



关于Pacemaker集群配置的版本
Pacemaker中CIB有一个由admin_epoch, epoch, num_updates组合而成的版本,当有节点加入集群时,根据版本号的大小,取其中版本最大的作为整个集群的统一配置。admin_epoch, epoch, num_updates这3者中,admin_epoch通常是不会变的,epoch在每次"配置"变更时累加并把num_updates置0,num_updates在每次"状态"变更时累加。"配置"指持久的CIB中configuration节点下的内容,包括cluster属性,node的forever属性,资源属性等。"状态"指node的reboot属性,node死活,资源是否启动等动态的东西。
"状态"通常是可以通过monitor重新获取的(除非RA脚本设计的有问题),但"配置"出错可能会导致集群的故障,所以我们更需要关心epoch的变更以及节点加入后对集群配置的影响。尤其一些支持主从架构的RA脚本会动态修改配置(比如mysql的mysql_REPL_INFO
和pgsql的pgsql-data-status),一旦配置处于不一致状态可能会导致集群故障。
1. 手册说明
http://clusterlabs.org/doc/en-US/Pacemaker/1.1-plugin/html-single/Pacemaker_Explained/index.html#idm140225199219024
3.2.Configuration Version When a node joins the cluster, the cluster will perform a check to see who has the best configuration based on the fields below. It then asks the node with the highest (admin_epoch,epoch,num_updates) tuple to replace the configuration on all the nodes - which makes setting them, and setting them correctly, very important.
Table3.1.Configuration Version Properties
| Field | Description |
|---|---|
| admin_epoch | Never modified by the cluster. Use this to make the configurations on any inactive nodes obsolete.Never set this value to zero, in such cases the cluster cannot tell the difference between your configuration and the "empty" one used when nothing is found on disk. |
| epoch | Incremented every time the configuration is updated (usually by the admin) |
| num_updates | Incremented every time the configuration or status is updated (usually by the cluster) |
2.实际验证
2.1 环境
3台机器,srdsdevapp69,srdsdevapp71和srdsdevapp73OS: CentOS 6.3
Pacemaker: 1.1.14-1.el6 (Build: 70404b0)
Corosync: 1.4.1-7.el6
2.2 基本验证
0. 初始时epoch="48304",num_updates="4"- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
1. 更新集群配置导致epoch加1并将num_updates清0
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo1 -v "1"
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
2. 更新值如果和现有值相同epoch不变
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo1 -v "1"
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
3. 更新生命周期为forever的节点属性也导致epoch加1
- [root@srdsdevapp69 mysql_ha]# crm_attribute -N `hostname` -l forever -n foo2 -v 2
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
4. 更新生命周期为reboot的节点属性导致num_updates加1
- [root@srdsdevapp69 mysql_ha]# crm_attribute -N `hostname` -l reboot -n foo3 -v 2
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
