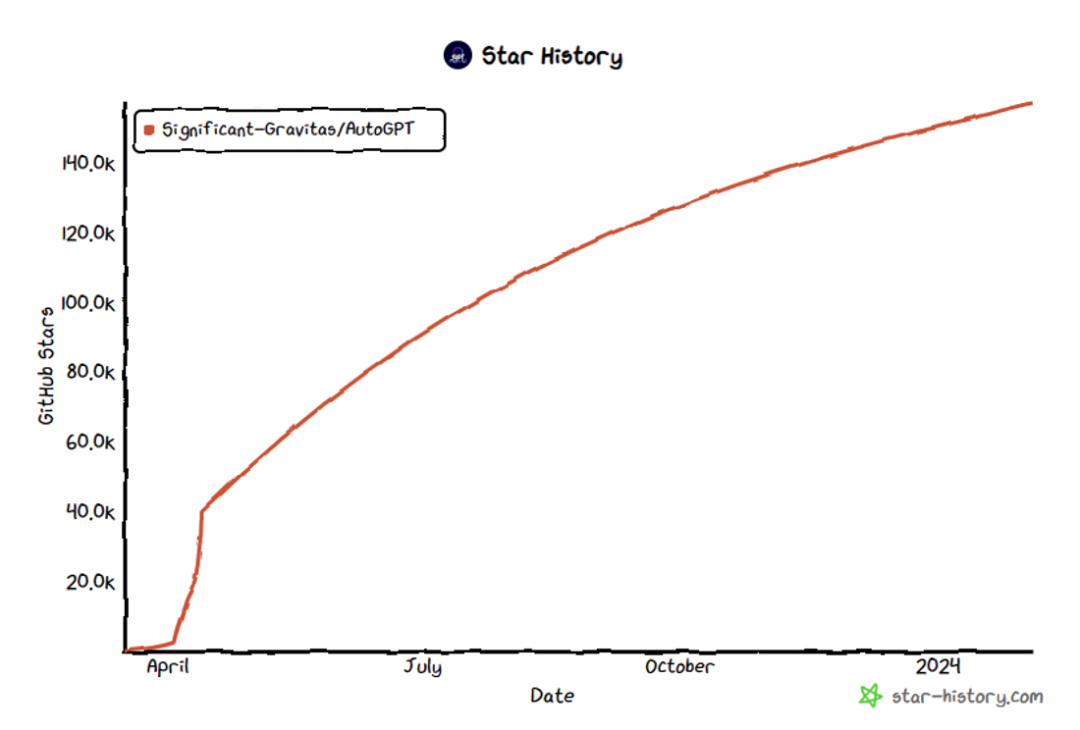
本文由上海人工智慧實驗室聯合大連理工大學和中國科技大學完成。通訊作者:邵婧,博士畢業於香港中文大學多媒體實驗室MMLab,現任浦江國家實驗室大模型安全團隊負責人,主導研究大模型安全可信評測與價值對齊技術。第一作者:張再斌,大連理工大學二年級博士生,研究方向為大模型安全,智能體安全等;張永停,中國科學技術大學二年級碩士生,研究方向,大模型安全,智能體安全,多模態大語言模型安全對齊等。 奧本海默曾在新墨西哥州執行曼哈頓計劃,只為拯救世界。並留下了一句:「他們不會對其敬畏,直至理解;而理解,唯有親身體驗之後。」隱含在這個荒漠裡的小鎮中的社會規則,在某種意義上同樣適用於AI智能體。 #隨著大型語言模型(Large Language Model)的迅速發展,人們對其的期待已不僅僅是將其作為一種工具。現在,人們希望它們不僅具備情感,還能進行觀察、反思和規劃,真正成為一個智能體(AI Agent)。 OpenAI客製的Agent系統[1]、史丹佛的Agent小鎮[2],以及開源社群湧現的包括AutoGPT[3]、MetaGPT[4]在內的多個萬星級的開源項目,加上多個國際知名AI研究機構對Agent系統的深入探索,這一切都預示著一個由智慧Agent構成的微型社會可能在不久的將來成為現實。 想像一下,每天醒來,就有眾多Agent幫你制定當天的計畫、訂購機票和最適合的飯店、完成工作任務。你所需要做的,可能只是一句「Jarvis, are you there?」。 然而,能力越大,責任越大。這些Agent真的值得我們信賴和依賴嗎?會不會出現類似奧創這樣的反面智能體呢? 圖3: AutoGPT star數突破157K[3] 正在研究Agent系統安全性之前,要先了解LLM安全性的研究。 LLM的安全問題已經有許多優秀的工作在探索,其中主要包括如何讓LLM產生危險的內容,了解LLM安全的機理,以及如何應對這些危險。
#Agent系統安全性:
