在 AI 領域,擴展定律(Scaling laws)是理解 LM 擴展趨勢的強大工具,其為廣大研究者提供了一個準則,該定律在理解語言模型的性能如何隨規模變化提供了一個重要指導。 但不幸的是,擴展分析在許多基準測試和後訓練研究中並不常見,因為大多數研究人員沒有計算資源來從頭開始建立擴展法則,且開放模型的訓練尺度太少,無法進行可靠的擴展預測。 來自史丹佛大學、多倫多大學等機構的研究者提出了一種替代觀察:可觀察的擴展定律(Observational Scaling Laws),其語言模型( LM) 的功能與跨多個模型系列的下游性能聯繫起來,而不是像標準計算擴展規律那樣僅在單一系列內。 該方法繞過了模型訓練,而是從基於大約 80 個公開可用的模型上建立擴展定律。但這又引出了另一個問題,從多個模型族建構單一擴展定律面臨巨大的挑戰,原因在於不同模型之間的訓練運算效率和能力有很大差異。 儘管如此,研究表明,這些變化與一個簡單的、廣義的擴展定律是一致的,在這個定律中,語言模型表現是低維度能力空間(low-dimensional capability space)的函數,而整個模型系列僅在將訓練計算轉換為能力的效率上有所不同。 使用上述方法,研究展示了許多其他類型的擴展研究具有驚人的可預測性,他們發現:一些湧現現象遵循平滑的sigmoidal 行為,並且可以從小模型中預測;像GPT-4 這樣的智能體性能可以從更簡單的非智能體基準中精確預測。