
Yann LeCun:ViT慢且效率低,即時影像處理還得看卷積

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-06-06 13:25:021140瀏覽
在 Transformer 大一統的時代,電腦視覺的 CNN 方向還有研究的必要嗎?
今年年初,OpenAI 視訊大模型 Sora 帶火了 Vision Transformer(ViT)架構。此後,關於 ViT 與傳統卷積神經網路(CNN)誰更厲害的爭論就沒有斷過。
近日,一直在社群媒體上活躍的圖靈獎得主、Meta 首席科學家 Yann LeCun 也加入了 ViT 與 CNN 之爭的討論。

這件事的起因是Comma.ai的CTO Harald Schäfer在展示自家最新研究。他(像最近很多AI學者一樣)cue了Yann LeCun表達,雖然圖靈獎大佬認為純ViT並不實用,但我們最近把自己的壓縮器改成了純ViT,沒有捷積,需要更長時間的訓練,但是效果非常好。
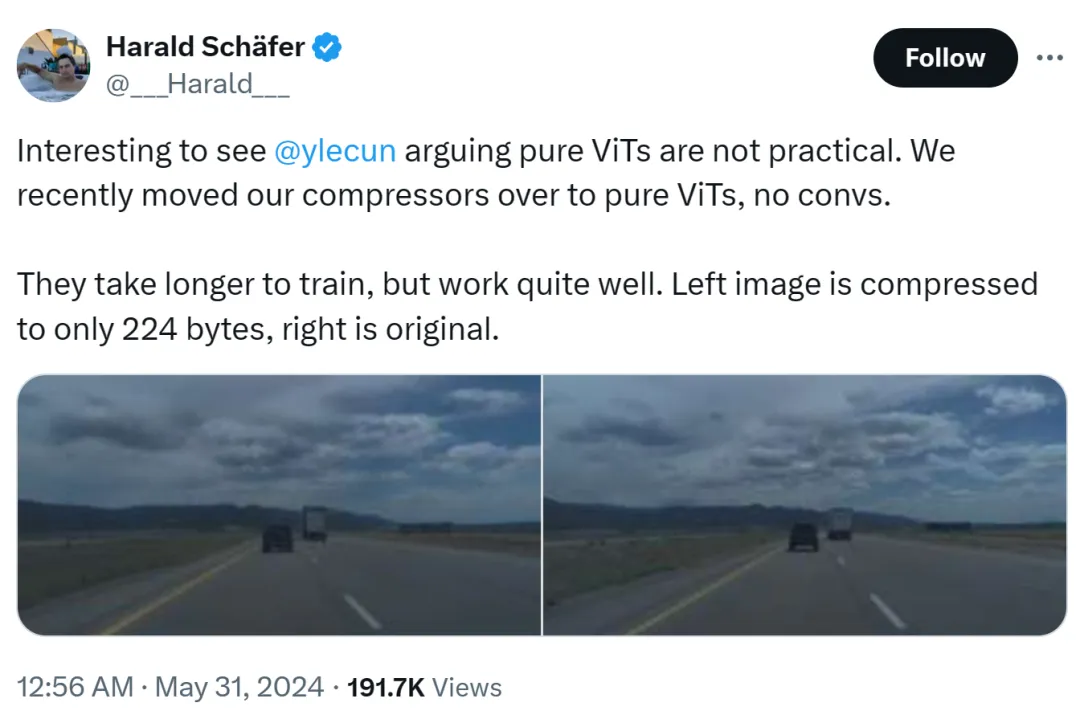