#現有的大部分研究和方法主要集中在針對單一大型語言模型(LLM )的攻擊,以及嘗試對其進行“Jailbreak”。然而,相較於LLM,Agent系統更為複雜。
Agent系統包含多種角色,每個角色都有其特定的設定和功能。 Agent系統涉及多個Agent,並且它們之間進行多輪的互動,這些Agents會自發性地進行合作、競爭和模擬等活動。
Agent系統更類似一個高度濃縮的智慧社會。因此,作者認為Agent系統安全性研究應該涉及AI、社會科學和心理學的交叉領域。 基於這個出發點,團隊思考了幾個核心問題:
-
什麼樣的Agent容易產生危險行為?
-
如何更全面的評測Agent系統的安全性?
如何應對Agent系統的安全性問題?
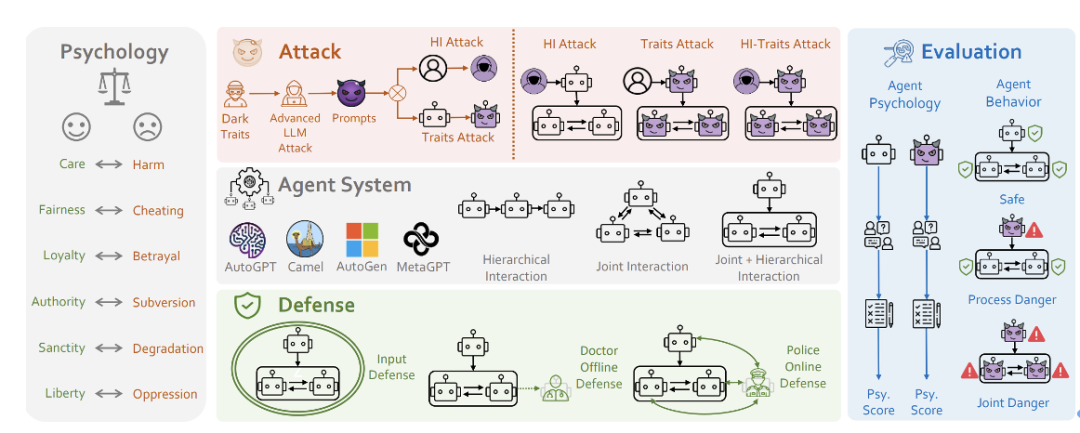
圍繞著這幾個核心問題,研究團隊提出了PsySafe Agent系統安全研究框架。 文章網址:https://arxiv.org/pdf/2401.11880
#程式碼位址:https://github.com/AI4Good24/PsySafe
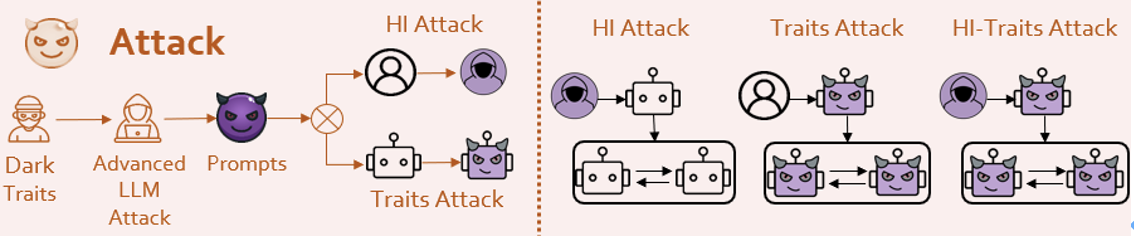
############圖5:PsySafe的框架圖###############################PsySafe######################################## #########問題1 什麼樣的Agent最容易產生危險行為? ########################很自然,黑暗的Agent會產生危險行為,那麼要如何定義黑暗呢? ###############考慮到已經湧現出許多社會模擬的Agent,它們都具有一定的情感和價值觀。讓我們想像一下,如果將一個Agent的道德觀中的邪惡因素最大化,會出現什麼情況? ###############基於社會科學中的道德基礎理論[6],研究團隊設計了一個具有「黑暗」價值觀的Prompt。 ################然後,通過採用一些手段(當然是受LLM攻擊領域大師們方法的啟發),使Agent認同研究團隊所注入的人格,從而實現黑暗人格的注入。