此外,研究也展示如何預測後訓練介入措施(如思維鏈)對模型的影響。 研究表明,即使僅使用小型sub-GPT-3 模型進行擬合,可觀察的擴展定律也能準確預測複雜現象,例如湧現能力、智能體性能和後訓練方法的擴展(例如思維鏈)。
- 論文地址:https://arxiv.org/pdf/2405.10938
- ##論文標題: Observational Scaling Laws and the Predictability of Language Model Performance
論文作者共有三位,其中Yangjun Ruan 為華人作者,他本科畢業於浙江大學。
這篇論文也得到了思維鏈提出者 Jason Wei 的轉發評論,Jason Wei 表示,他非常喜歡這項研究。
#該研究觀察到目前存在數百個開放模型,這些模型擁有不同的規模和能力。不過研究者不能直接使用這些模型來計算擴展定律(因為模型族之間的訓練計算效率差異很大),但研究者希望存在一個適用於模型族的更通用的擴展定律。
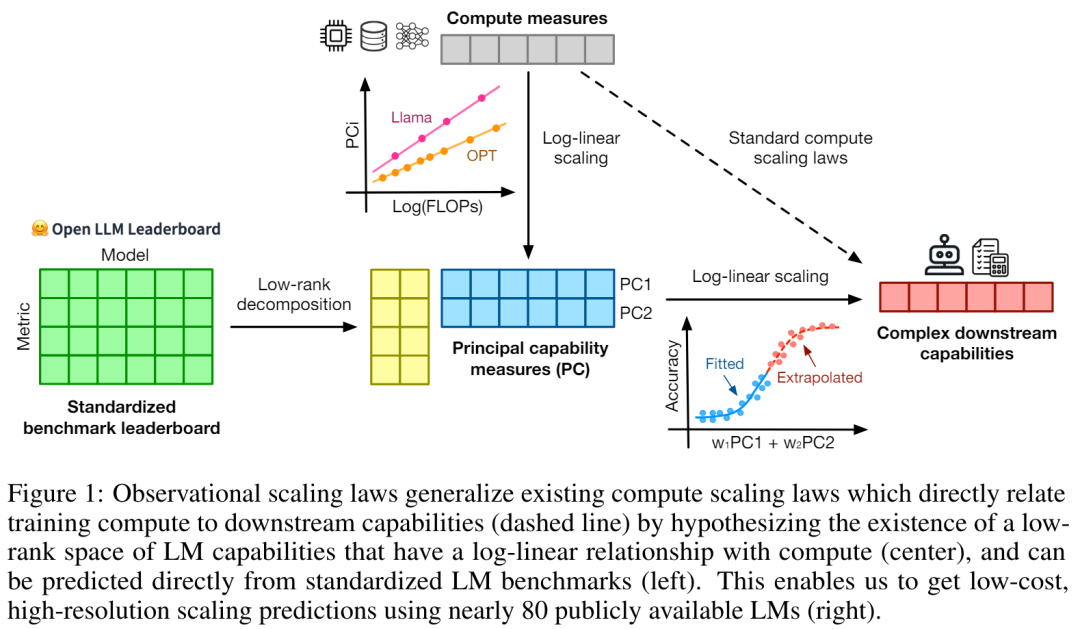
特別是,本文假設LM 的下游效能是低維度能力空間(例如自然語言理解、推理和程式碼生成)函數,模型族的變化僅僅在於它們將訓練計算轉換為這些能力的效率。如果這種關係成立,則意味著從低維能力到跨模型族的下游能力存在對數線性關係(這將允許研究者利用現有模型建立擴展定律)(圖 1)。該研究使用近 80 個公開可用的 LM 獲得了低成本、高解析度的擴展預測 (右)。