2.3 分区验证
1. 人为造成srdsdevapp69和其它两个节点的网络隔离形成分区,分区前的DC(Designated Controller)为srdsdevapp73- [root@srdsdevapp69 mysql_ha]# iptables -A INPUT -j DROP -s srdsdevapp71
- [root@srdsdevapp69 mysql_ha]# iptables -A OUTPUT -j DROP -s srdsdevapp71
- [root@srdsdevapp69 mysql_ha]# iptables -A INPUT -j DROP -s srdsdevapp73
- [root@srdsdevapp69 mysql_ha]# iptables -A OUTPUT -j DROP -s srdsdevapp73
分区1(srdsdevapp69) : 未取得QUORUM
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
分区2(srdsdevapp71,srdsdevapp73) : 取得QUORUM
- [root@srdsdevapp71 ~]# cibadmin -Q |grep epoch
2. 在srdsdevapp69上做2次配置更新,使其epoch增加2
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo4 -v "1"
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo5 -v "1"
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
3.在srdsdevapp71上做1次配置更新,使其epoch增加1
- [root@srdsdevapp71 ~]# crm_attribute --type crm_config -s set1 --name foo6 -v "1"
- [root@srdsdevapp71 ~]# cibadmin -Q |grep epoch
4.恢复网络再检查集群的配置
- [root@srdsdevapp69 mysql_ha]# iptables -F
- [root@srdsdevapp69 mysql_ha]# cibadmin -Q |grep epoch
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo5 -q
- 1
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo4 -q
- 1
- [root@srdsdevapp69 mysql_ha]# crm_attribute --type crm_config -s set1 --name foo6 -q
- Error performing operation: No such device or address
这个测试反映了一个问题:取得QUORUM的分区配置可能会被未取得QUORUM的分区配置覆盖。如果自己开发RA的话,这是一个需要注意的问题。
2.4 分区验证2
前一个测试中,产生分区前的DC在取得QUORUM的分区中,现在再试一下产生分区前的DC在未取得QUORUM的分区中的场景。1. 人为造成DC(srdsdevapp73)和其它两个节点的网络隔离形成分区
- [root@srdsdevapp73 ~]# iptables -A INPUT -j DROP -s srdsdevapp69
- [root@srdsdevapp73 ~]# iptables -A OUTPUT -j DROP -s srdsdevapp69
- [root@srdsdevapp73 ~]# iptables -A INPUT -j DROP -s srdsdevapp71
- [root@srdsdevapp73 ~]# iptables -A OUTPUT -j DROP -s srdsdevapp71
- [root@srdsdevapp73 ~]# cibadmin -Q |grep epoch
但另一个分区(srdsdevapp69,srdsdevapp71)上的epoch加1了
- [root@srdsdevapp69 ~]# cibadmin -Q |grep epoch
恢复网络后集群采用了版本号更高的配置,DC仍然是分区前的DC(srdsdevapp73)
- [root@srdsdevapp73 ~]# iptables -F
- [root@srdsdevapp73 ~]# cibadmin -Q |grep epoch
通过这个测试可以发现:
- DC协商会导致epoch加1
- 分区恢复后,Pacemaker倾向于使分区前的DC作为新的DC
3.总结
Pacemaker的行为特征- CIB配置变更会导致epoch加1
- DC协商会导致epoch加1
- 分区恢复后,Pacemaker采取版本号大的作为集群的配置
- 分区恢复后,Pacemaker倾向于使分区前的DC作为新的DC
开发RA的注意点
- 尽量避免动态修改集群配置
- 如果做不到第一点,尽量避免使用多个动态集群配置参数,比如可以把多个参数拼接成一个(mysql的mysql_REPL_INFO就是这么干的)
- 检查crm_attribute的出错并重试(pgsql就是这么干的)
- 失去quorum时的资源停止处理(demote,stop)中避免修改集群配置