例如左圖,被壓縮到了只有 224 位元組,右邊是原始影像。
只有 14×128,這對自動駕駛用的世界模型來說很大,這意味著可以輸入大量資料進行訓練。在虛擬環境中訓練相比真實環境成本更低,在這裡 Agent 需要根據策略進行訓練才能正常運作。虛擬訓練更高的解析度效果會更好,但模擬器就會變得速度很慢,因此目前壓縮是必須的。
他的展示引發了 AI 圈的討論,1X 人工智慧副總裁 Eric Jang 回覆道,是驚人的結果。
Harald 繼續誇讚 ViT:這是非常美麗的架構。
這裡有人就開始拱火了:大師如 LeCun,有時也無法趕上創新的步伐。
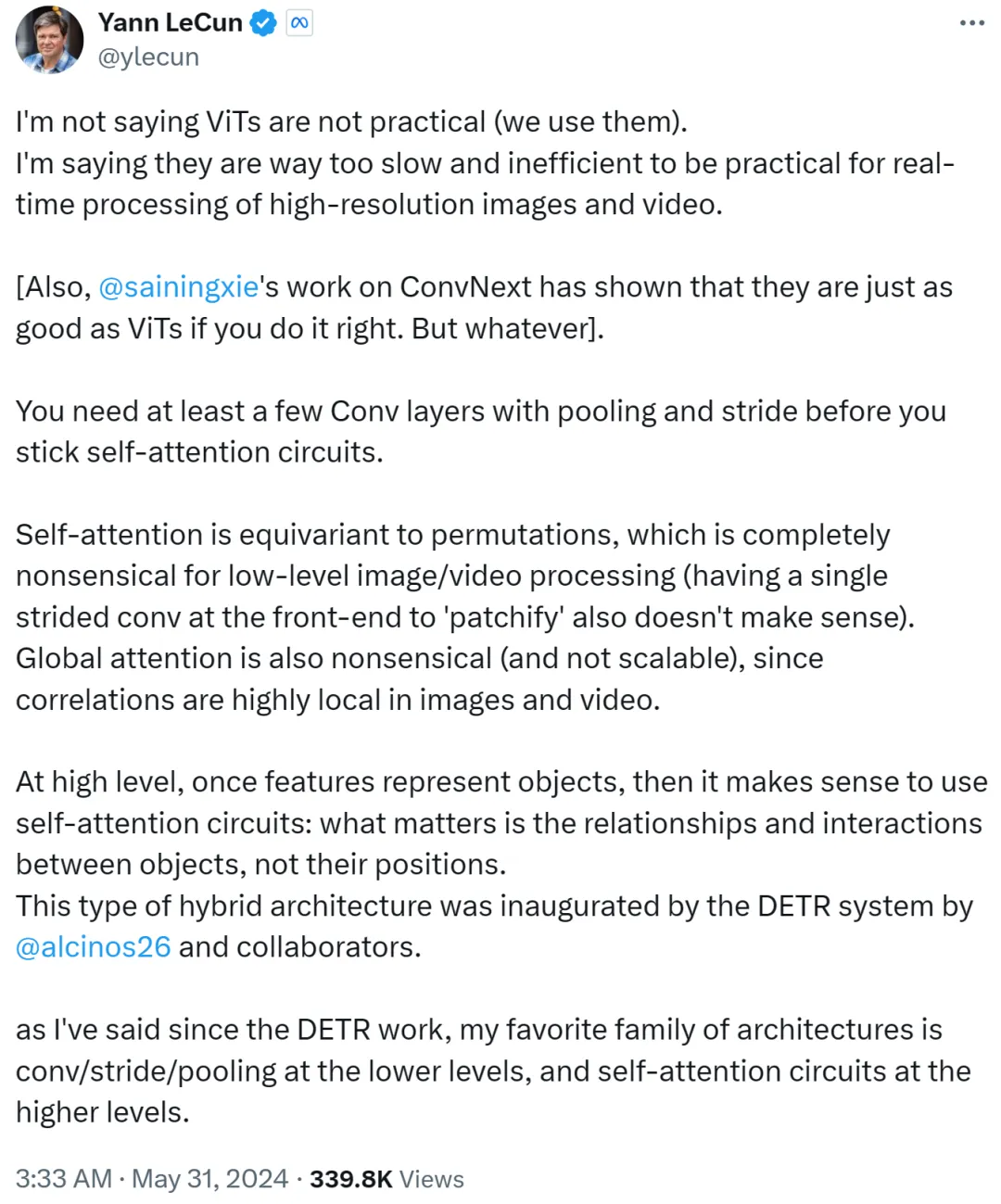
不過,Yann LeCun 很快回覆辯駁稱,他並不是說ViT 不實用,現在大家都在使用它。他想表達的是,ViT 太慢、效率太低,導致不適合即時處理高解析度影像和視訊任務。
Yann LeCun 也 Cue 了紐約大學助理教授謝賽寧,後者參與的工作 ConvNext 證明瞭如果方法得當,CNN 也能和 ViT 一樣好。
他接下來表示,在堅持自註意力循環之前,你至少需要幾個具有池化和步幅的捲積層。