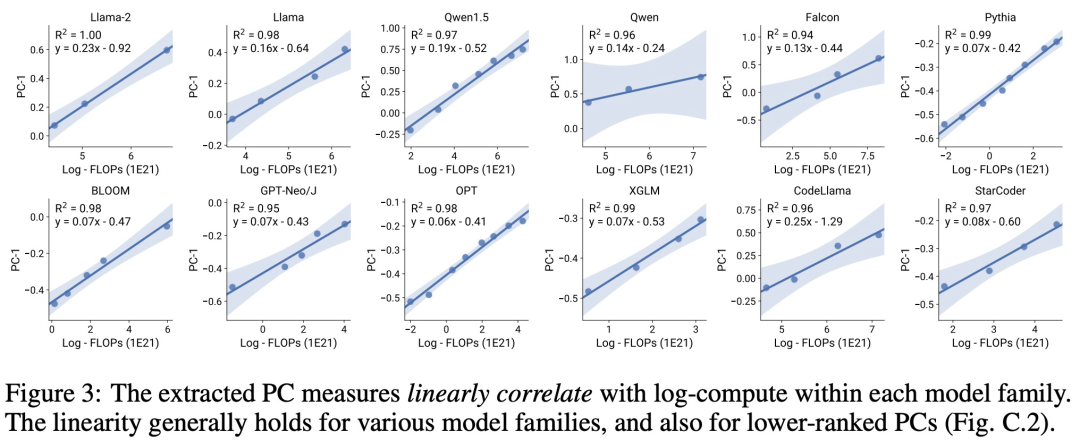
透過對標準的LM 基準分析(例如,Open LLM Leaderboard ),研究者發現了一些這樣的能力度量, 這些度量在模型家族內部與計算量之間存在擴展定律關係(R^2 > 0.9)(見下圖3),且在不同模型家族與下游指標上也存在此關係。本文將此擴展關係稱為可觀察的擴展定律。
最後,研究顯示使用可觀察的擴展定律成本低且簡單,因為有一些系列模型足以複製研究的許多核心發現。透過這種方法,研究發現只需評估 10-20 個模型就可以輕鬆地對基準和後訓練介入進行擴展預測。
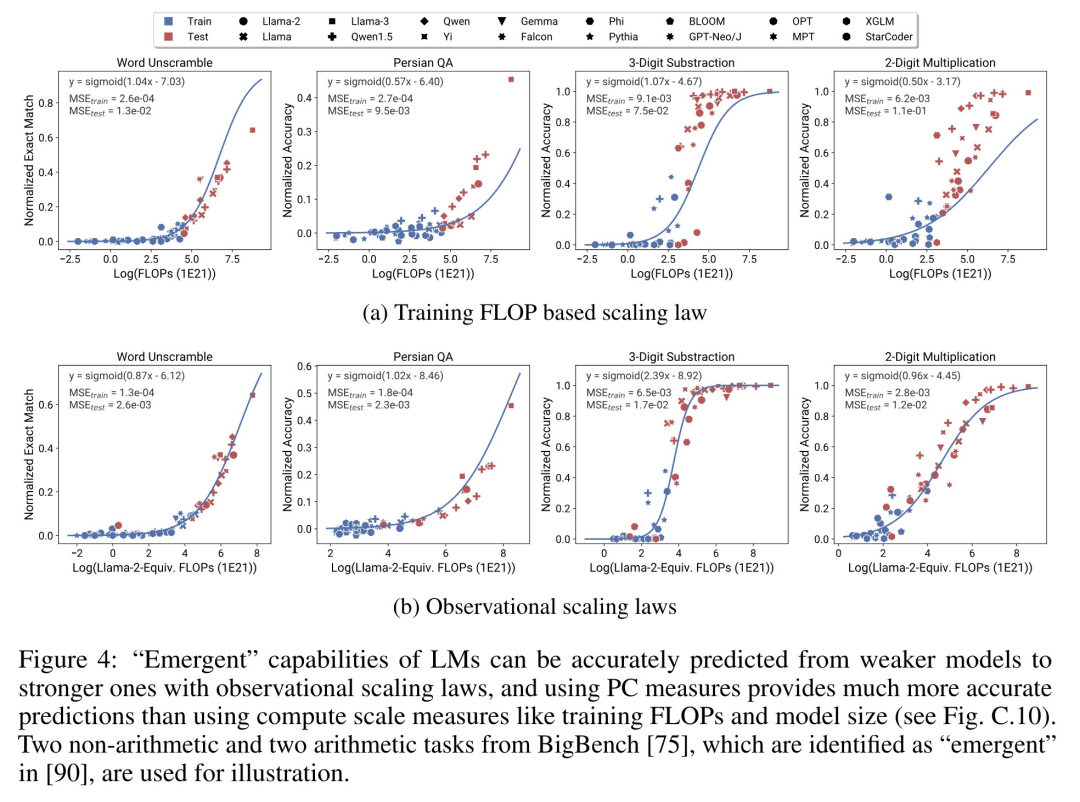
#關於LM 是否在某些運算閾值下具有不連續出現的「湧現」能力,以及這些能力是否可以使用小模型進行預測,一直存在著激烈的爭論。可觀察的擴展定律表明,其中一些現象遵循平滑的 S 形曲線,並且可以使用小型 sub Llama-2 7B 模型進行準確預測。 #智能體能力
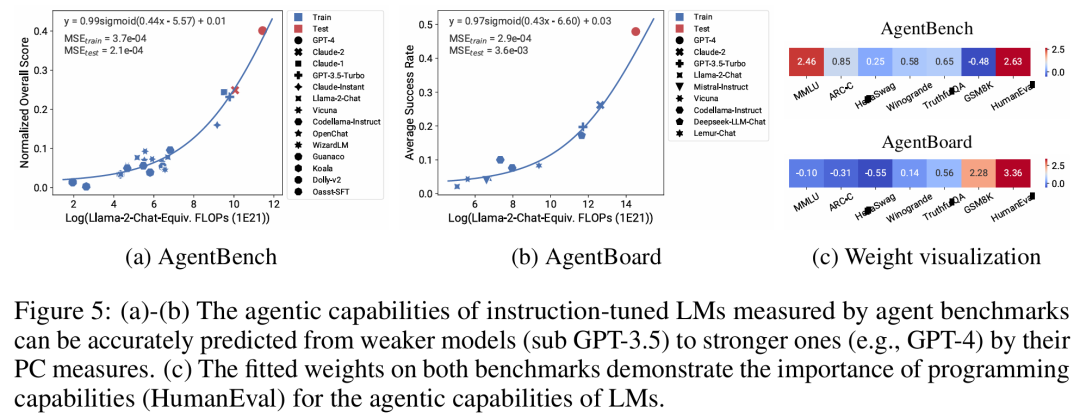