 如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM
如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM根据美国司法部的解释,蓝色警报旨在提供关于可能对执法人员构成直接和紧急威胁的个人的重要信息。这种警报的目的是及时通知公众,并让他们了解与这些罪犯相关的潜在危险。通过这种主动的方式,蓝色警报有助于增强社区的安全意识,促使人们采取必要的预防措施以保护自己和周围的人。这种警报系统的建立旨在提高对潜在威胁的警觉性,并加强执法机构与公众之间的沟通,以共尽管这些紧急通知对我们社会至关重要,但有时可能会对日常生活造成干扰,尤其是在午夜或重要活动时收到通知时。为了确保安全,我们建议您保持这些通知功能开启,但如果
 在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PM
在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PMAndroid中的轮询是一项关键技术,它允许应用程序定期从服务器或数据源检索和更新信息。通过实施轮询,开发人员可以确保实时数据同步并向用户提供最新的内容。它涉及定期向服务器或数据源发送请求并获取最新信息。Android提供了定时器、线程、后台服务等多种机制来高效地完成轮询。这使开发人员能够设计与远程数据源保持同步的响应式动态应用程序。本文探讨了如何在Android中实现轮询。它涵盖了实现此功能所涉及的关键注意事项和步骤。轮询定期检查更新并从服务器或源检索数据的过程在Android中称为轮询。通过
 如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM
如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM为了提升用户体验并防止数据或进度丢失,Android应用程序开发者必须避免意外退出。他们可以通过加入“再次按返回退出”功能来实现这一点,该功能要求用户在特定时间内连续按两次返回按钮才能退出应用程序。这种实现显著提升了用户参与度和满意度,确保他们不会意外丢失任何重要信息Thisguideexaminesthepracticalstepstoadd"PressBackAgaintoExit"capabilityinAndroid.Itpresentsasystematicguid
 Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM
Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM1.java复杂类如果有什么地方不懂,请看:JAVA总纲或者构造方法这里贴代码,很简单没有难度。2.smali代码我们要把java代码转为smali代码,可以参考java转smali我们还是分模块来看。2.1第一个模块——信息模块这个模块就是基本信息,说明了类名等,知道就好对分析帮助不大。2.2第二个模块——构造方法我们来一句一句解析,如果有之前解析重复的地方就不再重复了。但是会提供链接。.methodpublicconstructor(Ljava/lang/String;I)V这一句话分为.m
 如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM
如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM如何将WhatsApp聊天从Android转移到iPhone?你已经拿到了新的iPhone15,并且你正在从Android跳跃?如果是这种情况,您可能还对将WhatsApp从Android转移到iPhone感到好奇。但是,老实说,这有点棘手,因为Android和iPhone的操作系统不兼容。但不要失去希望。这不是什么不可能完成的任务。让我们在本文中讨论几种将WhatsApp从Android转移到iPhone15的方法。因此,坚持到最后以彻底学习解决方案。如何在不删除数据的情况下将WhatsApp
 同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM
同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM原因:1、安卓系统上设置了一个JAVA虚拟机来支持Java应用程序的运行,而这种虚拟机对硬件的消耗是非常大的;2、手机生产厂商对安卓系统的定制与开发,增加了安卓系统的负担,拖慢其运行速度影响其流畅性;3、应用软件太臃肿,同质化严重,在一定程度上拖慢安卓手机的运行速度。
 Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM
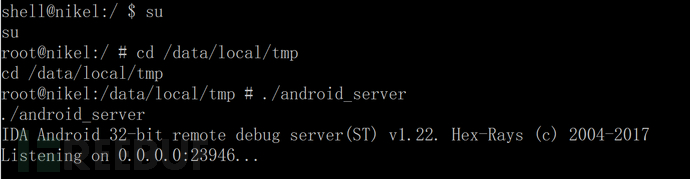
Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM1.启动ida端口监听1.1启动Android_server服务1.2端口转发1.3软件进入调试模式2.ida下断2.1attach附加进程2.2断三项2.3选择进程2.4打开Modules搜索artPS:小知识Android4.4版本之前系统函数在libdvm.soAndroid5.0之后系统函数在libart.so2.5打开Openmemory()函数在libart.so中搜索Openmemory函数并且跟进去。PS:小知识一般来说,系统dex都会在这个函数中进行加载,但是会出现一个问题,后
 Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM
Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM1.自动化测试自动化测试主要包括几个部分,UI功能的自动化测试、接口的自动化测试、其他专项的自动化测试。1.1UI功能自动化测试UI功能的自动化测试,也就是大家常说的自动化测试,主要是基于UI界面进行的自动化测试,通过脚本实现UI功能的点击,替代人工进行自动化测试。这个测试的优势在于对高度重复的界面特性功能测试的测试人力进行有效的释放,利用脚本的执行,实现功能的快速高效回归。但这种测试的不足之处也是显而易见的,主要包括维护成本高,易发生误判,兼容性不足等。因为是基于界面操作,界面的稳定程度便成了


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver Mac版
視覺化網頁開發工具

SublimeText3漢化版
中文版,非常好用

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