如果自註意力等同於排列(permutation),則完全對低階影像或視訊處理沒有意義,在前端使用單一步幅進行修補(patchify)也沒有意義。此外由於影像或影片中的相關性高度集中在局部,因而全局注意力也沒有意義且不可擴展。
在更高層次上,一旦特徵表徵了對象,那麼使用自註意力循環就有意義了:重要的是對象之間的關係和交互,而非它們的位置。這種混合架構是由 Meta 研究科學家 Nicolas Carion 及合著者完成的 DETR 系統所開創的。
自 DETR 工作出現以後,Yann LeCun 表示自己最喜歡的架構是低階的捲積 / 步幅 / 池化,以及高層次的自註意力循環。
Yann LeCun 在第二個帖子中總結到:在低級別使用帶有步幅或池化的捲積,在高級別使用自註意力循環,並使用特徵向量來表徵物件。
他還打賭到,特斯拉全自動駕駛(FSD)在低級別使用卷積(或更複雜的局部運算符),並在更高級別結合更多全域循環(可能使用自註意力)。因此,低階 patch 嵌入上使用 Transformer 完全一種浪費。
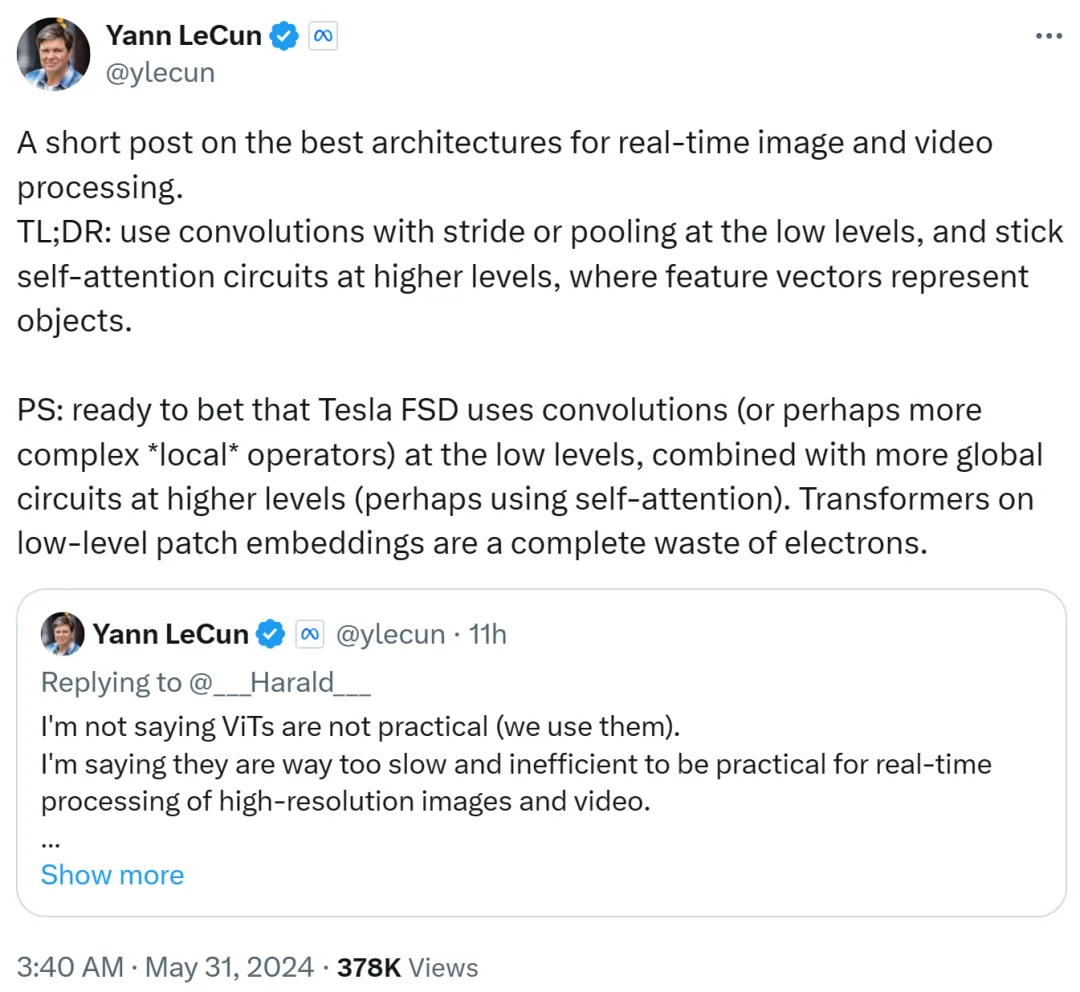
我猜死對頭馬斯克還是用的捲積路線。
謝賽寧也發表了自己的看法,他認為 ViT 非常適合 224x224 的低解析度影像,但如果影像解析度達到了 100 萬 x100 萬,該怎麼辦?這時要麼使用卷積,要麼使用共享權重對 ViT 進行修補和處理,這在本質上還是卷積。
因此,謝賽寧表示,有那麼一刻自己意識到卷積網路不是一種架構,而是一種思考方式。
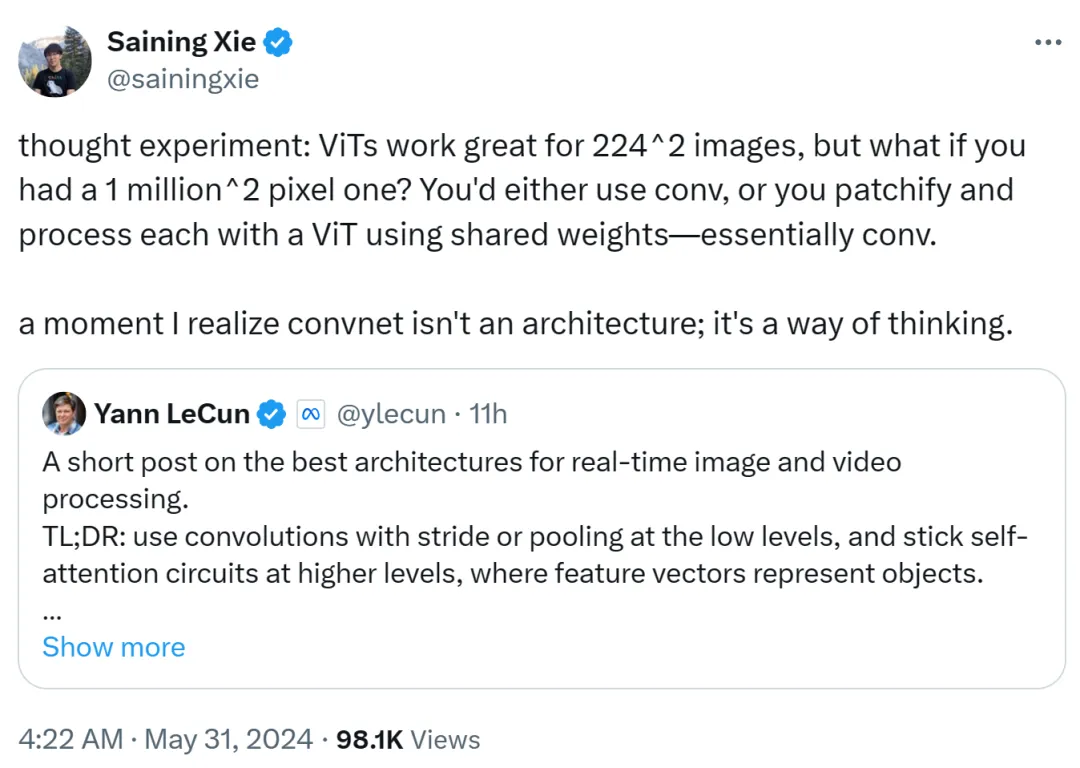
這一觀點得到了 Yann LeCun 的認可。

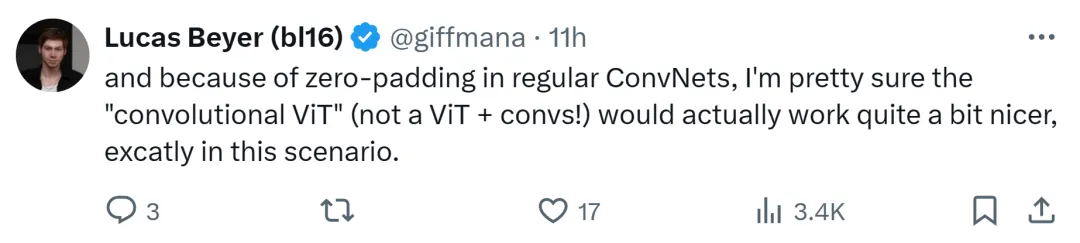
GoogleDeepMind 研究者Lucas Beyer 也表示,得益於常規卷積網路的零填充,自己很確定「卷積ViT」(而不是ViT + 卷積)會運作得很好。
可以預見,這場ViT 與CNN 之間的爭論將繼續下去,直到未來另一種更強大架構的出現。
以上是Yann LeCun:ViT慢且效率低,即時影像處理還得看卷積的詳細內容。更多資訊請關注PHP中文網其他相關文章!