



按照大語言模型的持續進化和自我革新,性能、準確度、穩定性都有了大幅的提升,這已經被各個基準問題集驗證過了。
但是,對於現有版本的 LLM 來說,它們的綜合能力似乎並不能完全支撐得起 AI 智能體。

多模態、多任務、多領域推論成為AI 智能體在公共傳媒空間內的必須要求,但是在具體的功能實踐中所展現的真實效果卻差異強烈。這似乎再次提醒各個 AI 智能體新創公司以及大型科技巨頭認清現實:腳踏實地一點,先別把攤子鋪得太大,從 AI 增強功能開始做起。
近日,一篇關於AI智能體在宣傳和真實表現上的差距的部落格中,強調了一個觀點:「AI智能體在宣傳上是個巨人,而現實卻很不妙。隨著科技的不斷進步,AI被賦予了許多令人矚目的特點和能力,然而實際應用中卻經常出現一些問題和
自主AI 智能體能夠夠執行複雜任務的背景已經引起極大的興奮。透過與外部工具和功能的交互,LLMs 可以在沒有人為幹預的情況下完成多步驟的工作流程。
但現實證明,這比預期的要更具挑戰性。
WebArena排行榜是一個真實可重複的網路環境,用於評估實用智能體的效能。對LLM智能體在現實任務中的表現進行了基準測試,結果顯示即使是表現最好的模型,成功率也只有35.8%。
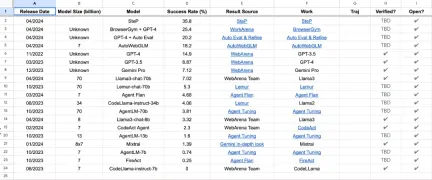
WebArena 排行榜對LLM 智能體在現實任務中的表現進行的基準測試結果:SteP 模型在成功率指標上表現最為良好,達到了35.8%,而知名的GPT-4 的成功率僅達到了14.9%。
什麼是 AI 智能體?
「AI 智能體」這個術語並沒有真正被定義,對智能體究竟是什麼也存在著很多的爭議。
AI 智能體可以定義為「一個被賦予行動能力的LLM(通常在RAG 環境中進行函數呼叫),以便在環境中對如何執行任務做出高層次的決策。模型處理整個任務,並基於其全面的上下文理解做出所有決策和行動。這種方法利用了大型模型的湧現能力,避免了將任務分解所帶來資訊的遺失。
多智能體系統:將任務分解為子任務,每個子任務由一個更小、更專業的智能體處理。與嘗試使用一個難以控制和測試的大型通用智能體相比,人們可以使用許多較小的智能體來為特定子任務選擇正確的策略。由於上下文視窗長度的限製或不同技能組合的需要等實際約束,這種方法有時是必要的。
- 理論上,具有無限上下文長度和完美注意力的單一智能體是理想的。由於上下文較短,在特定問題上,多智能體系統總是比單一系統效果差。
- 實踐中的挑戰
在見證了許多AI 智能體的嘗試之後,作者認為它們目前仍為時過早、成本過高、速度過慢且不夠可靠。許多 AI 智能體新創公司似乎在等待一個模型突破,以開啟智能體產品化的競賽。
AI 智能體在實際運用上的表現並不夠成熟,這體現在輸出不精確、效能差強人意、成本較高、賠償風險、無法獲得使用者信任等問題:
- 可靠性:眾所周知,LLMs 容易產生幻覺和不一致性。將多個 AI 步驟連接起來會加劇這些問題,尤其是對於需要精確輸出的任務。
- 效能和成本:GPT-4、Gemini-1.5 和Claude Opus 在使用工具/ 函數呼叫方面表現不錯,但它們仍然較慢且成本高,特別是如果需要進行循環和自動重試時。
- 法律問題:公司可能需要對其智能體的錯誤負責。最近的一個例子是,加拿大航空被命令向一位被航空公司聊天機器人誤導的客戶賠償。
- 使用者信任:AI 智能體的「黑箱」性質以及類似範例使得使用者難以理解和信任其輸出。在涉及付款或個人資訊的敏感任務中(如支付帳單、購物等),贏得用戶信任將會很困難。
現實世界中的嘗試
#目前,以下幾家新創公司正在涉足AI 智能體領域,但大多數仍處於實驗階段或僅限邀請使用:
- adept.ai - 融資3.5 億美元,但存取權限仍然非常有限。
- MultiOn - 融資情況未知,他們的 API 優先方法看起來很有前景。
- HypeWrite - 融資 280 萬美元,起初是一個 AI 寫作助手,後來擴展到智能體領域。
- minion.ai - 最初引起了一些關注,但現在已經沉寂,僅有等候名單。
它們中似乎只有 MultiOn 在追求「給予指令並觀察其執行」的方法,這與 AI 智能體的承諾更為一致。
其他所有公司都在走記錄和重播的 RPA(record-and-replay)路線,這在現階段可能是為保證可靠性所必需的。
同時,一些大公司也在將 AI 功能帶到桌面和瀏覽器,看起來將會在系統層面上獲得本地的 AI 整合。
OpenAI 宣布了他們的 Mac 桌面應用程序,可以與作業系統螢幕互動。
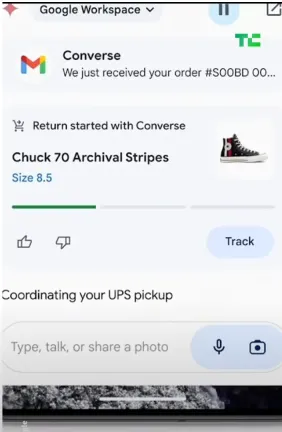
在 Google I/O 大會上,Google 示範了 Gemini 自動處理購物退貨。
微軟宣布了 Copilot Studio,它將允許開發人員建立 AI 智能體機器人。
