


超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件、目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问、操作,从而获取我们想要的内容。对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了。
首先要说明的是,urllib2并非是urllib的升级版,虽然同样作为处理url的相关模块,个人推荐尽量使用urllib2的接口,但我们并不能用urllib2完全代替urllib,处理URL资源有时会需要urllib中的一些函数(如urllib.urllencode)来处理数据。但二者处理url的大致思想都是通过底层封装好的接口让我们能够对url像对本地文件一样进行读取等操作。
下面就是一个获取百度页面内容的代码:
import urllib2
connect= urllib2.Request('http://www.baidu.com')
url1 = urllib2.urlopen(connect)
print url.read()
短短4行在运行之后,就会显示出百度页面的源代码。它的机理是什么呢?
当我们使用urllib2.Request的命令时,我们就向百度搜索的url(“www.baidu.com”)发出了一次HTTP请求,并将该请求映射到connect变量中,当我们使用urllib2.urlopen操作connect后,就会将connect的值返回到url1中,然后我们就可以像操作本地文件一样对url1进行操作,比如这里我们就使用了read()函数来读取该url的源代码。
这样,我们就可以写一只属于自己的简单爬虫了~下面是我写的抓取天涯连载的爬虫:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen(a)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
事实上,上面的代码使用urlopen就可以达到相同的效果了:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
#a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen((url1+str(i)+url3)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
为什么我们还需要先对url进行request处理呢?这里需要引入opener的概念,当我们使用urllib处理url的时候,实际上是通过urllib2.OpenerDirector实例进行工作,他会自己调用资源进行各种操作如通过协议、打开url、处理cookie等。而urlopen方法使用的是默认的opener来处理问题,也就是说,相当的简单粗暴~对于我们post数据、设置header、设置代理等需求完全满足不了。
因此,当面对稍微高点的需求时,我们就需要通过urllib2.build_opener()来创建属于自己的opener,这部分内容我会在下篇博客中详细写~
而对于一些没有特别要求的网站,仅仅使用urllib的2个模块其实就可以获取到我们想要的信息了,但是一些需要模拟登陆或者需要权限的网站,就需要我们处理cookies后才能顺利抓取上面的信息,这时候就需要Cookielib模块了。cookielib 模块就是专门用来处理cookie相关了,其中比较常用的方法就是能够自动处理cookie的CookieJar()了,它可以自动存储HTTP请求生成的cookie,并向传出HTTP的请求中自动添加cookie。正如我前文所提到的,想要使用它的话,需要创建一个新的opener:
import cookielib, urllib2 cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
经过这样的处理后,cookie的问题就解决了~
而想要将cookies输出出来的话,使用print cj._cookies.values()命令后就可以了~
抓取豆瓣同城、登陆图书馆查询图书归还
在掌握了urllib几个模块的相关用法后,接下来就是进入实战步骤了~
(一)抓取豆瓣网站同城活动
豆瓣北京同城活动 该链接指向豆瓣同城活动的列表,向该链接发起request:
# encoding=utf-8 import urllib import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) url="http://beijing.douban.com/events/future-all?start=0" req=urllib2.Request(url) event=urllib2.urlopen(req) str1=event.read()
我们会发现返回的html代码中,除了我们需要的信息之外,还夹杂了大量的页面布局代码:

如上图所示,我们只需要中间那些关于活动的信息。而为了提取信息,我们就需要正则表达式了~
正则表达式是一种跨平台的字符串处理工具/方法,通过正则表达式,我们可以比较轻松的提取字符串中我们想要的内容~
这里不做详细介绍了,个人推荐余晟老师的正则指引,挺适合新手入门的。下面给出正则表达式的大致语法:
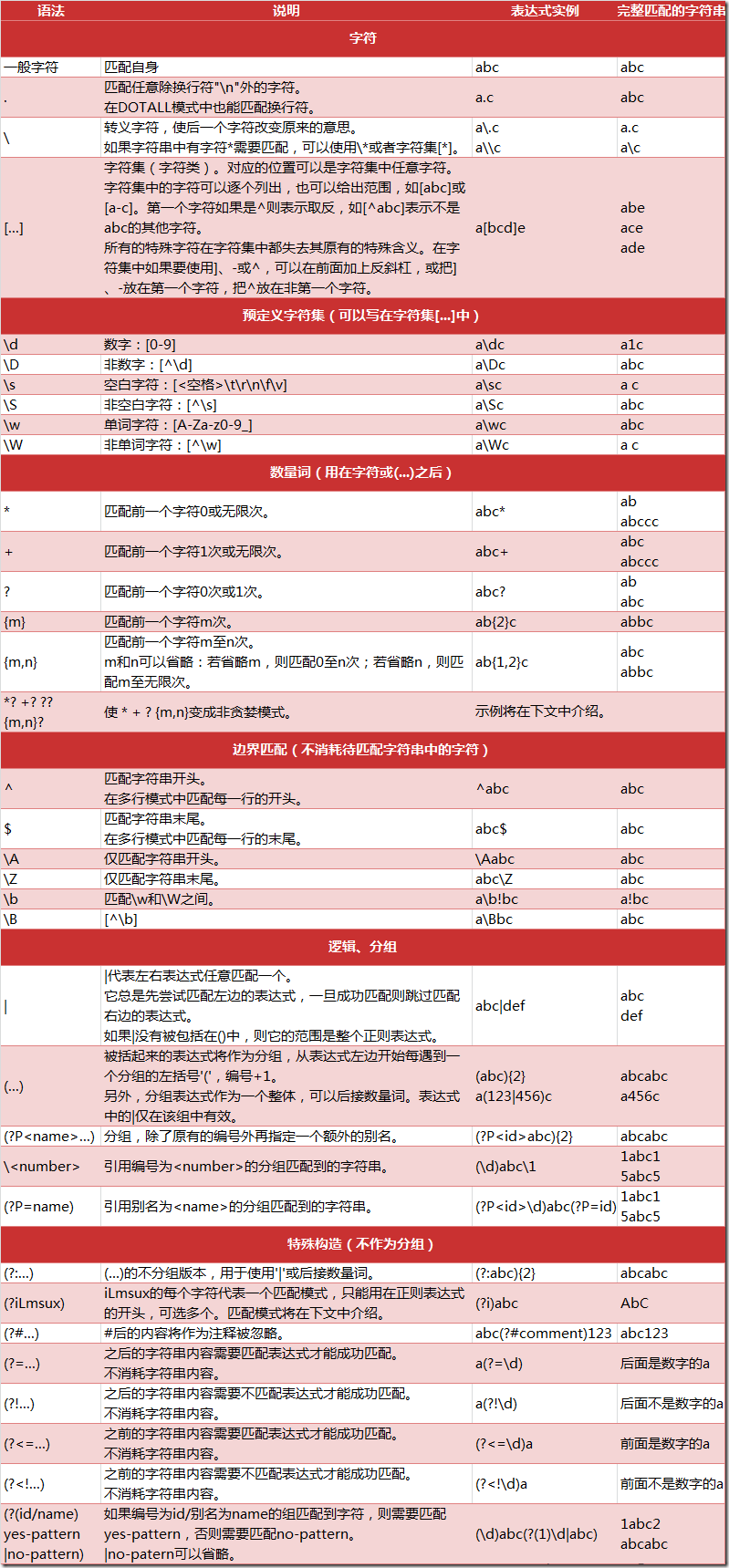
这里我使用捕获分组,将活动四要素(名称,时间,地点,费用)为标准进行分组,得到的表达式如下:
regex=re.compile(r'summary">([\d\D]*?)[\d\D]*?class="hidden-xs">([\d\D]*?)

 为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM
为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM报错的原因NameResolutionError(self.host,self,e)frome是由urllib3库中的异常类型,这个错误的原因是DNS解析失败,也就是说,试图解析的主机名或IP地址无法找到。这可能是由于输入的URL地址不正确,或者DNS服务器暂时不可用导致的。如何解决解决此错误的方法可能有以下几种:检查输入的URL地址是否正确,确保它是可访问的确保DNS服务器可用,您可以尝试在命令行中使用"ping"命令来测试DNS服务器是否可用尝试使用IP地址而不是主机名来访问网站如果是在代理
 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 详细了解Python进程池与进程锁May 10, 2022 pm 06:11 PM
详细了解Python进程池与进程锁May 10, 2022 pm 06:11 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于进程池与进程锁的相关问题,包括进程池的创建模块,进程池函数等等内容,下面一起来看一下,希望对大家有帮助。

 Python的HTTP客户端模块urllib与urllib3怎么使用May 20, 2023 pm 07:58 PM
Python的HTTP客户端模块urllib与urllib3怎么使用May 20, 2023 pm 07:58 PM一、urllib概述:urllib是Python中请求url连接的官方标准库,就是你安装了python,这个库就已经可以直接使用了,基本上涵盖了基础的网络请求功能。在Python2中主要为urllib和urllib2,在Python3中整合成了urllib。Python3.x中将urllib2合并到了urllib,之后此包分成了以下四个模块:urllib.request:它是最基本的http请求模块,用来模拟发送请求urllib.error:异常处理模块,如果出现错误可以捕获这些异常urllib
 Python 3.x 中如何使用urllib.request.urlopen()函数发送GET请求Jul 30, 2023 am 11:28 AM
Python 3.x 中如何使用urllib.request.urlopen()函数发送GET请求Jul 30, 2023 am 11:28 AMPython3.x中如何使用urllib.request.urlopen()函数发送GET请求在网络编程中,我们经常需要通过发送HTTP请求来获取远程服务器的数据。在Python中,我们可以使用urllib模块中的urllib.request.urlopen()函数来发送HTTP请求,并获取服务器返回的响应。本文将介绍如何使用
 Python数据类型详解之字符串、数字Apr 27, 2022 pm 07:27 PM
Python数据类型详解之字符串、数字Apr 27, 2022 pm 07:27 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于数据类型之字符串、数字的相关问题,下面一起来看一下,希望对大家有帮助。
 Python 3.x 中如何使用urllib.request.urlopen()函数发送POST请求Jul 31, 2023 pm 07:10 PM
Python 3.x 中如何使用urllib.request.urlopen()函数发送POST请求Jul 31, 2023 pm 07:10 PMPython3.x中如何使用urllib.request.urlopen()函数发送POST请求在网络编程中,常常需要通过HTTP协议发送POST请求来与服务器进行交互。Python提供了urllib.request.urlopen()函数来发送各种HTTP请求,其中包括POST请求。本文将详细介绍如何使用urllib.request.urlop


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3漢化版
中文版,非常好用

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

Atom編輯器mac版下載
最受歡迎的的開源編輯器

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

