


本文实例讲解的是一般的hadoop入门程序“WordCount”,就是首先写一个map程序用来将输入的字符串分割成单个的单词,然后reduce这些单个的单词,相同的单词就对其进行计数,不同的单词分别输出,结果输出每一个单词出现的频数。
注意:关于数据的输入输出是通过sys.stdin(系统标准输入)和sys.stdout(系统标准输出)来控制数据的读入与输出。所有的脚本执行之前都需要修改权限,否则没有执行权限,例如下面的脚本创建之前使用“chmod +x mapper.py”
1.mapper.py
#!/usr/bin/env python
import sys
for line in sys.stdin: # 遍历读入数据的每一行
line = line.strip() # 将行尾行首的空格去除
words = line.split() #按空格将句子分割成单个单词
for word in words:
print '%s\t%s' %(word, 1)
2.reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None # 为当前单词
current_count = 0 # 当前单词频数
word = None
for line in sys.stdin:
words = line.strip() # 去除字符串首尾的空白字符
word, count = words.split('\t') # 按照制表符分隔单词和数量
try:
count = int(count) # 将字符串类型的‘1'转换为整型1
except ValueError:
continue
if current_word == word: # 如果当前的单词等于读入的单词
current_count += count # 单词频数加1
else:
if current_word: # 如果当前的单词不为空则打印其单词和频数
print '%s\t%s' %(current_word, current_count)
current_count = count # 否则将读入的单词赋值给当前单词,且更新频数
current_word = word
if current_word == word:
print '%s\t%s' %(current_word, current_count)
在shell中运行以下脚本,查看输出结果:
echo "foo foo quux labs foo bar zoo zoo hying" | /home/wuying/mapper.py | sort -k 1,1 | /home/wuying/reducer.py # echo是将后面“foo ****”字符串输出,并利用管道符“|”将输出数据作为mapper.py这个脚本的输入数据,并将mapper.py的数据输入到reducer.py中,其中参数sort -k 1,1是将reducer的输出内容按照第一列的第一个字母的ASCII码值进行升序排序
其实,我觉得后面这个reducer.py处理单词频数有点麻烦,将单词存储在字典里面,单词作为‘key',每一个单词出现的频数作为'value',进而进行频数统计感觉会更加高效一点。因此,改进脚本如下:
mapper_1.py
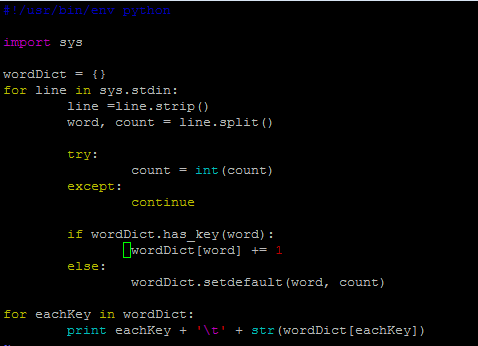
但是,貌似写着写着用了两个循环,反而效率低了。关键是不太明白这里的current_word和current_count的作用,如果从字面上老看是当前存在的单词,那么怎么和遍历读取的word和count相区别?
下面看一些脚本的输出结果:
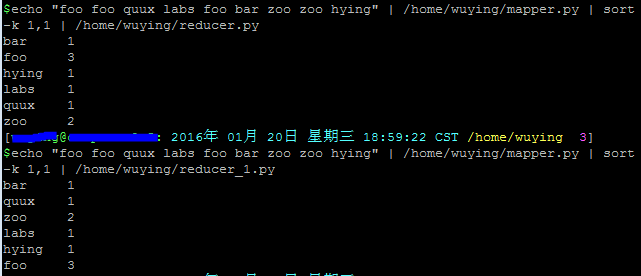
我们可以看到,上面同样的输入数据,同样的shell换了不同的reducer,结果后者并没有对数据进行排序,实在是费解~
让Python代码在hadoop上跑起来!
一、准备输入数据
接下来,先下载三本书:
$ mkdir -p tmp/gutenberg $ cd tmp/gutenberg $ wget http://www.gutenberg.org/ebooks/20417.txt.utf-8 $ wget http://www.gutenberg.org/files/5000/5000-8.txt $ wget http://www.gutenberg.org/ebooks/4300.txt.utf-8
然后把这三本书上传到hdfs文件系统上:
$ hdfs dfs -mkdir /user/${whoami}/input # 在hdfs上的该用户目录下创建一个输入文件的文件夹
$ hdfs dfs -put /home/wuying/tmp/gutenberg/*.txt /user/${whoami}/input # 上传文档到hdfs上的输入文件夹中
寻找你的streaming的jar文件存放地址,注意2.6的版本放到share目录下了,可以进入hadoop安装目录寻找该文件:
$ cd $HADOOP_HOME $ find ./ -name "*streaming*"
然后就会找到我们的share文件夹中的hadoop-straming*.jar文件:
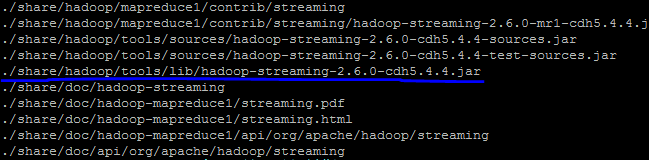
寻找速度可能有点慢,因此你最好是根据自己的版本号到对应的目录下去寻找这个streaming文件,由于这个文件的路径比较长,因此我们可以将它写入到环境变量:
$ vi ~/.bashrc # 打开环境变量配置文件 # 在里面写入streaming路径 export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
由于通过streaming接口运行的脚本太长了,因此直接建立一个shell名称为run.sh来运行:
hadoop jar $STREAM \ -files ./mapper.py,./reducer.py \ -mapper ./mapper.py \ -reducer ./reducer.py \ -input /user/$(whoami)/input/*.txt \ -output /user/$(whoami)/output
然后"source run.sh"来执行mapreduce。结果就响当当的出来啦。这里特别要提醒一下:
1、一定要把本地的输入文件转移到hdfs系统上面,否则无法识别你的input内容;
2、一定要有权限,一定要在你的hdfs系统下面建立你的个人文件夹否则就会被denied,是的,就是这两个错误搞得我在服务器上面痛不欲生,四处问人的感觉真心不如自己清醒对待来的好;
3、如果你是第一次在服务器上面玩hadoop,建议在这之前请在自己的虚拟机或者linux系统上面配置好伪分布式然后入门hadoop来的比较不那么头疼,之前我并不知道我在服务器上面运维没有给我运行的权限,后来在自己的虚拟机里面运行一下example实例以及wordcount才找到自己的错误。
好啦,然后不出意外,就会complete啦,你就可以通过如下方式查看计数结果:
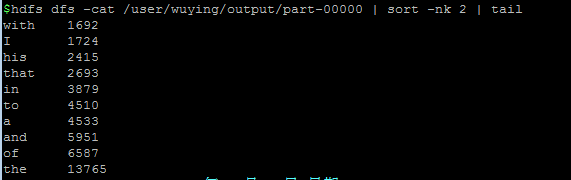
以上就是本文的全部内容,希望对大家学习python软件编程有所帮助。