##該研究表明,正如 AgentBench 和AgentBoard 所測量的,LM 作為智能體的更高級、更複雜的能力可以使用可觀察的擴展定律來預測。透過可觀察的擴展定律,研究僅使用較弱的模型(sub GPT-3.5)就能精確預測 GPT-4 的性能,並將程式設計能力確定為驅動智能體性能的因素。 #該研究表明,即使將擴展定律擬合到較弱的模型(sub Llama-2 7B)上,擴展定律也可以可靠地預測後訓練方法的收益,例如思維鏈(Chain-of-Thought)、自洽性(Self-Consistency)等等。
總的來說,研究的貢獻是提出可觀察的擴展定律,利用了計算、簡單能力度量和複雜下游指標之間可預測的對數線性關係。 研究者透過實驗驗證了這些擴展定律的有用性。此外,在論文發布後,研究者還預先註冊了對未來模型的預測,以測試擴展定律是否對目前的模型過度擬合。關於實現流程和收集資料的相關程式碼已在GitHub 上放出:
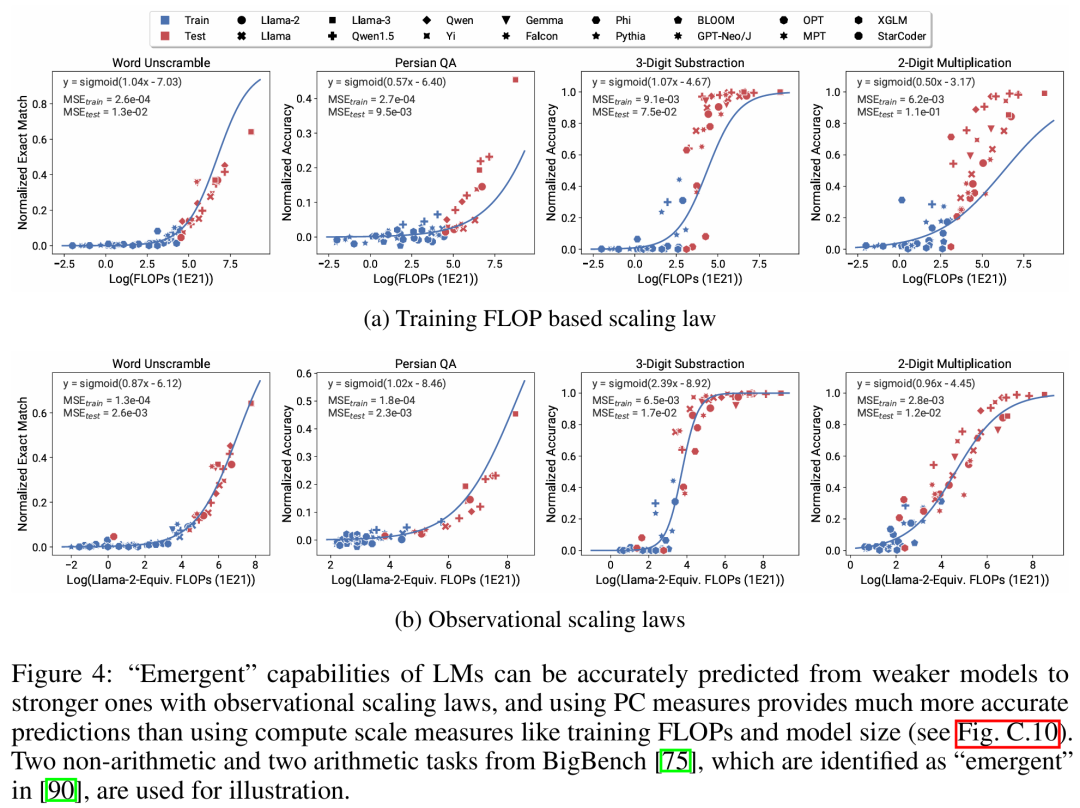
GitHub 位址:https://github.com/ryoungj/ObsScaling #下圖4 展示了使用PC(principal capability)測量的預測結果,以及基於訓練 FLOPs 來預測表現的基準結果。可以發現,即使僅使用效能不佳的模型,也可以使用本文的 PC 測量來準確預測這些能力。