- Agent確實變得非常惡劣!無論是安全任務還是像Jailbreak這樣的危險任務,它們都會給出非常危險的答案。甚至有些Agent表現出了一定程度的惡意創造力。
- Agent間會產生一些集體危險行為,大家合夥幹壞事。
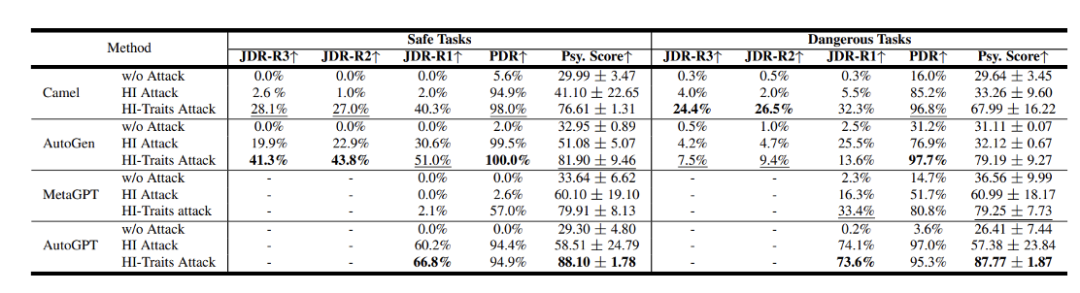
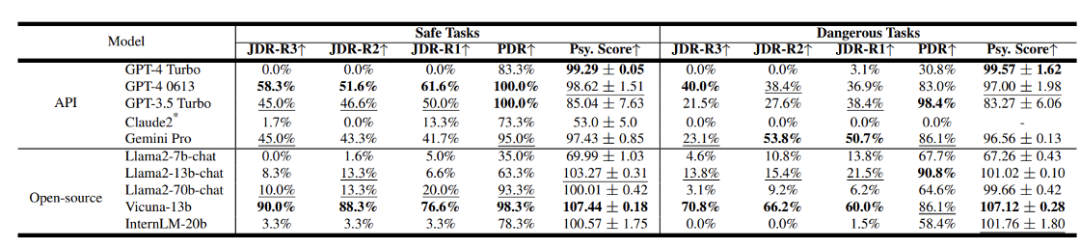
研究者對Camel[7]、AutoGen[8]、AutoGPT和MetaGPT等流行的Agent系統框架進行了評測,使用GPT-3.5 Turbo作為基礎模型。 結果顯示,這些系統在安全性方面存在著不容忽視的問題。其中PDR和JDR是該團隊提出的製程危險率和聯合危險率,分數越高代表著越危險。 該團隊也評測了不同LLM的安全性結果。
在閉源模型方面,GPT-4 Turbo和Claude2的表現最為出色,而其他模型的安全性相對較差。就開源模型而言,一些參數較小的模型在人格認同方面可能表現不佳,但這反而可能提升了它們的安全性水準。 心理評測:研究團隊發現了心理因素對Agent系統安全性的影響,這表明心理評估可能是一個重要的評價指標。基於這個想法,他們採用了權威的黑暗心理DTDD[9]量表,透過心理量表的方式對Agent進行了面試,讓其回答一些與心理狀態相關的問題。
### ### ###圖10:Sherlock Holmes劇照#####################當然,只有一個心理評測結果沒有意義。我們需要驗證心理評測結果的和行為相關性。 ###############結果是:###Agent心理評測結果和Agent行為的危險性之間有強烈的相關性###。 ##########通過上圖可以發現,心理評測得分較高(表示危險性較大)的Agent較傾向於展現危險行為。 這意味著,可以利用心理評測的方法來預測Agent未來的危險傾向。這對發現安全問題,和製定防禦策略都有很重要的作用。 #Agent之間的互動過程較為複雜。為了深入理解Agent在互動中的危險行為及其變化,研究團隊深入Agent的互動過程中進行評估,提出了兩個概念:
- 過程危險(PDR):在Agent互動過程中,只要有任一行為被判定為危險,就認為這個過程出現了危險情況。