 學習Python:2小時的每日學習是否足夠?Apr 18, 2025 am 12:22 AM
學習Python:2小時的每日學習是否足夠?Apr 18, 2025 am 12:22 AM每天學習Python兩個小時是否足夠?這取決於你的目標和學習方法。 1)制定清晰的學習計劃,2)選擇合適的學習資源和方法,3)動手實踐和復習鞏固,可以在這段時間內逐步掌握Python的基本知識和高級功能。
 Web開發的Python:關鍵應用程序Apr 18, 2025 am 12:20 AM
Web開發的Python:關鍵應用程序Apr 18, 2025 am 12:20 AMPython在Web開發中的關鍵應用包括使用Django和Flask框架、API開發、數據分析與可視化、機器學習與AI、以及性能優化。 1.Django和Flask框架:Django適合快速開發複雜應用,Flask適用於小型或高度自定義項目。 2.API開發:使用Flask或DjangoRESTFramework構建RESTfulAPI。 3.數據分析與可視化:利用Python處理數據並通過Web界面展示。 4.機器學習與AI:Python用於構建智能Web應用。 5.性能優化:通過異步編程、緩存和代碼優
 Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AMPython在開發效率上優於C ,但C 在執行性能上更高。 1.Python的簡潔語法和豐富庫提高開發效率。 2.C 的編譯型特性和硬件控制提升執行性能。選擇時需根據項目需求權衡開發速度與執行效率。
 python在行動中:現實世界中的例子Apr 18, 2025 am 12:18 AM
python在行動中:現實世界中的例子Apr 18, 2025 am 12:18 AMPython在現實世界中的應用包括數據分析、Web開發、人工智能和自動化。 1)在數據分析中,Python使用Pandas和Matplotlib處理和可視化數據。 2)Web開發中,Django和Flask框架簡化了Web應用的創建。 3)人工智能領域,TensorFlow和PyTorch用於構建和訓練模型。 4)自動化方面,Python腳本可用於復製文件等任務。
 Python的主要用途:綜合概述Apr 18, 2025 am 12:18 AM
Python的主要用途:綜合概述Apr 18, 2025 am 12:18 AMPython在數據科學、Web開發和自動化腳本領域廣泛應用。 1)在數據科學中,Python通過NumPy、Pandas等庫簡化數據處理和分析。 2)在Web開發中,Django和Flask框架使開發者能快速構建應用。 3)在自動化腳本中,Python的簡潔性和標準庫使其成為理想選擇。
 Python的主要目的:靈活性和易用性Apr 17, 2025 am 12:14 AM
Python的主要目的:靈活性和易用性Apr 17, 2025 am 12:14 AMPython的靈活性體現在多範式支持和動態類型系統,易用性則源於語法簡潔和豐富的標準庫。 1.靈活性:支持面向對象、函數式和過程式編程,動態類型系統提高開發效率。 2.易用性:語法接近自然語言,標準庫涵蓋廣泛功能,簡化開發過程。
 Python:多功能編程的力量Apr 17, 2025 am 12:09 AM
Python:多功能編程的力量Apr 17, 2025 am 12:09 AMPython因其簡潔與強大而備受青睞,適用於從初學者到高級開發者的各種需求。其多功能性體現在:1)易學易用,語法簡單;2)豐富的庫和框架,如NumPy、Pandas等;3)跨平台支持,可在多種操作系統上運行;4)適合腳本和自動化任務,提升工作效率。
 每天2小時學習Python:實用指南Apr 17, 2025 am 12:05 AM
每天2小時學習Python:實用指南Apr 17, 2025 am 12:05 AM可以,在每天花費兩個小時的時間內學會Python。 1.制定合理的學習計劃,2.選擇合適的學習資源,3.通過實踐鞏固所學知識,這些步驟能幫助你在短時間內掌握Python。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

記事本++7.3.1
好用且免費的程式碼編輯器

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

WebStorm Mac版
好用的JavaScript開發工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