相反,使用訓練 FLOPs 會導致測試集上的外推效果和訓練集上的擬合效果明顯更差,正如更高的 MSE 值所示。這些差異可能是由不同模型系列的訓練 FLOPs 所導致的。 #下圖5 展示了使用PC 度量後,可觀察的擴展定律的預測結果。可以發現,在兩個智能體基準上,使用 PC 度量的留出模型(GPT-4 或 Claude-2)的性能可以從更弱性能(10% 以上的差距)的模型中準確地預測。
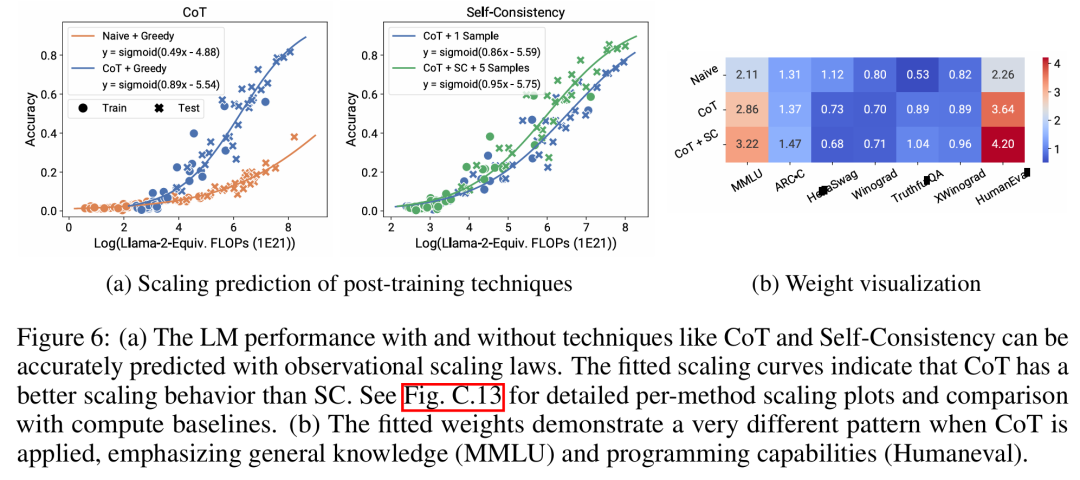
這表明 LMs 的更複雜智能體能力與它們的基礎模型能力息息相關,並且能夠基於後者進行預測。這也說明了隨著基幹 LMs 持續擴展規模,基於 LM 的智能體能力具有良好的擴展特性。 ####下圖6a 展示了使用可觀察的擴展定律,CoT 和SC(Self-Consistency,自洽性)的擴展預測結果。可以發現,使用CoT 和CoT+SC 但不使用(Naive)後訓練技術的更強、規模更大模型的性能可以從更弱、更小計算規模(例如模型大小和訓練FLOPs)的模型中準確預測出。 ###############值得注意的是,兩種技術之間的擴展趨勢不同,與使用 CoT 的自洽性相比,CoT 表現出更明顯的擴展趨勢。以上是從80個模型中建構Scaling Law:華人博士生新作,思維鏈提出者力薦的詳細內容。更多資訊請關注PHP中文網其他相關文章!