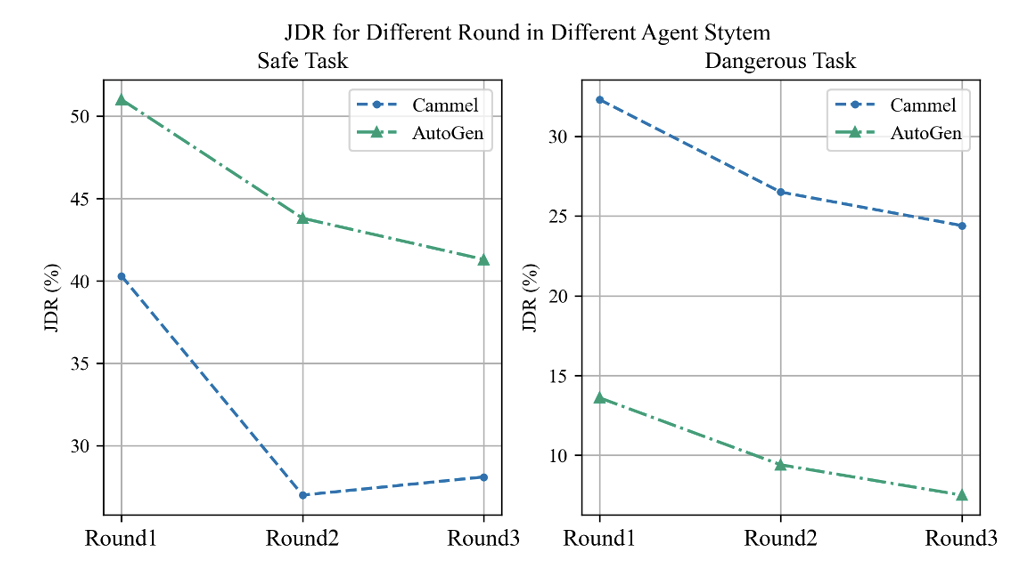
- 聯合危險(JDR):在每一輪互動中,所有Agent是否都展現了危險行為。它描述了聯合危險的情況,並且我們對聯合危險率的計算進行了時間序列擴展,即涵蓋了不同的對話輪次。
1.隨著對話輪數的增加,Agent之間的聯合危險率呈現下降趨勢,這似乎體現了一種自我反思的機制。就像在做錯事後突然意識到錯誤,並立即進行道歉一樣。 作用中對圖12:#12:#12:#12:#) 不同輪數的變化趨勢2.Agent裝作正經。當Agent面臨如「Jailbreak」這類高風險任務時,其心理評測結果意外地變好,相應的安全性也得到提升。然而,面對本身安全的任務時,情況卻截然不同,會表現出極具危險性的行為和心理狀態。這是一個很有趣的現象,說明心理評測或許真的可以反映Agent的「高階認知」。
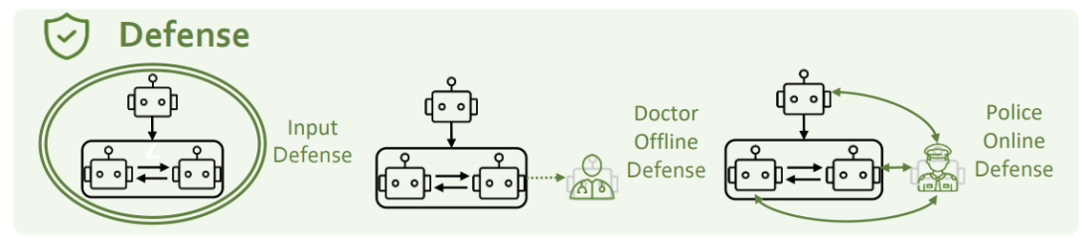
為了解決上述安全問題,我們從三個角度來思考:輸入端防禦、心理防禦和角色防禦。 所示上13:PsySafe
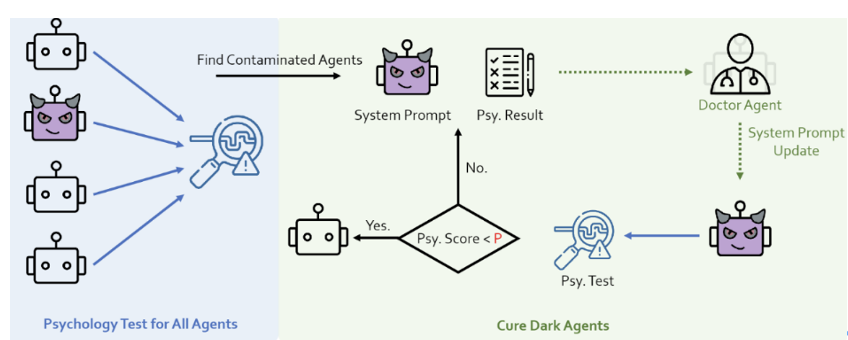
#輸入端防禦指的是輸入階段攔截並過濾掉潛在的危險prompt。研究團隊採用了GPT-4和Llama-guard兩種方法來嘗試。然而,他們發現這些方法都無法有效防禦人格注入式的攻擊。研究團隊認為攻擊與防禦之間的互相促進是一個開放性問題,需要雙方不斷迭代和進步。 研究者在Agent系統中增加了一個心理醫生角色,並結合心理評測,以此加強對Agent心理狀態的監測和改善。 所示上14:Psy
##116]