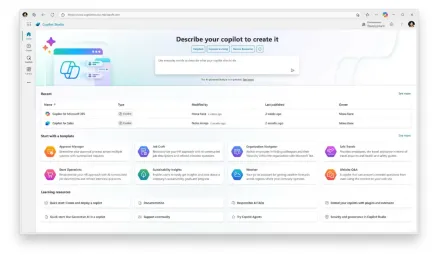
這些技術演示令人印象深刻,人們可以拭目以待這些智能體功能在公開發布並在真實場景中測試時的表現,而不是僅限於精心挑選的演示案例。
AI 智能體將走向哪條路?
作者強調:「AI 智能體被過度炒作了,大多數還沒有準備好用於關鍵任務。」
然而,隨著基礎模型和架構迅速進步,他表示人們仍可以期待看到更多成功的實際應用。
AI 智能體最有前途的前進道路可能是這樣的:
- 近期的重點應放在利用AI 增強現有工具,而不是提供廣泛的全自主獨立服務。
- 人機協同的方法,讓人類參與監督和處理邊緣案例。
- 根據目前的能力和限制,設定不脫離現實的期望。
透過結合嚴格約束的LLMs、良好的評估數據、人機協同監督和傳統工程方法,就可以在自動化等複雜任務方面實現可靠且良好的結果。
對於 AI 智能體是否會自動化乏味重複的工作,例如網頁抓取、填表和資料輸入?
作者:「是的,絕對會。」
那AI 智能體是否會在沒有人們幹預的情況下自動預訂假期?
作者:「至少在近期內不太可能。」
以上是AI智能體的炒作與現實:GPT-4都撐不起,現實任務成功率不到15%的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AM
ai合并图层的快捷键是什么Jan 07, 2021 am 10:59 AMai合并图层的快捷键是“Ctrl+Shift+E”,它的作用是把目前所有处在显示状态的图层合并,在隐藏状态的图层则不作变动。也可以选中要合并的图层,在菜单栏中依次点击“窗口”-“路径查找器”,点击“合并”按钮。
 ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AM
ai橡皮擦擦不掉东西怎么办Jan 13, 2021 am 10:23 AMai橡皮擦擦不掉东西是因为AI是矢量图软件,用橡皮擦不能擦位图的,其解决办法就是用蒙板工具以及钢笔勾好路径再建立蒙板即可实现擦掉东西。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PM
ai可以转成psd格式吗Feb 22, 2023 pm 05:56 PMai可以转成psd格式。转换方法:1、打开Adobe Illustrator软件,依次点击顶部菜单栏的“文件”-“打开”,选择所需的ai文件;2、点击右侧功能面板中的“图层”,点击三杠图标,在弹出的选项中选择“释放到图层(顺序)”;3、依次点击顶部菜单栏的“文件”-“导出”-“导出为”;4、在弹出的“导出”对话框中,将“保存类型”设置为“PSD格式”,点击“导出”即可;
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
 ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PM
ai顶部属性栏不见了怎么办Feb 22, 2023 pm 05:27 PMai顶部属性栏不见了的解决办法:1、开启Ai新建画布,进入绘图页面;2、在Ai顶部菜单栏中点击“窗口”;3、在系统弹出的窗口菜单页面中点击“控制”,然后开启“控制”窗口即可显示出属性栏。
 ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AM
ai移动不了东西了怎么办Mar 07, 2023 am 10:03 AMai移动不了东西的解决办法:1、打开ai软件,打开空白文档;2、选择矩形工具,在文档中绘制矩形;3、点击选择工具,移动文档中的矩形;4、点击图层按钮,弹出图层面板对话框,解锁图层;5、点击选择工具,移动矩形即可。
 强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM
强化学习再登Nature封面,自动驾驶安全验证新范式大幅减少测试里程Mar 31, 2023 pm 10:38 PM引入密集强化学习,用 AI 验证 AI。 自动驾驶汽车 (AV) 技术的快速发展,使得我们正处于交通革命的风口浪尖,其规模是自一个世纪前汽车问世以来从未见过的。自动驾驶技术具有显着提高交通安全性、机动性和可持续性的潜力,因此引起了工业界、政府机构、专业组织和学术机构的共同关注。过去 20 年里,自动驾驶汽车的发展取得了长足的进步,尤其是随着深度学习的出现更是如此。到 2015 年,开始有公司宣布他们将在 2020 之前量产 AV。不过到目前为止,并且没有 level 4 级别的 AV 可以在市场


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

Dreamweaver Mac版
視覺化網頁開發工具