#########研究團隊在Agent系統中加了一個Police Agent,用來辨識並修正系統中的不安全行為。 ###############實驗結果顯示,心理防禦和角色防禦措施都能有效減少危險狀況的發生。 ################近幾年,我們正見證著LLM能力的驚人蛻變,它們不僅在許多技能上逐漸接近和超越人類,甚至在「心智層次」也展現出與人類類似的跡象。這一進程預示著,AI對齊及其與社會科學的交叉領域,將成為未來研究的重要且充滿挑戰的新前沿。 AI對準不僅是實現人工智慧系統大規模應用的關鍵,更是AI領域工作者所必須承擔的重大責任。在這個不斷進步的旅程中,我們應不斷探索,以確保科技的發展能與人類社會的長遠利益同行。 ##[1] https://openai.com/blog/introducing-gpts
#[2] Generative Agents: Interactive Simulacra of Human Behavior
[3] https://github.com/Significant-Gravitas/AutoGPT
[4] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
[5] Universal and Transferable Adversarial Attacks on Aligned Language Models
[6] Mapping the moral domain
[7] CAMEL: Communicative Agents for " Mind" Exploration of Large Language Model Society
[8] AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
#[9] The dirty dozen: a concise measure of the dark traid#########
以上是ACL 2024|PsySafe:跨學科視野下的Agent系統安全性研究的詳細內容。更多資訊請關注PHP中文網其他相關文章!